first commit
commit
eb89f036bd
|
|
@ -0,0 +1,43 @@
|
||||||
|
__pycache__
|
||||||
|
*.pyc
|
||||||
|
|
||||||
|
pytrt.cpp
|
||||||
|
build
|
||||||
|
pytrt.*.so
|
||||||
|
|
||||||
|
*.jpg
|
||||||
|
*.png
|
||||||
|
*.mp4
|
||||||
|
*.ts
|
||||||
|
|
||||||
|
googlenet/*.engine
|
||||||
|
googlenet/chobj
|
||||||
|
googlenet/dchobj
|
||||||
|
googlenet/create_engine
|
||||||
|
|
||||||
|
mtcnn/*.engine
|
||||||
|
mtcnn/chobj
|
||||||
|
mtcnn/dchobj
|
||||||
|
mtcnn/create_engines
|
||||||
|
|
||||||
|
ssd/libflattenconcat.so
|
||||||
|
ssd/*.uff
|
||||||
|
ssd/*.pbtxt
|
||||||
|
ssd/*.bin
|
||||||
|
ssd/*.json
|
||||||
|
|
||||||
|
yolo/yolo*.cfg
|
||||||
|
yolo/yolo*.weights
|
||||||
|
yolo/yolo*.onnx
|
||||||
|
yolo/yolo*.trt
|
||||||
|
yolo/*.json
|
||||||
|
yolo/calib_images/
|
||||||
|
yolo/calib_*.bin
|
||||||
|
|
||||||
|
plugins/*.o
|
||||||
|
plugins/*.so
|
||||||
|
|
||||||
|
modnet/venv*
|
||||||
|
modnet/*.ckpt
|
||||||
|
modnet/*.onnx
|
||||||
|
modnet/*.engine
|
||||||
|
|
@ -0,0 +1,3 @@
|
||||||
|
[submodule "modnet/onnx-tensorrt"]
|
||||||
|
path = modnet/onnx-tensorrt
|
||||||
|
url = https://github.com/onnx/onnx-tensorrt.git
|
||||||
|
|
@ -0,0 +1,8 @@
|
||||||
|
# Default ignored files
|
||||||
|
/shelf/
|
||||||
|
/workspace.xml
|
||||||
|
# Editor-based HTTP Client requests
|
||||||
|
/httpRequests/
|
||||||
|
# Datasource local storage ignored files
|
||||||
|
/dataSources/
|
||||||
|
/dataSources.local.xml
|
||||||
|
|
@ -0,0 +1,15 @@
|
||||||
|
<component name="InspectionProjectProfileManager">
|
||||||
|
<profile version="1.0">
|
||||||
|
<option name="myName" value="Project Default" />
|
||||||
|
<inspection_tool class="PyCompatibilityInspection" enabled="true" level="WARNING" enabled_by_default="true">
|
||||||
|
<option name="ourVersions">
|
||||||
|
<value>
|
||||||
|
<list size="2">
|
||||||
|
<item index="0" class="java.lang.String" itemvalue="3.9" />
|
||||||
|
<item index="1" class="java.lang.String" itemvalue="3.11" />
|
||||||
|
</list>
|
||||||
|
</value>
|
||||||
|
</option>
|
||||||
|
</inspection_tool>
|
||||||
|
</profile>
|
||||||
|
</component>
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
<component name="InspectionProjectProfileManager">
|
||||||
|
<settings>
|
||||||
|
<option name="USE_PROJECT_PROFILE" value="false" />
|
||||||
|
<version value="1.0" />
|
||||||
|
</settings>
|
||||||
|
</component>
|
||||||
|
|
@ -0,0 +1,4 @@
|
||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<project version="4">
|
||||||
|
<component name="ProjectRootManager" version="2" project-jdk-name="python39 (2)" project-jdk-type="Python SDK" />
|
||||||
|
</project>
|
||||||
|
|
@ -0,0 +1,8 @@
|
||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<project version="4">
|
||||||
|
<component name="ProjectModuleManager">
|
||||||
|
<modules>
|
||||||
|
<module fileurl="file://$PROJECT_DIR$/.idea/tensorrt_demos-master.iml" filepath="$PROJECT_DIR$/.idea/tensorrt_demos-master.iml" />
|
||||||
|
</modules>
|
||||||
|
</component>
|
||||||
|
</project>
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<module type="PYTHON_MODULE" version="4">
|
||||||
|
<component name="NewModuleRootManager">
|
||||||
|
<content url="file://$MODULE_DIR$">
|
||||||
|
<excludeFolder url="file://$MODULE_DIR$/venv" />
|
||||||
|
</content>
|
||||||
|
<orderEntry type="jdk" jdkName="python39 (2)" jdkType="Python SDK" />
|
||||||
|
<orderEntry type="sourceFolder" forTests="false" />
|
||||||
|
</component>
|
||||||
|
<component name="PyDocumentationSettings">
|
||||||
|
<option name="format" value="PLAIN" />
|
||||||
|
<option name="myDocStringFormat" value="Plain" />
|
||||||
|
</component>
|
||||||
|
</module>
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<project version="4">
|
||||||
|
<component name="VcsDirectoryMappings">
|
||||||
|
<mapping directory="$PROJECT_DIR$" vcs="Git" />
|
||||||
|
</component>
|
||||||
|
</project>
|
||||||
|
|
@ -0,0 +1,21 @@
|
||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2019 JK Jung
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
|
|
@ -0,0 +1,8 @@
|
||||||
|
PYTHON ?= python3
|
||||||
|
|
||||||
|
all:
|
||||||
|
${PYTHON} setup.py build_ext -if
|
||||||
|
rm -rf build
|
||||||
|
|
||||||
|
clean:
|
||||||
|
rm -rf build pytrt.cpp *.so
|
||||||
|
|
@ -0,0 +1,545 @@
|
||||||
|
# tensorrt_demos
|
||||||
|
|
||||||
|
Examples demonstrating how to optimize Caffe/TensorFlow/DarkNet/PyTorch models with TensorRT.
|
||||||
|
|
||||||
|
Highlights:
|
||||||
|
|
||||||
|
* Run an optimized "MODNet" video matting model at ~21 FPS on Jetson Xavier NX.
|
||||||
|
* Run an optimized "yolov4-416" object detector at ~4.6 FPS on Jetson Nano.
|
||||||
|
* Run an optimized "yolov3-416" object detector at ~4.9 FPS on Jetson Nano.
|
||||||
|
* Run an optimized "ssd_mobilenet_v1_coco" object detector ("trt_ssd_async.py") at 27~28 FPS on Jetson Nano.
|
||||||
|
* Run an optimized "MTCNN" face detector at 6~11 FPS on Jetson Nano.
|
||||||
|
* Run an optimized "GoogLeNet" image classifier at "~16 ms per image (inference only)" on Jetson Nano.
|
||||||
|
|
||||||
|
Supported hardware:
|
||||||
|
|
||||||
|
* NVIDIA Jetson
|
||||||
|
- All NVIDIA Jetson Developer Kits, e.g. [Jetson AGX Orin DevKit](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-orin/#advanced-features), [Jetson AGX Xavier DevKit](https://developer.nvidia.com/embedded/jetson-agx-xavier-developer-kit), [Jetson Xavier NX DevKit](https://developer.nvidia.com/embedded/jetson-xavier-nx-devkit), Jetson TX2 DevKit, [Jetson Nano DevKit](https://developer.nvidia.com/embedded/jetson-nano-developer-kit).
|
||||||
|
- Seeed [reComputer J1010](https://www.seeedstudio.com/Jetson-10-1-A0-p-5336.html) with Jetson Nano and [reComputer J2021](https://www.seeedstudio.com/reComputer-J2021-p-5438.html) with Jetson Xavier NX, which are built with NVIDIA Jetson production module and pre-installed with NVIDIA [JetPack SDK](https://developer.nvidia.com/embedded/jetpack).
|
||||||
|
* x86_64 PC with modern NVIDIA GPU(s). Refer to [README_x86.md](https://github.com/jkjung-avt/tensorrt_demos/blob/master/README_x86.md) for more information.
|
||||||
|
|
||||||
|
Table of contents
|
||||||
|
-----------------
|
||||||
|
|
||||||
|
* [Prerequisite](#prerequisite)
|
||||||
|
* [Demo #1: GoogLeNet](#googlenet)
|
||||||
|
* [Demo #2: MTCNN](#mtcnn)
|
||||||
|
* [Demo #3: SSD](#ssd)
|
||||||
|
* [Demo #4: YOLOv3](#yolov3)
|
||||||
|
* [Demo #5: YOLOv4](#yolov4)
|
||||||
|
* [Demo #6: Using INT8 and DLA core](#int8_and_dla)
|
||||||
|
* [Demo #7: MODNet](#modnet)
|
||||||
|
|
||||||
|
<a name="prerequisite"></a>
|
||||||
|
Prerequisite
|
||||||
|
------------
|
||||||
|
|
||||||
|
The code in this repository was tested on Jetson Nano, TX2, and Xavier NX DevKits. In order to run the demos below, first make sure you have the proper version of image (JetPack) installed on the target Jetson system. For example, [Setting up Jetson Nano: The Basics](https://jkjung-avt.github.io/setting-up-nano/) and [Setting up Jetson Xavier NX](https://jkjung-avt.github.io/setting-up-xavier-nx/).
|
||||||
|
|
||||||
|
More specifically, the target Jetson system must have TensorRT libraries installed.
|
||||||
|
|
||||||
|
* Demo #1 and Demo #2: works for TensorRT 3.x+,
|
||||||
|
* Demo #3: requires TensoRT 5.x+,
|
||||||
|
* Demo #4 and Demo #5: requires TensorRT 6.x+.
|
||||||
|
* Demo #6 part 1: INT8 requires TensorRT 6.x+ and only works on GPUs with CUDA compute 6.1+.
|
||||||
|
* Demo #6 part 2: DLA core requires TensorRT 7.x+ (is only tested on Jetson Xavier NX).
|
||||||
|
* Demo #7: requires TensorRT 7.x+.
|
||||||
|
|
||||||
|
You could check which version of TensorRT has been installed on your Jetson system by looking at file names of the libraries. For example, TensorRT v5.1.6 (JetPack-4.2.2) was present on one of my Jetson Nano DevKits.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ ls /usr/lib/aarch64-linux-gnu/libnvinfer.so*
|
||||||
|
/usr/lib/aarch64-linux-gnu/libnvinfer.so
|
||||||
|
/usr/lib/aarch64-linux-gnu/libnvinfer.so.5
|
||||||
|
/usr/lib/aarch64-linux-gnu/libnvinfer.so.5.1.6
|
||||||
|
```
|
||||||
|
|
||||||
|
Furthermore, all demo programs in this repository require "cv2" (OpenCV) module for python3. You could use the "cv2" module which came in the JetPack. Or, if you'd prefer building your own, refer to [Installing OpenCV 3.4.6 on Jetson Nano](https://jkjung-avt.github.io/opencv-on-nano/) for how to build from source and install opencv-3.4.6 on your Jetson system.
|
||||||
|
|
||||||
|
If you plan to run Demo #3 (SSD), you'd also need to have "tensorflow-1.x" installed. You could probably use the [official tensorflow wheels provided by NVIDIA](https://docs.nvidia.com/deeplearning/frameworks/pdf/Install-TensorFlow-Jetson-Platform.pdf), or refer to [Building TensorFlow 1.12.2 on Jetson Nano](https://jkjung-avt.github.io/build-tensorflow-1.12.2/) for how to install tensorflow-1.12.2 on the Jetson system.
|
||||||
|
|
||||||
|
Or if you plan to run Demo #4 and Demo #5, you'd need to have "protobuf" installed. I recommend installing "protobuf-3.8.0" using my [install_protobuf-3.8.0.sh](https://github.com/jkjung-avt/jetson_nano/blob/master/install_protobuf-3.8.0.sh) script. This script would take a couple of hours to finish on a Jetson system. Alternatively, doing `pip3 install` with a recent version of "protobuf" should also work (but might run a little bit slowlier).
|
||||||
|
|
||||||
|
In case you are setting up a Jetson Nano, TX2 or Xavier NX from scratch to run these demos, you could refer to the following blog posts.
|
||||||
|
|
||||||
|
* [JetPack-4.6](https://jkjung-avt.github.io/jetpack-4.6/)
|
||||||
|
* [JetPack-4.5](https://jkjung-avt.github.io/jetpack-4.5/)
|
||||||
|
* [Setting up Jetson Xavier NX](https://jkjung-avt.github.io/setting-up-xavier-nx/)
|
||||||
|
* [JetPack-4.4 for Jetson Nano](https://jkjung-avt.github.io/jetpack-4.4/)
|
||||||
|
* [JetPack-4.3 for Jetson Nano](https://jkjung-avt.github.io/jetpack-4.3/)
|
||||||
|
|
||||||
|
<a name="googlenet"></a>
|
||||||
|
Demo #1: GoogLeNet
|
||||||
|
------------------
|
||||||
|
|
||||||
|
This demo illustrates how to convert a prototxt file and a caffemodel file into a TensorRT engine file, and to classify images with the optimized TensorRT engine.
|
||||||
|
|
||||||
|
Step-by-step:
|
||||||
|
|
||||||
|
1. Clone this repository.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project
|
||||||
|
$ git clone https://github.com/jkjung-avt/tensorrt_demos.git
|
||||||
|
$ cd tensorrt_demos
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Build the TensorRT engine from the pre-trained googlenet (ILSVRC2012) model. Note that I downloaded the pre-trained model files from [BVLC caffe](https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet) and have put a copy of all necessary files in this repository.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/googlenet
|
||||||
|
$ make
|
||||||
|
$ ./create_engine
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Build the Cython code. Install Cython if not previously installed.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ sudo pip3 install Cython
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos
|
||||||
|
$ make
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Run the "trt_googlenet.py" demo program. For example, run the demo using a USB webcam (/dev/video0) as the input.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos
|
||||||
|
$ python3 trt_googlenet.py --usb 0 --width 1280 --height 720
|
||||||
|
```
|
||||||
|
|
||||||
|
Here's a screenshot of the demo (JetPack-4.2.2, i.e. TensorRT 5).
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
5. The demo program supports 5 different image/video inputs. You could do `python3 trt_googlenet.py --help` to read the help messages. Or more specifically, the following inputs could be specified:
|
||||||
|
|
||||||
|
* `--image test_image.jpg`: an image file, e.g. jpg or png.
|
||||||
|
* `--video test_video.mp4`: a video file, e.g. mp4 or ts. An optional `--video_looping` flag could be enabled if needed.
|
||||||
|
* `--usb 0`: USB webcam (/dev/video0).
|
||||||
|
* `--rtsp rtsp://admin:123456@192.168.1.1/live.sdp`: RTSP source, e.g. an IP cam. An optional `--rtsp_latency` argument could be used to adjust the latency setting in this case.
|
||||||
|
* `--onboard 0`: Jetson onboard camera.
|
||||||
|
|
||||||
|
In additional, you could use `--width` and `--height` to specify the desired input image size, and use `--do_resize` to force resizing of image/video file source.
|
||||||
|
|
||||||
|
The `--usb`, `--rtsp` and `--onboard` video sources usually produce image frames at 30 FPS. If the TensorRT engine inference code runs faster than that (which happens easily on a x86_64 PC with a good GPU), one particular image could be inferenced multiple times before the next image frame becomes available. This causes problem in the object detector demos, since the original image could have been altered (bounding boxes drawn) and the altered image is taken for inference again. To cope with this problem, use the optional `--copy_frame` flag to force copying/cloning image frames internally.
|
||||||
|
|
||||||
|
6. Check out my blog post for implementation details:
|
||||||
|
|
||||||
|
* [Running TensorRT Optimized GoogLeNet on Jetson Nano](https://jkjung-avt.github.io/tensorrt-googlenet/)
|
||||||
|
|
||||||
|
<a name="mtcnn"></a>
|
||||||
|
Demo #2: MTCNN
|
||||||
|
--------------
|
||||||
|
|
||||||
|
This demo builds upon the previous one. It converts 3 sets of prototxt and caffemodel files into 3 TensorRT engines, namely the PNet, RNet and ONet. Then it combines the 3 engine files to implement MTCNN, a very good face detector.
|
||||||
|
|
||||||
|
Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", follow these steps:
|
||||||
|
|
||||||
|
1. Build the TensorRT engines from the pre-trained MTCNN model. (Refer to [mtcnn/README.md](https://github.com/jkjung-avt/tensorrt_demos/blob/master/mtcnn/README.md) for more information about the prototxt and caffemodel files.)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/mtcnn
|
||||||
|
$ make
|
||||||
|
$ ./create_engines
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Build the Cython code if it has not been done yet. Refer to step 3 in Demo #1.
|
||||||
|
|
||||||
|
3. Run the "trt_mtcnn.py" demo program. For example, I grabbed from the internet a poster of The Avengers for testing.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos
|
||||||
|
$ python3 trt_mtcnn.py --image ${HOME}/Pictures/avengers.jpg
|
||||||
|
```
|
||||||
|
|
||||||
|
Here's the result (JetPack-4.2.2, i.e. TensorRT 5).
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
4. The "trt_mtcnn.py" demo program could also take various image inputs. Refer to step 5 in Demo #1 for details.
|
||||||
|
|
||||||
|
5. Check out my related blog posts:
|
||||||
|
|
||||||
|
* [TensorRT MTCNN Face Detector](https://jkjung-avt.github.io/tensorrt-mtcnn/)
|
||||||
|
* [Optimizing TensorRT MTCNN](https://jkjung-avt.github.io/optimize-mtcnn/)
|
||||||
|
|
||||||
|
<a name="ssd"></a>
|
||||||
|
Demo #3: SSD
|
||||||
|
------------
|
||||||
|
|
||||||
|
This demo shows how to convert pre-trained tensorflow Single-Shot Multibox Detector (SSD) models through UFF to TensorRT engines, and to do real-time object detection with the TensorRT engines.
|
||||||
|
|
||||||
|
NOTE: This particular demo requires TensorRT "Python API", which is only available in TensorRT 5.x+ on the Jetson systems. In other words, this demo only works on Jetson systems properly set up with JetPack-4.2+, but **not** JetPack-3.x or earlier versions.
|
||||||
|
|
||||||
|
Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", follow these steps:
|
||||||
|
|
||||||
|
1. Install requirements (pycuda, etc.) and build TensorRT engines from the pre-trained SSD models.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/ssd
|
||||||
|
$ ./install.sh
|
||||||
|
$ ./build_engines.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
NOTE: On my Jetson Nano DevKit with TensorRT 5.1.6, the version number of UFF converter was "0.6.3". When I ran "build_engine.py", the UFF library actually printed out: `UFF has been tested with tensorflow 1.12.0. Other versions are not guaranteed to work.` So I would strongly suggest you to use **tensorflow 1.12.x** (or whatever matching version for the UFF library installed on your system) when converting pb to uff.
|
||||||
|
|
||||||
|
2. Run the "trt_ssd.py" demo program. The demo supports 4 models: "ssd_mobilenet_v1_coco", "ssd_mobilenet_v1_egohands", "ssd_mobilenet_v2_coco", or "ssd_mobilenet_v2_egohands". For example, I tested the "ssd_mobilenet_v1_coco" model with the "huskies" picture.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos
|
||||||
|
$ python3 trt_ssd.py --image ${HOME}/project/tf_trt_models/examples/detection/data/huskies.jpg \
|
||||||
|
--model ssd_mobilenet_v1_coco
|
||||||
|
```
|
||||||
|
|
||||||
|
Here's the result (JetPack-4.2.2, i.e. TensorRT 5). Frame rate was good (over 20 FPS).
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
NOTE: When running this demo with TensorRT 6 (JetPack-4.3) on the Jetson Nano, I encountered the following error message which could probably be ignored for now. Quote from [NVIDIA's NVES_R](https://devtalk.nvidia.com/default/topic/1065233/tensorrt/-tensorrt-error-could-not-register-plugin-creator-flattenconcat_trt-in-namespace-/post/5394191/#5394191): `This is a known issue and will be fixed in a future version.`
|
||||||
|
|
||||||
|
```
|
||||||
|
[TensorRT] ERROR: Could not register plugin creator: FlattenConcat_TRT in namespace
|
||||||
|
```
|
||||||
|
|
||||||
|
I also tested the "ssd_mobilenet_v1_egohands" (hand detector) model with a video clip from YouTube, and got the following result. Again, frame rate was pretty good. But the detection didn't seem very accurate though :-(
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ python3 trt_ssd.py --video ${HOME}/Videos/Nonverbal_Communication.mp4 \
|
||||||
|
--model ssd_mobilenet_v1_egohands
|
||||||
|
```
|
||||||
|
|
||||||
|
(Click on the image below to see the whole video clip...)
|
||||||
|
|
||||||
|
[](https://youtu.be/3ieN5BBdDF0)
|
||||||
|
|
||||||
|
3. The "trt_ssd.py" demo program could also take various image inputs. Refer to step 5 in Demo #1 again.
|
||||||
|
|
||||||
|
4. Referring to this comment, ["#TODO enable video pipeline"](https://github.com/AastaNV/TRT_object_detection/blob/master/main.py#L78), in the original TRT_object_detection code, I did implement an "async" version of ssd detection code to do just that. When I tested "ssd_mobilenet_v1_coco" on the same huskies image with the async demo program on the Jetson Nano DevKit, frame rate improved 3~4 FPS.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos
|
||||||
|
$ python3 trt_ssd_async.py --image ${HOME}/project/tf_trt_models/examples/detection/data/huskies.jpg \
|
||||||
|
--model ssd_mobilenet_v1_coco
|
||||||
|
```
|
||||||
|
|
||||||
|
5. To verify accuracy (mAP) of the optimized TensorRT engines and make sure they do not degrade too much (due to reduced floating-point precision of "FP16") from the original TensorFlow frozen inference graphs, you could prepare validation data and run "eval_ssd.py". Refer to [README_mAP.md](README_mAP.md) for details.
|
||||||
|
|
||||||
|
I compared mAP of the TensorRT engine and the original tensorflow model for both "ssd_mobilenet_v1_coco" and "ssd_mobilenet_v2_coco" using COCO "val2017" data. The results were good. In both cases, mAP of the optimized TensorRT engine matched the original tensorflow model. The FPS (frames per second) numbers in the table were measured using "trt_ssd_async.py" on my Jetson Nano DevKit with JetPack-4.3.
|
||||||
|
|
||||||
|
| TensorRT engine | mAP @<br>IoU=0.5:0.95 | mAP @<br>IoU=0.5 | FPS on Nano |
|
||||||
|
|:------------------------|:---------------------:|:------------------:|:-----------:|
|
||||||
|
| mobilenet_v1 TF | 0.232 | 0.351 | -- |
|
||||||
|
| mobilenet_v1 TRT (FP16) | 0.232 | 0.351 | 27.7 |
|
||||||
|
| mobilenet_v2 TF | 0.248 | 0.375 | -- |
|
||||||
|
| mobilenet_v2 TRT (FP16) | 0.248 | 0.375 | 22.7 |
|
||||||
|
|
||||||
|
6. Check out my blog posts for implementation details:
|
||||||
|
|
||||||
|
* [TensorRT UFF SSD](https://jkjung-avt.github.io/tensorrt-ssd/)
|
||||||
|
* [Speeding Up TensorRT UFF SSD](https://jkjung-avt.github.io/speed-up-trt-ssd/)
|
||||||
|
* [Verifying mAP of TensorRT Optimized SSD and YOLOv3 Models](https://jkjung-avt.github.io/trt-detection-map/)
|
||||||
|
* Or if you'd like to learn how to train your own custom object detectors which could be easily converted to TensorRT engines and inferenced with "trt_ssd.py" and "trt_ssd_async.py": [Training a Hand Detector with TensorFlow Object Detection API](https://jkjung-avt.github.io/hand-detection-tutorial/)
|
||||||
|
|
||||||
|
<a name="yolov3"></a>
|
||||||
|
Demo #4: YOLOv3
|
||||||
|
---------------
|
||||||
|
|
||||||
|
(Merged with Demo #5: YOLOv4...)
|
||||||
|
|
||||||
|
<a name="yolov4"></a>
|
||||||
|
Demo #5: YOLOv4
|
||||||
|
---------------
|
||||||
|
|
||||||
|
Along the same line as Demo #3, these 2 demos showcase how to convert pre-trained yolov3 and yolov4 models through ONNX to TensorRT engines. The code for these 2 demos has gone through some significant changes. More specifically, I have recently updated the implementation with a "yolo_layer" plugin to speed up inference time of the yolov3/yolov4 models.
|
||||||
|
|
||||||
|
My current "yolo_layer" plugin implementation is based on TensorRT's [IPluginV2IOExt](https://docs.nvidia.com/deeplearning/tensorrt/api/c_api/classnvinfer1_1_1_i_plugin_v2_i_o_ext.html). It only works for **TensorRT 6+**. I'm thinking about updating the code to support TensorRT 5 if I have time late on.
|
||||||
|
|
||||||
|
I developed my "yolo_layer" plugin by referencing similar plugin code by [wang-xinyu](https://github.com/wang-xinyu/tensorrtx/tree/master/yolov4) and [dongfangduoshou123](https://github.com/dongfangduoshou123/YoloV3-TensorRT/blob/master/seralizeEngineFromPythonAPI.py). So big thanks to both of them.
|
||||||
|
|
||||||
|
Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", follow these steps:
|
||||||
|
|
||||||
|
1. Install "pycuda".
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/yolo
|
||||||
|
$ ./install_pycuda.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Install **version "1.9.0"** of python3 **"onnx"** module. Note that the "onnx" module would depend on "protobuf" as stated in the [Prerequisite](#prerequisite) section.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ sudo pip3 install onnx==1.9.0
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Go to the "plugins/" subdirectory and build the "yolo_layer" plugin. When done, a "libyolo_layer.so" would be generated.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/plugins
|
||||||
|
$ make
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Download the pre-trained yolov3/yolov4 COCO models and convert the targeted model to ONNX and then to TensorRT engine. I use "yolov4-416" as example below. (Supported models: "yolov3-tiny-288", "yolov3-tiny-416", "yolov3-288", "yolov3-416", "yolov3-608", "yolov3-spp-288", "yolov3-spp-416", "yolov3-spp-608", "yolov4-tiny-288", "yolov4-tiny-416", "yolov4-288", "yolov4-416", "yolov4-608", "yolov4-csp-256", "yolov4-csp-512", "yolov4x-mish-320", "yolov4x-mish-640", and [custom models](https://jkjung-avt.github.io/trt-yolo-custom-updated/) such as "yolov4-416x256".)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/yolo
|
||||||
|
$ ./download_yolo.sh
|
||||||
|
$ python3 yolo_to_onnx.py -m yolov4-416
|
||||||
|
$ python3 onnx_to_tensorrt.py -m yolov4-416
|
||||||
|
```
|
||||||
|
|
||||||
|
The last step ("onnx_to_tensorrt.py") takes a little bit more than half an hour to complete on my Jetson Nano DevKit. When that is done, the optimized TensorRT engine would be saved as "yolov4-416.trt".
|
||||||
|
|
||||||
|
In case "onnx_to_tensorrt.py" fails (process "Killed" by Linux kernel), it could likely be that the Jetson platform runs out of memory during conversion of the TensorRT engine. This problem might be solved by adding a larger swap file to the system. Reference: [Process killed in onnx_to_tensorrt.py Demo#5](https://github.com/jkjung-avt/tensorrt_demos/issues/344).
|
||||||
|
|
||||||
|
5. Test the TensorRT "yolov4-416" engine with the "dog.jpg" image.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos
|
||||||
|
$ wget https://raw.githubusercontent.com/pjreddie/darknet/master/data/dog.jpg -O ${HOME}/Pictures/dog.jpg
|
||||||
|
$ python3 trt_yolo.py --image ${HOME}/Pictures/dog.jpg \
|
||||||
|
-m yolov4-416
|
||||||
|
```
|
||||||
|
|
||||||
|
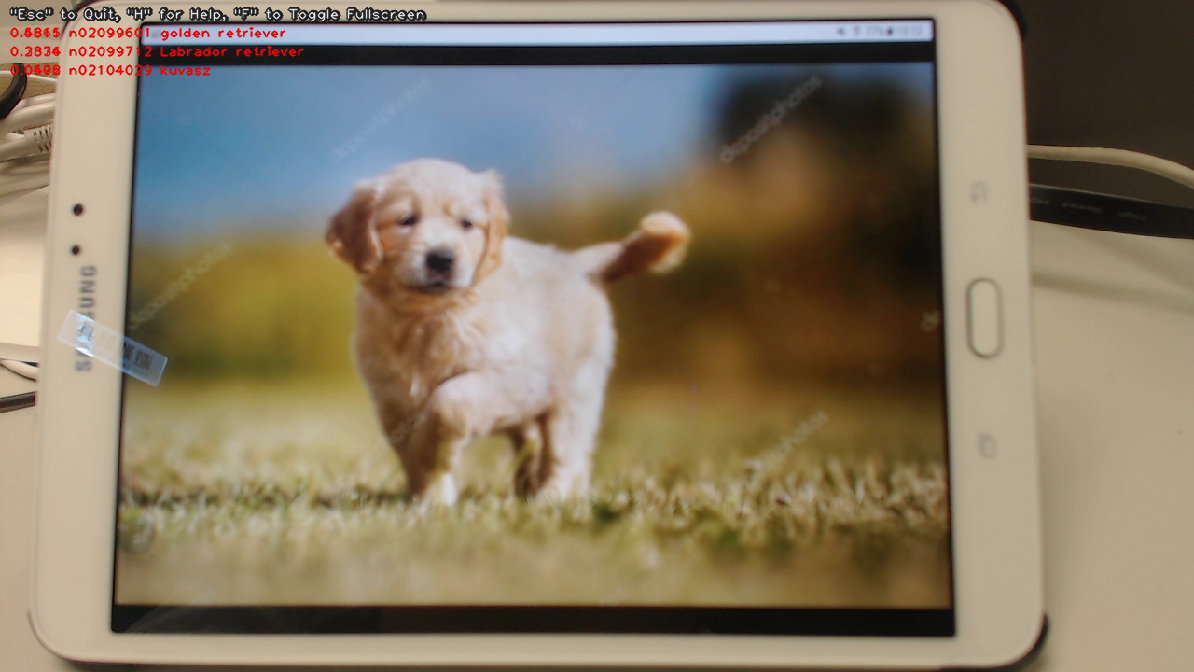
This is a screenshot of the demo against JetPack-4.4, i.e. TensorRT 7.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
6. The "trt_yolo.py" demo program could also take various image inputs. Refer to step 5 in Demo #1 again.
|
||||||
|
|
||||||
|
For example, I tested my own custom trained ["yolov4-crowdhuman-416x416"](https://github.com/jkjung-avt/yolov4_crowdhuman) TensorRT engine with the "Avengers: Infinity War" movie trailer:
|
||||||
|
|
||||||
|
[](https://youtu.be/7Qr_Fq18FgM)
|
||||||
|
|
||||||
|
7. (Optional) Test other models than "yolov4-416".
|
||||||
|
|
||||||
|
8. (Optional) If you would like to stream TensorRT YOLO detection output over the network and view the results on a remote host, check out my [trt_yolo_mjpeg.py example](https://github.com/jkjung-avt/tensorrt_demos/issues/226).
|
||||||
|
|
||||||
|
9. Similar to step 5 of Demo #3, I created an "eval_yolo.py" for evaluating mAP of the TensorRT yolov3/yolov4 engines. Refer to [README_mAP.md](README_mAP.md) for details.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ python3 eval_yolo.py -m yolov3-tiny-288
|
||||||
|
$ python3 eval_yolo.py -m yolov4-tiny-416
|
||||||
|
......
|
||||||
|
$ python3 eval_yolo.py -m yolov4-608
|
||||||
|
$ python3 eval_yolo.py -l -m yolov4-csp-256
|
||||||
|
......
|
||||||
|
$ python3 eval_yolo.py -l -m yolov4x-mish-640
|
||||||
|
```
|
||||||
|
|
||||||
|
I evaluated all these TensorRT yolov3/yolov4 engines with COCO "val2017" data and got the following results. I also checked the FPS (frames per second) numbers on my Jetson Nano DevKit with JetPack-4.4 (TensorRT 7).
|
||||||
|
|
||||||
|
| TensorRT engine | mAP @<br>IoU=0.5:0.95 | mAP @<br>IoU=0.5 | FPS on Nano |
|
||||||
|
|:------------------------|:---------------------:|:------------------:|:-----------:|
|
||||||
|
| yolov3-tiny-288 (FP16) | 0.077 | 0.158 | 35.8 |
|
||||||
|
| yolov3-tiny-416 (FP16) | 0.096 | 0.202 | 25.5 |
|
||||||
|
| yolov3-288 (FP16) | 0.331 | 0.601 | 8.16 |
|
||||||
|
| yolov3-416 (FP16) | 0.373 | 0.664 | 4.93 |
|
||||||
|
| yolov3-608 (FP16) | 0.376 | 0.665 | 2.53 |
|
||||||
|
| yolov3-spp-288 (FP16) | 0.339 | 0.594 | 8.16 |
|
||||||
|
| yolov3-spp-416 (FP16) | 0.391 | 0.664 | 4.82 |
|
||||||
|
| yolov3-spp-608 (FP16) | 0.410 | 0.685 | 2.49 |
|
||||||
|
| yolov4-tiny-288 (FP16) | 0.179 | 0.344 | 36.6 |
|
||||||
|
| yolov4-tiny-416 (FP16) | 0.196 | 0.387 | 25.5 |
|
||||||
|
| yolov4-288 (FP16) | 0.376 | 0.591 | 7.93 |
|
||||||
|
| yolov4-416 (FP16) | 0.459 | 0.700 | 4.62 |
|
||||||
|
| yolov4-608 (FP16) | 0.488 | 0.736 | 2.35 |
|
||||||
|
| yolov4-csp-256 (FP16) | 0.336 | 0.502 | 12.8 |
|
||||||
|
| yolov4-csp-512 (FP16) | 0.436 | 0.630 | 4.26 |
|
||||||
|
| yolov4x-mish-320 (FP16) | 0.400 | 0.581 | 4.79 |
|
||||||
|
| yolov4x-mish-640 (FP16) | 0.470 | 0.668 | 1.46 |
|
||||||
|
|
||||||
|
10. Check out my blog posts for implementation details:
|
||||||
|
|
||||||
|
* [TensorRT ONNX YOLOv3](https://jkjung-avt.github.io/tensorrt-yolov3/)
|
||||||
|
* [TensorRT YOLOv4](https://jkjung-avt.github.io/tensorrt-yolov4/)
|
||||||
|
* [Verifying mAP of TensorRT Optimized SSD and YOLOv3 Models](https://jkjung-avt.github.io/trt-detection-map/)
|
||||||
|
* For training your own custom yolov4 model: [Custom YOLOv4 Model on Google Colab](https://jkjung-avt.github.io/colab-yolov4/)
|
||||||
|
* For adapting the code to your own custom trained yolov3/yolov4 models: [TensorRT YOLO For Custom Trained Models (Updated)](https://jkjung-avt.github.io/trt-yolo-custom-updated/)
|
||||||
|
|
||||||
|
<a name="int8_and_dla"></a>
|
||||||
|
Demo #6: Using INT8 and DLA core
|
||||||
|
--------------------------------
|
||||||
|
|
||||||
|
NVIDIA introduced [INT8 TensorRT inferencing](https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf) since CUDA compute 6.1+. For the embedded Jetson product line, INT8 is available on Jetson AGX Xavier and Xavier NX. In addition, NVIDIA further introduced [Deep Learning Accelerator (NVDLA)](http://nvdla.org/) on Jetson Xavier NX. I tested both features on my Jetson Xavier NX DevKit, and shared the source code in this repo.
|
||||||
|
|
||||||
|
Please make sure you have gone through the steps of [Demo #5](#yolov4) and are able to run TensorRT yolov3/yolov4 engines successfully, before following along:
|
||||||
|
|
||||||
|
1. In order to use INT8 TensorRT, you'll first have to prepare some images for "calibration". These images for calibration should cover all distributions of possible image inputs at inference time. According to [official documentation](https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#optimizing_int8_c), 500 of such images are suggested by NVIDIA. As an example, I used 1,000 images from the COCO "val2017" dataset for that purpose. Note that I've previously downloaded the "val2017" images for [mAP evaluation](README_mAP.md).
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/yolo
|
||||||
|
$ mkdir calib_images
|
||||||
|
### randomly pick and copy over 1,000 images from "val207"
|
||||||
|
$ for jpg in $(ls -1 ${HOME}/data/coco/images/val2017/*.jpg | sort -R | head -1000); do \
|
||||||
|
cp ${HOME}/data/coco/images/val2017/${jpg} calib_images/; \
|
||||||
|
done
|
||||||
|
```
|
||||||
|
|
||||||
|
When this is done, the 1,000 images for calibration should be present in the "${HOME}/project/tensorrt_demos/yolo/calib_images/" directory.
|
||||||
|
|
||||||
|
2. Build the INT8 TensorRT engine. I use the "yolov3-608" model in the example commands below. (I've also created a "build_int8_engines.sh" script to facilitate building multiple INT8 engines at once.) Note that building the INT8 TensorRT engine on Jetson Xavier NX takes quite long. By enabling verbose logging ("-v"), you would be able to monitor the progress more closely.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ln -s yolov3-608.cfg yolov3-int8-608.cfg
|
||||||
|
$ ln -s yolov3-608.onnx yolov3-int8-608.onnx
|
||||||
|
$ python3 onnx_to_tensorrt.py -v --int8 -m yolov3-int8-608
|
||||||
|
```
|
||||||
|
|
||||||
|
3. (Optional) Build the TensorRT engines for the DLA cores. I use the "yolov3-608" model as example again. (I've also created a "build_dla_engines.sh" script for building multiple DLA engines at once.)
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ln -s yolov3-608.cfg yolov3-dla0-608.cfg
|
||||||
|
$ ln -s yolov3-608.onnx yolov3-dla0-608.onnx
|
||||||
|
$ python3 onnx_to_tensorrt.py -v --int8 --dla_core 0 -m yolov3-dla0-608
|
||||||
|
$ ln -s yolov3-608.cfg yolov3-dla1-608.cfg
|
||||||
|
$ ln -s yolov3-608.onnx yolov3-dla1-608.onnx
|
||||||
|
$ python3 onnx_to_tensorrt.py -v --int8 --dla_core 1 -m yolov3-int8-608
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Test the INT8 TensorRT engine with the "dog.jpg" image.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos
|
||||||
|
$ python3 trt_yolo.py --image ${HOME}/Pictures/dog.jpg \
|
||||||
|
-m yolov3-int8-608
|
||||||
|
```
|
||||||
|
|
||||||
|
(Optional) Also test the DLA0 and DLA1 TensorRT engines.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ python3 trt_yolo.py --image ${HOME}/Pictures/dog.jpg \
|
||||||
|
-m yolov3-dla0-608
|
||||||
|
$ python3 trt_yolo.py --image ${HOME}/Pictures/dog.jpg \
|
||||||
|
-m yolov3-dla1-608
|
||||||
|
```
|
||||||
|
|
||||||
|
5. Evaluate mAP of the INT8 and DLA TensorRT engines.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ python3 eval_yolo.py -m yolov3-int8-608
|
||||||
|
$ python3 eval_yolo.py -m yolov3-dla0-608
|
||||||
|
$ python3 eval_yolo.py -m yolov3-dla1-608
|
||||||
|
```
|
||||||
|
|
||||||
|
6. I tested the 5 original yolov3/yolov4 models on my Jetson Xavier NX DevKit with JetPack-4.4 (TensorRT 7.1.3.4). Here are the results.
|
||||||
|
|
||||||
|
The following **FPS numbers** were measured under "15W 6CORE" mode, with CPU/GPU clocks set to maximum value (`sudo jetson_clocks`).
|
||||||
|
|
||||||
|
| TensorRT engine | FP16 | INT8 | DLA0 | DLA1 |
|
||||||
|
|:-----------------|:--------:|:--------:|:--------:|:--------:|
|
||||||
|
| yolov3-tiny-416 | 58 | 65 | 42 | 42 |
|
||||||
|
| yolov3-608 | 15.2 | 23.1 | 14.9 | 14.9 |
|
||||||
|
| yolov3-spp-608 | 15.0 | 22.7 | 14.7 | 14.7 |
|
||||||
|
| yolov4-tiny-416 | 57 | 60 | X | X |
|
||||||
|
| yolov4-608 | 13.8 | 20.5 | 8.97 | 8.97 |
|
||||||
|
| yolov4-csp-512 | 19.8 | 27.8 | -- | -- |
|
||||||
|
| yolov4x-mish-640 | 9.01 | 14.1 | -- | -- |
|
||||||
|
|
||||||
|
And the following are **"mAP@IoU=0.5:0.95" / "mAP@IoU=0.5"** of those TensorRT engines.
|
||||||
|
|
||||||
|
| TensorRT engine | FP16 | INT8 | DLA0 | DLA1 |
|
||||||
|
|:-----------------|:---------------:|:---------------:|:---------------:|:---------------:|
|
||||||
|
| yolov3-tiny-416 | 0.096 / 0.202 | 0.094 / 0.198 | 0.096 / 0.199 | 0.096 / 0.199 |
|
||||||
|
| yolov3-608 | 0.376 / 0.665 | 0.378 / 0.670 | 0.378 / 0.670 | 0.378 / 0.670 |
|
||||||
|
| yolov3-spp-608 | 0.410 / 0.685 | 0.407 / 0.681 | 0.404 / 0.676 | 0.404 / 0.676 |
|
||||||
|
| yolov4-tiny-416 | 0.196 / 0.387 | 0.190 / 0.376 | X | X |
|
||||||
|
| yolov4-608 | 0.488 / 0.736 | *0.317 / 0.507* | 0.474 / 0.727 | 0.473 / 0.726 |
|
||||||
|
| yolov4-csp-512 | 0.436 / 0.630 | 0.391 / 0.577 | -- | -- |
|
||||||
|
| yolov4x-mish-640 | 0.470 / 0.668 | 0.434 / 0.631 | -- | -- |
|
||||||
|
|
||||||
|
7. Issues:
|
||||||
|
|
||||||
|
* For some reason, I'm not able to build DLA TensorRT engines for the "yolov4-tiny-416" model. I have [reported the issue](https://forums.developer.nvidia.com/t/problem-building-tensorrt-engines-for-dla-core/155749) to NVIDIA.
|
||||||
|
* There is no method in TensorRT 7.1 Python API to specifically set DLA core at inference time. I also [reported this issue](https://forums.developer.nvidia.com/t/no-method-in-tensorrt-python-api-for-setting-dla-core-for-inference/155874) to NVIDIA. When testing, I simply deserialize the TensorRT engines onto Jetson Xavier NX. I'm not 100% sure whether the engine is really executed on DLA core 0 or DLA core 1.
|
||||||
|
* mAP of the INT8 TensorRT engine of the "yolov4-608" model is not good. Originally, I thought it was [an issue of TensorRT library's handling of "Concat" nodes](https://forums.developer.nvidia.com/t/concat-in-caffe-parser-is-wrong-when-working-with-int8-calibration/142639/3?u=jkjung13). But after some more investigation, I saw that was not the case. Currently, I'm still not sure what the problem is...
|
||||||
|
|
||||||
|
<a name="modnet"></a>
|
||||||
|
Demo #7: MODNet
|
||||||
|
---------------
|
||||||
|
|
||||||
|
This demo illustrates the use of TensorRT to optimize an image segmentation model. More specifically, I build and test a TensorRT engine from the pre-trained MODNet to do real-time image/video "matting". The PyTorch MODNet model comes from [ZHKKKe/MODNet](https://github.com/ZHKKKe/MODNet). Note that, as stated by the original auther, this pre-trained model is under [Creative Commons Attribution NonCommercial ShareAlike 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode) license. Thanks to [ZHKKKe](https://github.com/ZHKKKe) for sharing the model and inference code.
|
||||||
|
|
||||||
|
This MODNet model contains [InstanceNorm2d](https://pytorch.org/docs/stable/generated/torch.nn.InstanceNorm2d.html) layers, which are only supported in recent versions of TensorRT. So far I have only tested the code with TensorRT 7.1 and 7.2. I don't guarantee the code would work for older versions of TensorRT.
|
||||||
|
|
||||||
|
To make the demo simpler to follow, I have already converted the PyTorch MODNet model to ONNX ("modnet/modnet.onnx"). If you'd like to do the PyTorch-to-ONNX conversion by yourself, you could refer to [modnet/README.md](https://github.com/jkjung-avt/tensorrt_demos/blob/master/modnet/README.md).
|
||||||
|
|
||||||
|
Here is the step-by-step guide for the demo:
|
||||||
|
|
||||||
|
1. Install "pycuda" in case you haven't done so before.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/modnet
|
||||||
|
$ ./install_pycuda.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Build TensorRT engine from "modnet/modnet.onnx".
|
||||||
|
|
||||||
|
This step would be easy if you are using **TensorRT 7.2 or later**. Just use the "modnet/onnx_to_tensorrt.py" script: (You could optionally use "-v" command-line option to see verbose logs.)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ python3 onnx_to_tensorrt.py modnet.onnx modnet.engine
|
||||||
|
```
|
||||||
|
|
||||||
|
When "onnx_to_tensorrt.py" finishes, the "modnet.engine" file should be generated. And you could go to step #3.
|
||||||
|
|
||||||
|
In case you are using **TensorRT 7.1** (JetPack-4.5 or JetPack-4.4), "modnet/onnx_to_tensorrt.py" wouldn't work due to this error (which has been fixed in TensorRT 7.2): [UNSUPPORTED_NODE: Assertion failed: !isDynamic(tensorPtr->getDimensions()) && "InstanceNormalization does not support dynamic inputs!"](https://github.com/onnx/onnx-tensorrt/issues/374). I worked around the problem by building [onnx-tensorrt](https://github.com/onnx/onnx-tensorrt) by myself. Here's how you could do it too.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/modnet
|
||||||
|
### check out the "onnx-tensorrt" submodule
|
||||||
|
$ git submodule update --init --recursive
|
||||||
|
### patch CMakeLists.txt
|
||||||
|
$ sed -i '21s/cmake_minimum_required(VERSION 3.13)/#cmake_minimum_required(VERSION 3.13)/' \
|
||||||
|
onnx-tensorrt/CMakeLists.txt
|
||||||
|
### build onnx-tensorrt
|
||||||
|
$ mkdir -p onnx-tensorrt/build
|
||||||
|
$ cd onnx-tensorrt/build
|
||||||
|
$ cmake -DCMAKE_CXX_FLAGS=-I/usr/local/cuda/targets/aarch64-linux/include \
|
||||||
|
-DONNX_NAMESPACE=onnx2trt_onnx ..
|
||||||
|
$ make -j4
|
||||||
|
### finally, we could build the TensorRT (FP16) engine
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/modnet
|
||||||
|
$ LD_LIBRARY_PATH=$(pwd)/onnx-tensorrt/build \
|
||||||
|
onnx-tensorrt/build/onnx2trt modnet.onnx -o modnet.engine \
|
||||||
|
-d 16 -v
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Test the TensorRT MODNet engine with "modnet/image.jpg".
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos
|
||||||
|
$ python3 trt_modnet.py --image modnet/image.jpg
|
||||||
|
```
|
||||||
|
|
||||||
|
You could see the matted image as below. Note that I get ~21 FPS when running the code on Jetson Xavier NX with JetPack-4.5.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
4. The "trt_modnet.py" demo program could also take various image inputs. Refer to step 5 in Demo #1 again. (For example, the "--usb" command-line option would be useful.)
|
||||||
|
|
||||||
|
5. Instead of a boring black background, you could use the "--background" option to specify an alternative background. The background could be either a still image or a video file. Furthermore, you could also use the "--create_video" option to save the matted outputs as a video file.
|
||||||
|
|
||||||
|
For example, I took a [Chou, Tzu-Yu video](https://youtu.be/L6B9BObaIRA) and a [beach video](https://youtu.be/LdsTydS4eww), and created a blended video like this:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos
|
||||||
|
$ python3 trt_modnet.py --video Tzu-Yu.mp4 \
|
||||||
|
--background beach.mp4 \
|
||||||
|
--demo_mode \
|
||||||
|
--create_video output
|
||||||
|
```
|
||||||
|
|
||||||
|
The result would be saved as "output.ts" on Jetson Xavier NX (or "output.mp4" on x86_64 PC).
|
||||||
|
|
||||||
|
[](https://youtu.be/SIoJAI1bMyc)
|
||||||
|
|
||||||
|
Licenses
|
||||||
|
--------
|
||||||
|
|
||||||
|
1. I referenced source code of [NVIDIA/TensorRT](https://github.com/NVIDIA/TensorRT) samples to develop most of the demos in this repository. Those NVIDIA samples are under [Apache License 2.0](https://github.com/NVIDIA/TensorRT/blob/master/LICENSE).
|
||||||
|
2. [GoogLeNet](https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet): "This model is released for unrestricted use."
|
||||||
|
3. [MTCNN](https://github.com/PKUZHOU/MTCNN_FaceDetection_TensorRT): license not specified. Note [the original MTCNN](https://github.com/kpzhang93/MTCNN_face_detection_alignment) is under [MIT License](https://github.com/kpzhang93/MTCNN_face_detection_alignment/blob/master/LICENSE).
|
||||||
|
4. [TensorFlow Object Detection Models](https://github.com/tensorflow/models/tree/master/research/object_detection): [Apache License 2.0](https://github.com/tensorflow/models/blob/master/LICENSE).
|
||||||
|
5. YOLOv3/YOLOv4 models ([DarkNet](https://github.com/AlexeyAB/darknet)): [YOLO LICENSE](https://github.com/AlexeyAB/darknet/blob/master/LICENSE).
|
||||||
|
6. [MODNet](https://github.com/ZHKKKe/MODNet): [Creative Commons Attribution NonCommercial ShareAlike 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode) license.
|
||||||
|
7. For the rest of the code (developed by jkjung-avt and other contributors): [MIT License](https://github.com/jkjung-avt/tensorrt_demos/blob/master/LICENSE).
|
||||||
|
|
@ -0,0 +1,122 @@
|
||||||
|
# Instructions for evaluating accuracy (mAP) of SSD models
|
||||||
|
|
||||||
|
Preparation
|
||||||
|
-----------
|
||||||
|
|
||||||
|
1. Prepare image data and label ('bbox') file for the evaluation. I used COCO [2017 Val images (5K/1GB)](http://images.cocodataset.org/zips/val2017.zip) and [2017 Train/Val annotations (241MB)](http://images.cocodataset.org/annotations/annotations_trainval2017.zip). You could try to use your own dataset for evaluation, but you'd need to convert the labels into [COCO Object Detection ('bbox') format](http://cocodataset.org/#format-data) if you want to use code in this repository without modifications.
|
||||||
|
|
||||||
|
More specifically, I downloaded the images and labels, and unzipped files into `${HOME}/data/coco/`.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ wget http://images.cocodataset.org/zips/val2017.zip \
|
||||||
|
-O ${HOME}/Downloads/val2017.zip
|
||||||
|
$ wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip \
|
||||||
|
-O ${HOME}/Downloads/annotations_trainval2017.zip
|
||||||
|
$ mkdir -p ${HOME}/data/coco/images
|
||||||
|
$ cd ${HOME}/data/coco/images
|
||||||
|
$ unzip ${HOME}/Downloads/val2017.zip
|
||||||
|
$ cd ${HOME}/data/coco
|
||||||
|
$ unzip ${HOME}/Downloads/annotations_trainval2017.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
Later on I would be using the following (unzipped) image and annotation files for the evaluation.
|
||||||
|
|
||||||
|
```
|
||||||
|
${HOME}/data/coco/images/val2017/*.jpg
|
||||||
|
${HOME}/data/coco/annotations/instances_val2017.json
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Install 'pycocotools'. The easiest way is to use `pip3 install`.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ sudo pip3 install pycocotools
|
||||||
|
```
|
||||||
|
|
||||||
|
Alternatively, you could build and install it from [source](https://github.com/cocodataset/cocoapi).
|
||||||
|
|
||||||
|
3. Install additional requirements.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ sudo pip3 install progressbar2
|
||||||
|
```
|
||||||
|
|
||||||
|
Evaluation
|
||||||
|
----------
|
||||||
|
|
||||||
|
I've created the [eval_ssd.py](eval_ssd.py) script to do the [mAP evaluation](http://cocodataset.org/#detection-eval).
|
||||||
|
|
||||||
|
```
|
||||||
|
usage: eval_ssd.py [-h] [--mode {tf,trt}] [--imgs_dir IMGS_DIR]
|
||||||
|
[--annotations ANNOTATIONS]
|
||||||
|
{ssd_mobilenet_v1_coco,ssd_mobilenet_v2_coco}
|
||||||
|
```
|
||||||
|
|
||||||
|
The script takes 1 mandatory argument: either 'ssd_mobilenet_v1_coco' or 'ssd_mobilenet_v2_coco'. In addition, it accepts the following options:
|
||||||
|
|
||||||
|
* `--mode {tf,trt}`: to evaluate either the unoptimized TensorFlow frozen inference graph (tf) or the optimized TensorRT engine (trt).
|
||||||
|
* `--imgs_dir IMGS_DIR`: to specify an alternative directory for reading image files.
|
||||||
|
* `--annotations ANNOTATIONS`: to specify an alternative annotation/label file.
|
||||||
|
|
||||||
|
For example, I evaluated both 'ssd_mobilenet_v1_coco' and 'ssd_mobilenet_v2_coco' TensorRT engines on my x86_64 PC and got these results. The overall mAP values are `0.230` and `0.246`, respectively.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ python3 eval_ssd.py --mode trt ssd_mobilenet_v1_coco
|
||||||
|
......
|
||||||
|
100% (5000 of 5000) |####################| Elapsed Time: 0:00:26 Time: 0:00:26
|
||||||
|
loading annotations into memory...
|
||||||
|
Done (t=0.36s)
|
||||||
|
creating index...
|
||||||
|
index created!
|
||||||
|
Loading and preparing results...
|
||||||
|
DONE (t=0.11s)
|
||||||
|
creating index...
|
||||||
|
index created!
|
||||||
|
Running per image evaluation...
|
||||||
|
Evaluate annotation type *bbox*
|
||||||
|
DONE (t=8.89s).
|
||||||
|
Accumulating evaluation results...
|
||||||
|
DONE (t=1.37s).
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.232
|
||||||
|
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.351
|
||||||
|
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.254
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.018
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.166
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.530
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.209
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.264
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.264
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.022
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.191
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.606
|
||||||
|
None
|
||||||
|
$
|
||||||
|
$ python3 eval_ssd.py --mode trt ssd_mobilenet_v2_coco
|
||||||
|
......
|
||||||
|
100% (5000 of 5000) |####################| Elapsed Time: 0:00:29 Time: 0:00:29
|
||||||
|
loading annotations into memory...
|
||||||
|
Done (t=0.37s)
|
||||||
|
creating index...
|
||||||
|
index created!
|
||||||
|
Loading and preparing results...
|
||||||
|
DONE (t=0.12s)
|
||||||
|
creating index...
|
||||||
|
index created!
|
||||||
|
Running per image evaluation...
|
||||||
|
Evaluate annotation type *bbox*
|
||||||
|
DONE (t=9.47s).
|
||||||
|
Accumulating evaluation results...
|
||||||
|
DONE (t=1.42s).
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.248
|
||||||
|
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.375
|
||||||
|
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.273
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.021
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.176
|
||||||
|
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.573
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.221
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.278
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.279
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.027
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.202
|
||||||
|
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.643
|
||||||
|
None
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,123 @@
|
||||||
|
# Instructions for x86_64 platforms
|
||||||
|
|
||||||
|
All demos in this repository, with minor tweaks, should also work on x86_64 platforms with NVIDIA GPU(s). Here is a list of required modifications if you'd like to run the demos on an x86_64 PC/server.
|
||||||
|
|
||||||
|
|
||||||
|
Make sure you have TensorRT installed properly on your x86_64 system. You could follow NVIDIA's official [Installation Guide :: NVIDIA Deep Learning TensorRT](https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html) documentation.
|
||||||
|
|
||||||
|
Demo #1 (GoogLeNet) and #2 (MTCNN)
|
||||||
|
----------------------------------
|
||||||
|
|
||||||
|
1. Set `TENSORRT_INCS` and `TENSORRT_LIBS` in "common/Makefile.config" correctly for your x86_64 system. More specifically, you should find the following lines in "common/Mafefile.config" and modify them if needed.
|
||||||
|
|
||||||
|
```
|
||||||
|
# These are the directories where I installed TensorRT on my x86_64 PC.
|
||||||
|
TENSORRT_INCS=-I"/usr/local/TensorRT-7.1.3.4/include"
|
||||||
|
TENSORRT_LIBS=-L"/usr/local/TensorRT-7.1.3.4/lib"
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Set `library_dirs` and `include_dirs` in "setup.py". More specifically, you should check and make sure the 2 TensorRT path lines are correct.
|
||||||
|
|
||||||
|
```python
|
||||||
|
library_dirs = [
|
||||||
|
'/usr/local/cuda/lib64',
|
||||||
|
'/usr/local/TensorRT-7.1.3.4/lib', # for my x86_64 PC
|
||||||
|
'/usr/local/lib',
|
||||||
|
]
|
||||||
|
......
|
||||||
|
include_dirs = [
|
||||||
|
# in case the following numpy include path does not work, you
|
||||||
|
# could replace it manually with, say,
|
||||||
|
# '-I/usr/local/lib/python3.6/dist-packages/numpy/core/include',
|
||||||
|
'-I' + numpy.__path__[0] + '/core/include',
|
||||||
|
'-I/usr/local/cuda/include',
|
||||||
|
'-I/usr/local/TensorRT-7.1.3.4/include', # for my x86_64 PC
|
||||||
|
'-I/usr/local/include',
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Follow the steps in the original [README.md](https://github.com/jkjung-avt/tensorrt_demos/blob/master/README.md), and the demos should work on x86_64 as well.
|
||||||
|
|
||||||
|
Demo #3 (SSD)
|
||||||
|
-------------
|
||||||
|
|
||||||
|
1. Make sure to follow NVIDIA's official [Installation Guide :: NVIDIA Deep Learning TensorRT](https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html) documentation and pip3 install "tensorrt", "uff", and "graphsurgeon" packages.
|
||||||
|
|
||||||
|
2. Patch `/usr/local/lib/python3.?/dist-packages/graphsurgeon/node_manipulation.py` by adding the following line (around line #42):
|
||||||
|
|
||||||
|
```python
|
||||||
|
def shape(node):
|
||||||
|
......
|
||||||
|
node.name = name or node.name
|
||||||
|
node.op = op or node.op or node.name
|
||||||
|
+ node.attr["dtype"].type = 1
|
||||||
|
for key, val in kwargs.items():
|
||||||
|
......
|
||||||
|
```
|
||||||
|
3. (I think this step is only required for TensorRT 6 or earlier versions.) Re-build `libflattenconcat.so` from TensorRT's 'python/uff_ssd' sample source code. For example,
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ mkdir -p ${HOME}/src/TensorRT-5.1.5.0
|
||||||
|
$ cp -r /usr/local/TensorRT-5.1.5.0/samples ${HOME}/src/TensorRT-5.1.5.0
|
||||||
|
$ cd ${HOME}/src/TensorRT-5.1.5.0/samples/python/uff_ssd
|
||||||
|
$ mkdir build
|
||||||
|
$ cd build
|
||||||
|
$ cmake -D NVINFER_LIB=/usr/local/TensorRT-5.1.5.0/lib/libnvinfer.so \
|
||||||
|
-D TRT_INCLUDE=/usr/local/TensorRT-5.1.5.0/include ..
|
||||||
|
$ make
|
||||||
|
$ cp libflattenconcat.so ${HOME}/project/tensorrt_demos/ssd/
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Install "pycuda".
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ sudo apt-get install -y build-essential python-dev
|
||||||
|
$ sudo apt-get install -y libboost-python-dev libboost-thread-dev
|
||||||
|
$ sudo pip3 install setuptools
|
||||||
|
$ export boost_pylib=$(basename /usr/lib/x86_64-linux-gnu/libboost_python3-py3?.so)
|
||||||
|
$ export boost_pylibname=${boost_pylib%.so}
|
||||||
|
$ export boost_pyname=${boost_pylibname/lib/}
|
||||||
|
$ cd ${HOME}/src
|
||||||
|
$ wget https://files.pythonhosted.org/packages/5e/3f/5658c38579b41866ba21ee1b5020b8225cec86fe717e4b1c5c972de0a33c/pycuda-2019.1.2.tar.gz
|
||||||
|
$ tar xzvf pycuda-2019.1.2.tar.gz
|
||||||
|
$ cd pycuda-2019.1.2
|
||||||
|
$ ./configure.py --python-exe=/usr/bin/python3 \
|
||||||
|
--cuda-root=/usr/local/cuda \
|
||||||
|
--cudadrv-lib-dir=/usr/lib/x86_64-linux-gnu \
|
||||||
|
--boost-inc-dir=/usr/include \
|
||||||
|
--boost-lib-dir=/usr/lib/x86_64-linux-gnu \
|
||||||
|
--boost-python-libname=${boost_pyname} \
|
||||||
|
--boost-thread-libname=boost_thread \
|
||||||
|
--no-use-shipped-boost
|
||||||
|
$ make -j4
|
||||||
|
$ python3 setup.py build
|
||||||
|
$ sudo python3 setup.py install
|
||||||
|
$ python3 -c "import pycuda; print('pycuda version:', pycuda.VERSION)"
|
||||||
|
```
|
||||||
|
|
||||||
|
5. Follow the steps in the original [README.md](https://github.com/jkjung-avt/tensorrt_demos/blob/master/README.md) but skip `install.sh`. You should be able to build the SSD TensorRT engines and run them on on x86_64 as well.
|
||||||
|
|
||||||
|
Demo #4 (YOLOv3) & Demo #5 (YOLOv4)
|
||||||
|
-----------------------------------
|
||||||
|
|
||||||
|
Checkout "plugins/Makefile". You'll need to make sure in "plugins/Makefile":
|
||||||
|
|
||||||
|
* CUDA `compute` is set correctly for your GPU (reference: [CUDA GPUs | NVIDIA Developer]());
|
||||||
|
* `TENSORRT_INCS` and `TENSORRT_LIBS` point to the right paths.
|
||||||
|
|
||||||
|
```
|
||||||
|
......
|
||||||
|
else ifeq ($(cpu_arch), x86_64) # x86_64 PC
|
||||||
|
$(warning "compute=75" is for GeForce RTX-2080 Ti. Please make sure CUDA compute is set correctly for your system in the Makefile.)
|
||||||
|
compute=75
|
||||||
|
......
|
||||||
|
NVCCFLAGS=-m64 -gencode arch=compute_$(compute),code=sm_$(compute) \
|
||||||
|
-gencode arch=compute_$(compute),code=compute_$(compute)
|
||||||
|
......
|
||||||
|
# These are the directories where I installed TensorRT on my x86_64 PC.
|
||||||
|
TENSORRT_INCS=-I"/usr/local/TensorRT-7.1.3.4/include"
|
||||||
|
TENSORRT_LIBS=-L"/usr/local/TensorRT-7.1.3.4/lib"
|
||||||
|
......
|
||||||
|
```
|
||||||
|
|
||||||
|
Otherwise, you should be able to follow the steps in the original [README.md](https://github.com/jkjung-avt/tensorrt_demos/blob/master/README.md) to get these 2 demos working.
|
||||||
|
|
@ -0,0 +1,207 @@
|
||||||
|
.SUFFIXES:
|
||||||
|
TARGET?=$(shell uname -m)
|
||||||
|
ifeq ($(CUDA_INSTALL_DIR),)
|
||||||
|
$(warning CUDA_INSTALL_DIR variable is not specified, using /usr/local/cuda by default, use CUDA_INSTALL_DIR=<cuda_directory> to change.)
|
||||||
|
endif
|
||||||
|
ifeq ($(CUDNN_INSTALL_DIR),)
|
||||||
|
$(warning CUDNN_INSTALL_DIR variable is not specified, using $(CUDA_INSTALL_DIR) by default, use CUDNN_INSTALL_DIR=<cudnn_directory> to change.)
|
||||||
|
endif
|
||||||
|
CUDA_INSTALL_DIR?=/usr/local/cuda
|
||||||
|
CUDNN_INSTALL_DIR?=$(CUDA_INSTALL_DIR)
|
||||||
|
CUDA_LIBDIR=lib
|
||||||
|
CUDNN_LIBDIR=lib64
|
||||||
|
ifeq ($(TARGET), aarch64)
|
||||||
|
ifeq ($(shell uname -m), aarch64)
|
||||||
|
CUDA_LIBDIR=lib64
|
||||||
|
CC = g++
|
||||||
|
else
|
||||||
|
CC = aarch64-linux-gnu-g++
|
||||||
|
endif
|
||||||
|
CUCC =$(CUDA_INSTALL_DIR)/bin/nvcc -m64 -ccbin $(CC)
|
||||||
|
else ifeq ($(TARGET), x86_64)
|
||||||
|
CUDA_LIBDIR=lib64
|
||||||
|
CC = g++
|
||||||
|
CUCC =$(CUDA_INSTALL_DIR)/bin/nvcc -m64
|
||||||
|
else ifeq ($(TARGET), qnx)
|
||||||
|
CC = ${QNX_HOST}/usr/bin/aarch64-unknown-nto-qnx7.0.0-g++
|
||||||
|
CUCC = $(CUDA_INSTALL_DIR)/bin/nvcc -m64 -ccbin $(CC)
|
||||||
|
else ifeq ($(TARGET), android64)
|
||||||
|
ifeq ($(NDK_ROOT),)
|
||||||
|
$(error NDK_ROOT must be set to build for android platforms)
|
||||||
|
endif
|
||||||
|
ifeq ($(ANDROID_CC),)
|
||||||
|
$(error ANDROID_CC must be set to the g++ compiler to build for android 64bit, for example $(NDK_ROOT)/toolschains/aarch64-linux-android-4.9/prebuilt/linux-x86_64/bin/aarch64-linux-android-g++)
|
||||||
|
endif
|
||||||
|
ifeq ($(NDK_SYS_ROOT),)
|
||||||
|
$(error NDK_SYS_ROOT must be set to compiler for android 64bit, for example $(NDK_ROOT)/platforms/android-24/arch-arm64)
|
||||||
|
endif
|
||||||
|
CUDA_LIBDIR=lib64
|
||||||
|
ANDROID_FLAGS=--sysroot=${NDK_SYS_ROOT} -DANDROID -D_GLIBCXX_USE_C99=1 -Wno-sign-compare -D__aarch64__ -Wno-strict-aliasing -Werror -pie -fPIE
|
||||||
|
COMMON_FLAGS+=$(ANDROID_FLAGS)
|
||||||
|
COMMON_LD_FLAGS+=$(ANDROID_FLAGS)
|
||||||
|
CC=$(ANDROID_CC)
|
||||||
|
CUCC = $(CUDA_INSTALL_DIR)/bin/nvcc -m64 -ccbin $(CC) --compiler-options="--sysroot=${NDK_SYS_ROOT} -DANDROID -D_GLIBCXX_USE_C99=1 -Wno-sign-compare"
|
||||||
|
TGT_INCLUDES=-I$(NDK_ROOT)/platforms/android-24/arch-aarch64/usr/include -I$(NDK_ROOT)/sources/cxx-stl/gnu-libstdc++/4.9/include -I$(NDK_ROOT)/sources/cxx-stl/gnu-libstdc++/4.9/libs/arm64-v8a/include
|
||||||
|
TGT_LIBS=-L$(NDK_ROOT)/sources/cxx-stl/gnu-libstdc++/4.9/libs/arm64-v8a
|
||||||
|
ANDROID=1
|
||||||
|
else ########
|
||||||
|
$(error Auto-detection of platform failed. Please specify one of the following arguments to make: TARGET=[aarch64|x86_64|qnx])
|
||||||
|
endif
|
||||||
|
|
||||||
|
ifdef VERBOSE
|
||||||
|
AT=
|
||||||
|
else
|
||||||
|
AT=@
|
||||||
|
endif
|
||||||
|
|
||||||
|
AR = ar cr
|
||||||
|
ECHO = @echo
|
||||||
|
|
||||||
|
SHELL=/bin/sh
|
||||||
|
|
||||||
|
#ROOT_PATH=../..
|
||||||
|
#OUT_PATH=$(ROOT_PATH)/bin
|
||||||
|
OUT_PATH=.
|
||||||
|
OUTDIR=$(OUT_PATH)
|
||||||
|
|
||||||
|
define concat
|
||||||
|
$1$2$3$4$5$6$7$8
|
||||||
|
endef
|
||||||
|
|
||||||
|
#$(call make-depend,source-file,object-file,depend-file)
|
||||||
|
define make-depend
|
||||||
|
$(AT)$(CC) -MM -MF $3 -MP -MT $2 $(COMMON_FLAGS) $1
|
||||||
|
endef
|
||||||
|
|
||||||
|
#########################
|
||||||
|
|
||||||
|
# These are the directories where I installed TensorRT on my x86_64 PC.
|
||||||
|
TENSORRT_INCS=-I"/usr/local/TensorRT-7.1.3.4/include"
|
||||||
|
TENSORRT_LIBS=-L"/usr/local/TensorRT-7.1.3.4/lib"
|
||||||
|
|
||||||
|
INCPATHS=-I"$(CUDA_INSTALL_DIR)/include" $(TENSORRT_INCS) -I"/usr/local/include" -I"$(CUDNN_INSTALL_DIR)/include" $(TGT_INCLUDES) -I"../common"
|
||||||
|
LIBPATHS=-L"$(CUDA_INSTALL_DIR)/$(CUDA_LIBDIR)" $(TENSORRT_LIBS) -L"/usr/local/lib" -L"$(CUDA_INSTALL_DIR)/$(CUDA_LIBDIR)" -L"$(CUDNN_INSTALL_DIR)/$(CUDNN_LIBDIR)" $(TGT_LIBS)
|
||||||
|
|
||||||
|
.SUFFIXES:
|
||||||
|
vpath %.h $(EXTRA_DIRECTORIES)
|
||||||
|
vpath %.cpp $(EXTRA_DIRECTORIES)
|
||||||
|
|
||||||
|
COMMON_FLAGS += -Wall -std=c++11 $(INCPATHS)
|
||||||
|
ifneq ($(ANDROID),1)
|
||||||
|
COMMON_FLAGS += -D_REENTRANT
|
||||||
|
endif
|
||||||
|
COMMON_LD_FLAGS += $(LIBPATHS) -L$(OUTDIR)
|
||||||
|
|
||||||
|
OBJDIR =$(call concat,$(OUTDIR),/chobj)
|
||||||
|
DOBJDIR =$(call concat,$(OUTDIR),/dchobj)
|
||||||
|
|
||||||
|
ifeq ($(ANDROID),1)
|
||||||
|
COMMON_LIBS = -lcudnn -lcublas -lnvToolsExt -lcudart
|
||||||
|
else
|
||||||
|
COMMON_LIBS = -lcudnn -lcublas -lcudart_static -lnvToolsExt -lcudart
|
||||||
|
endif
|
||||||
|
ifneq ($(TARGET), qnx)
|
||||||
|
ifneq ($(ANDROID),1)
|
||||||
|
COMMON_LIBS += -lrt -ldl -lpthread
|
||||||
|
endif
|
||||||
|
endif
|
||||||
|
ifeq ($(ANDROID),1)
|
||||||
|
COMMON_LIBS += -lculibos -lgnustl_shared -llog
|
||||||
|
endif
|
||||||
|
|
||||||
|
LIBS =-lnvinfer -lnvparsers -lnvinfer_plugin $(COMMON_LIBS)
|
||||||
|
DLIBS =-lnvinfer -lnvparsers -lnvinfer_plugin $(COMMON_LIBS)
|
||||||
|
OBJS =$(patsubst %.cpp, $(OBJDIR)/%.o, $(wildcard *.cpp $(addsuffix /*.cpp, $(EXTRA_DIRECTORIES))))
|
||||||
|
DOBJS =$(patsubst %.cpp, $(DOBJDIR)/%.o, $(wildcard *.cpp $(addsuffix /*.cpp, $(EXTRA_DIRECTORIES))))
|
||||||
|
CUOBJS =$(patsubst %.cu, $(OBJDIR)/%.o, $(wildcard *.cu $(addsuffix /*.cu, $(EXTRA_DIRECTORIES))))
|
||||||
|
CUDOBJS =$(patsubst %.cu, $(DOBJDIR)/%.o, $(wildcard *.cu $(addsuffix /*.cu, $(EXTRA_DIRECTORIES))))
|
||||||
|
|
||||||
|
CFLAGS=$(COMMON_FLAGS)
|
||||||
|
CFLAGSD=$(COMMON_FLAGS) -g
|
||||||
|
LFLAGS=$(COMMON_LD_FLAGS)
|
||||||
|
LFLAGSD=$(COMMON_LD_FLAGS)
|
||||||
|
|
||||||
|
#all: debug release
|
||||||
|
|
||||||
|
release : $(OUTDIR)/$(OUTNAME_RELEASE)
|
||||||
|
|
||||||
|
debug : $(OUTDIR)/$(OUTNAME_DEBUG)
|
||||||
|
|
||||||
|
test: test_debug test_release
|
||||||
|
|
||||||
|
test_debug:
|
||||||
|
$(AT)cd $(OUTDIR) && ./$(OUTNAME_DEBUG)
|
||||||
|
|
||||||
|
test_release:
|
||||||
|
$(AT)cd $(OUTDIR) && ./$(OUTNAME_RELEASE)
|
||||||
|
|
||||||
|
ifdef MAC
|
||||||
|
$(OUTDIR)/$(OUTNAME_RELEASE) : $(OBJS) $(CUOBJS)
|
||||||
|
$(ECHO) Linking: $@
|
||||||
|
$(AT)$(CC) -o $@ $^ $(LFLAGS) $(LIBS)
|
||||||
|
$(foreach EXTRA_FILE,$(EXTRA_FILES), cp -f $(EXTRA_FILE) $(OUTDIR)/$(EXTRA_FILE); )
|
||||||
|
|
||||||
|
$(OUTDIR)/$(OUTNAME_DEBUG) : $(DOBJS) $(CUDOBJS)
|
||||||
|
$(ECHO) Linking: $@
|
||||||
|
$(AT)$(CC) -o $@ $^ $(LFLAGSD) $(DLIBS)
|
||||||
|
else
|
||||||
|
$(OUTDIR)/$(OUTNAME_RELEASE) : $(OBJS) $(CUOBJS)
|
||||||
|
$(ECHO) Linking: $@
|
||||||
|
$(AT)$(CC) -o $@ $^ $(LFLAGS) -Wl,--start-group $(LIBS) -Wl,--end-group
|
||||||
|
$(foreach EXTRA_FILE,$(EXTRA_FILES), cp -f $(EXTRA_FILE) $(OUTDIR)/$(EXTRA_FILE); )
|
||||||
|
|
||||||
|
$(OUTDIR)/$(OUTNAME_DEBUG) : $(DOBJS) $(CUDOBJS)
|
||||||
|
$(ECHO) Linking: $@
|
||||||
|
$(AT)$(CC) -o $@ $^ $(LFLAGSD) -Wl,--start-group $(DLIBS) -Wl,--end-group
|
||||||
|
endif
|
||||||
|
|
||||||
|
$(OBJDIR)/%.o: %.cpp
|
||||||
|
$(AT)if [ ! -d $(OBJDIR) ]; then mkdir -p $(OBJDIR); fi
|
||||||
|
$(foreach XDIR,$(EXTRA_DIRECTORIES), if [ ! -d $(OBJDIR)/$(XDIR) ]; then mkdir -p $(OBJDIR)/$(XDIR); fi;) :
|
||||||
|
$(call make-depend,$<,$@,$(subst .o,.d,$@))
|
||||||
|
$(ECHO) Compiling: $<
|
||||||
|
$(AT)$(CC) $(CFLAGS) -c -o $@ $<
|
||||||
|
|
||||||
|
$(DOBJDIR)/%.o: %.cpp
|
||||||
|
$(AT)if [ ! -d $(DOBJDIR) ]; then mkdir -p $(DOBJDIR); fi
|
||||||
|
$(foreach XDIR,$(EXTRA_DIRECTORIES), if [ ! -d $(OBJDIR)/$(XDIR) ]; then mkdir -p $(DOBJDIR)/$(XDIR); fi;) :
|
||||||
|
$(call make-depend,$<,$@,$(subst .o,.d,$@))
|
||||||
|
$(ECHO) Compiling: $<
|
||||||
|
$(AT)$(CC) $(CFLAGSD) -c -o $@ $<
|
||||||
|
|
||||||
|
######################################################################### CU
|
||||||
|
$(OBJDIR)/%.o: %.cu
|
||||||
|
$(AT)if [ ! -d $(OBJDIR) ]; then mkdir -p $(OBJDIR); fi
|
||||||
|
$(foreach XDIR,$(EXTRA_DIRECTORIES), if [ ! -d $(OBJDIR)/$(XDIR) ]; then mkdir -p $(OBJDIR)/$(XDIR); fi;) :
|
||||||
|
$(call make-depend,$<,$@,$(subst .o,.d,$@))
|
||||||
|
$(ECHO) Compiling CUDA release: $<
|
||||||
|
$(AT)$(CUCC) $(CUFLAGS) -c -o $@ $<
|
||||||
|
|
||||||
|
$(DOBJDIR)/%.o: %.cu
|
||||||
|
$(AT)if [ ! -d $(DOBJDIR) ]; then mkdir -p $(DOBJDIR); fi
|
||||||
|
$(foreach XDIR,$(EXTRA_DIRECTORIES), if [ ! -d $(DOBJDIR)/$(XDIR) ]; then mkdir -p $(DOBJDIR)/$(XDIR); fi;) :
|
||||||
|
$(call make-depend,$<,$@,$(subst .o,.d,$@))
|
||||||
|
$(ECHO) Compiling CUDA debug: $<
|
||||||
|
$(AT)$(CUCC) $(CUFLAGSD) -c -o $@ $<
|
||||||
|
|
||||||
|
clean:
|
||||||
|
$(ECHO) Cleaning...
|
||||||
|
$(AT)-rm -rf $(OBJDIR) $(DOBJDIR) $(OUTDIR)/$(OUTNAME_RELEASE) $(OUTDIR)/$(OUTNAME_DEBUG)
|
||||||
|
$(AT)-rm -rf *.engine
|
||||||
|
|
||||||
|
ifneq "$(MAKECMDGOALS)" "clean"
|
||||||
|
-include $(OBJDIR)/*.d $(DOBJDIR)/*.d
|
||||||
|
endif
|
||||||
|
|
||||||
|
ifeq ($(DO_CUDNN_CHECK), 1)
|
||||||
|
# To display newlines in the message
|
||||||
|
define _cudnn_missing_newline_5020fd0
|
||||||
|
|
||||||
|
|
||||||
|
endef
|
||||||
|
SHELL=/bin/bash
|
||||||
|
CUDNN_CHECK = $(shell echo -e '\#include <cudnn.h>\nint main(){ cudnnCreate(nullptr); return 0; }' | $(CC) -xc++ -o /dev/null $(CFLAGS) $(LFLAGS) - $(COMMON_LIBS) 2> /dev/null && echo 'passed_cudnn_exists_check')
|
||||||
|
ifneq ($(CUDNN_CHECK), passed_cudnn_exists_check)
|
||||||
|
$(error $(_cudnn_missing_newline_5020fd0)$(_cudnn_missing_newline_5020fd0)This sample requires CUDNN, but it could not be found.$(_cudnn_missing_newline_5020fd0)Please install CUDNN from https://developer.nvidia.com/cudnn or specify CUDNN_INSTALL_DIR when compiling.$(_cudnn_missing_newline_5020fd0)For example, `make CUDNN_INSTALL_DIR=/path/to/CUDNN/` where /path/to/CUDNN/ contains include/ and lib/ subdirectories.$(_cudnn_missing_newline_5020fd0)$(_cudnn_missing_newline_5020fd0))
|
||||||
|
endif
|
||||||
|
endif
|
||||||
|
|
@ -0,0 +1,364 @@
|
||||||
|
#ifndef _TRT_COMMON_H_
|
||||||
|
#define _TRT_COMMON_H_
|
||||||
|
#include "NvInfer.h"
|
||||||
|
//#include "NvOnnxConfig.h"
|
||||||
|
//#include "NvOnnxParser.h"
|
||||||
|
#include <cuda_runtime_api.h>
|
||||||
|
#include <algorithm>
|
||||||
|
#include <cassert>
|
||||||
|
#include <fstream>
|
||||||
|
#include <iostream>
|
||||||
|
#include <iterator>
|
||||||
|
#include <map>
|
||||||
|
#include <memory>
|
||||||
|
#include <numeric>
|
||||||
|
#include <string>
|
||||||
|
#include <vector>
|
||||||
|
#include <cstring>
|
||||||
|
#include <cmath>
|
||||||
|
|
||||||
|
using namespace std;
|
||||||
|
|
||||||
|
#if NV_TENSORRT_MAJOR >= 8
|
||||||
|
#define NOEXCEPT noexcept
|
||||||
|
#else
|
||||||
|
#define NOEXCEPT
|
||||||
|
#endif
|
||||||
|
|
||||||
|
#define CHECK(status) \
|
||||||
|
do \
|
||||||
|
{ \
|
||||||
|
auto ret = (status); \
|
||||||
|
if (ret != 0) \
|
||||||
|
{ \
|
||||||
|
std::cout << "Cuda failure: " << ret; \
|
||||||
|
abort(); \
|
||||||
|
} \
|
||||||
|
} while (0)
|
||||||
|
|
||||||
|
constexpr long double operator"" _GB(long double val) { return val * (1 << 30); }
|
||||||
|
constexpr long double operator"" _MB(long double val) { return val * (1 << 20); }
|
||||||
|
constexpr long double operator"" _KB(long double val) { return val * (1 << 10); }
|
||||||
|
|
||||||
|
// These is necessary if we want to be able to write 1_GB instead of 1.0_GB.
|
||||||
|
// Since the return type is signed, -1_GB will work as expected.
|
||||||
|
constexpr long long int operator"" _GB(long long unsigned int val) { return val * (1 << 30); }
|
||||||
|
constexpr long long int operator"" _MB(long long unsigned int val) { return val * (1 << 20); }
|
||||||
|
constexpr long long int operator"" _KB(long long unsigned int val) { return val * (1 << 10); }
|
||||||
|
|
||||||
|
// Logger for TensorRT info/warning/errors
|
||||||
|
class Logger : public nvinfer1::ILogger
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
|
||||||
|
//Logger(): Logger(Severity::kWARNING) {}
|
||||||
|
|
||||||
|
Logger(Severity severity): reportableSeverity(severity) {}
|
||||||
|
|
||||||
|
void log(Severity severity, const char* msg) NOEXCEPT override
|
||||||
|
{
|
||||||
|
// suppress messages with severity enum value greater than the reportable
|
||||||
|
if (severity > reportableSeverity) return;
|
||||||
|
|
||||||
|
switch (severity)
|
||||||
|
{
|
||||||
|
case Severity::kINTERNAL_ERROR: std::cerr << "INTERNAL_ERROR: "; break;
|
||||||
|
case Severity::kERROR: std::cerr << "ERROR: "; break;
|
||||||
|
case Severity::kWARNING: std::cerr << "WARNING: "; break;
|
||||||
|
case Severity::kINFO: std::cerr << "INFO: "; break;
|
||||||
|
default: std::cerr << "UNKNOWN: "; break;
|
||||||
|
}
|
||||||
|
std::cerr << msg << std::endl;
|
||||||
|
}
|
||||||
|
|
||||||
|
Severity reportableSeverity{Severity::kWARNING};
|
||||||
|
};
|
||||||
|
|
||||||
|
// Locate path to file, given its filename or filepath suffix and possible dirs it might lie in
|
||||||
|
// Function will also walk back MAX_DEPTH dirs from CWD to check for such a file path
|
||||||
|
inline std::string locateFile(const std::string& filepathSuffix, const std::vector<std::string>& directories)
|
||||||
|
{
|
||||||
|
const int MAX_DEPTH{10};
|
||||||
|
bool found{false};
|
||||||
|
std::string filepath;
|
||||||
|
|
||||||
|
for (auto& dir : directories)
|
||||||
|
{
|
||||||
|
filepath = dir + filepathSuffix;
|
||||||
|
|
||||||
|
for (int i = 0; i < MAX_DEPTH && !found; i++)
|
||||||
|
{
|
||||||
|
std::ifstream checkFile(filepath);
|
||||||
|
found = checkFile.is_open();
|
||||||
|
if (found) break;
|
||||||
|
filepath = "../" + filepath; // Try again in parent dir
|
||||||
|
}
|
||||||
|
|
||||||
|
if (found)
|
||||||
|
{
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
|
||||||
|
filepath.clear();
|
||||||
|
}
|
||||||
|
|
||||||
|
if (filepath.empty()) {
|
||||||
|
std::string directoryList = std::accumulate(directories.begin() + 1, directories.end(), directories.front(),
|
||||||
|
[](const std::string& a, const std::string& b) { return a + "\n\t" + b; });
|
||||||
|
throw std::runtime_error("Could not find " + filepathSuffix + " in data directories:\n\t" + directoryList);
|
||||||
|
}
|
||||||
|
return filepath;
|
||||||
|
}
|
||||||
|
|
||||||
|
inline void readPGMFile(const std::string& fileName, uint8_t* buffer, int inH, int inW)
|
||||||
|
{
|
||||||
|
std::ifstream infile(fileName, std::ifstream::binary);
|
||||||
|
assert(infile.is_open() && "Attempting to read from a file that is not open.");
|
||||||
|
std::string magic, h, w, max;
|
||||||
|
infile >> magic >> h >> w >> max;
|
||||||
|
infile.seekg(1, infile.cur);
|
||||||
|
infile.read(reinterpret_cast<char*>(buffer), inH * inW);
|
||||||
|
}
|
||||||
|
|
||||||
|
namespace samples_common
|
||||||
|
{
|
||||||
|
|
||||||
|
inline void* safeCudaMalloc(size_t memSize)
|
||||||
|
{
|
||||||
|
void* deviceMem;
|
||||||
|
CHECK(cudaMalloc(&deviceMem, memSize));
|
||||||
|
if (deviceMem == nullptr)
|
||||||
|
{
|
||||||
|
std::cerr << "Out of memory" << std::endl;
|
||||||
|
exit(1);
|
||||||
|
}
|
||||||
|
return deviceMem;
|
||||||
|
}
|
||||||
|
|
||||||
|
inline bool isDebug()
|
||||||
|
{
|
||||||
|
return (std::getenv("TENSORRT_DEBUG") ? true : false);
|
||||||
|
}
|
||||||
|
|
||||||
|
struct InferDeleter
|
||||||
|
{
|
||||||
|
template <typename T>
|
||||||
|
void operator()(T* obj) const
|
||||||
|
{
|
||||||
|
if (obj) {
|
||||||
|
obj->destroy();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|
||||||
|
template <typename T>
|
||||||
|
inline std::shared_ptr<T> infer_object(T* obj)
|
||||||
|
{
|
||||||
|
if (!obj) {
|
||||||
|
throw std::runtime_error("Failed to create object");
|
||||||
|
}
|
||||||
|
return std::shared_ptr<T>(obj, InferDeleter());
|
||||||
|
}
|
||||||
|
|
||||||
|
template <class Iter>
|
||||||
|
inline std::vector<size_t> argsort(Iter begin, Iter end, bool reverse = false)
|
||||||
|
{
|
||||||
|
std::vector<size_t> inds(end - begin);
|
||||||
|
std::iota(inds.begin(), inds.end(), 0);
|
||||||
|
if (reverse) {
|
||||||
|
std::sort(inds.begin(), inds.end(), [&begin](size_t i1, size_t i2) {
|
||||||
|
return begin[i2] < begin[i1];
|
||||||
|
});
|
||||||
|
}
|
||||||
|
else
|
||||||
|
{
|
||||||
|
std::sort(inds.begin(), inds.end(), [&begin](size_t i1, size_t i2) {
|
||||||
|
return begin[i1] < begin[i2];
|
||||||
|
});
|
||||||
|
}
|
||||||
|
return inds;
|
||||||
|
}
|
||||||
|
|
||||||
|
inline bool readReferenceFile(const std::string& fileName, std::vector<std::string>& refVector)
|
||||||
|
{
|
||||||
|
std::ifstream infile(fileName);
|
||||||
|
if (!infile.is_open()) {
|
||||||
|
cout << "ERROR: readReferenceFile: Attempting to read from a file that is not open." << endl;
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
std::string line;
|
||||||
|
while (std::getline(infile, line)) {
|
||||||
|
if (line.empty()) continue;
|
||||||
|
refVector.push_back(line);
|
||||||
|
}
|
||||||
|
infile.close();
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
|
||||||
|
template <typename result_vector_t>
|
||||||
|
inline std::vector<std::string> classify(const vector<string>& refVector, const result_vector_t& output, const size_t topK)
|
||||||
|
{
|
||||||
|
auto inds = samples_common::argsort(output.cbegin(), output.cend(), true);
|
||||||
|
std::vector<std::string> result;
|
||||||
|
for (size_t k = 0; k < topK; ++k) {
|
||||||
|
result.push_back(refVector[inds[k]]);
|
||||||
|
}
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
|
||||||
|
//...LG returns top K indices, not values.
|
||||||
|
template <typename T>
|
||||||
|
inline vector<size_t> topK(const vector<T> inp, const size_t k)
|
||||||
|
{
|
||||||
|
vector<size_t> result;
|
||||||
|
std::vector<size_t> inds = samples_common::argsort(inp.cbegin(), inp.cend(), true);
|
||||||
|
result.assign(inds.begin(), inds.begin()+k);
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
|
||||||
|
template <typename T>
|
||||||
|
inline bool readASCIIFile(const string& fileName, const size_t size, vector<T>& out)
|
||||||
|
{
|
||||||
|
std::ifstream infile(fileName);
|
||||||
|
if (!infile.is_open()) {
|
||||||
|
cout << "ERROR readASCIIFile: Attempting to read from a file that is not open." << endl;
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
out.clear();
|
||||||
|
out.reserve(size);
|
||||||
|
out.assign(std::istream_iterator<T>(infile), std::istream_iterator<T>());
|
||||||
|
infile.close();
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
|
||||||
|
template <typename T>
|
||||||
|
inline bool writeASCIIFile(const string& fileName, const vector<T>& in)
|
||||||
|
{
|
||||||
|
std::ofstream outfile(fileName);
|
||||||
|
if (!outfile.is_open()) {
|
||||||
|
cout << "ERROR: writeASCIIFile: Attempting to write to a file that is not open." << endl;
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
for (auto fn : in) {
|
||||||
|
outfile << fn << " ";
|
||||||
|
}
|
||||||
|
outfile.close();
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
|
||||||
|
#if 0 // for compatibility between TensorRT 3.x and 4.x
|
||||||
|
inline void print_version()
|
||||||
|
{
|
||||||
|
//... This can be only done after statically linking this support into parserONNX.library
|
||||||
|
std::cout << "Parser built against:" << std::endl;
|
||||||
|
std::cout << " ONNX IR version: " << nvonnxparser::onnx_ir_version_string(onnx::IR_VERSION) << std::endl;
|
||||||
|
std::cout << " TensorRT version: "
|
||||||
|
<< NV_TENSORRT_MAJOR << "."
|
||||||
|
<< NV_TENSORRT_MINOR << "."
|
||||||
|
<< NV_TENSORRT_PATCH << "."
|
||||||
|
<< NV_TENSORRT_BUILD << std::endl;
|
||||||
|
}
|
||||||
|
#endif // 0
|
||||||
|
|
||||||
|
inline string getFileType(const string& filepath)
|
||||||
|
{
|
||||||
|
return filepath.substr(filepath.find_last_of(".") + 1);
|
||||||
|
}
|
||||||
|
|
||||||
|
inline string toLower(const string& inp)
|
||||||
|
{
|
||||||
|
string out = inp;
|
||||||
|
std::transform(out.begin(), out.end(), out.begin(), ::tolower);
|
||||||
|
return out;
|
||||||
|
}
|
||||||
|
|
||||||
|
#if 0 // for compatibility between TensorRT 3.x and 4.x
|
||||||
|
inline unsigned int getElementSize(nvinfer1::DataType t)
|
||||||
|
{
|
||||||
|
switch (t)
|
||||||
|
{
|
||||||
|
case nvinfer1::DataType::kINT32: return 4;
|
||||||
|
case nvinfer1::DataType::kFLOAT: return 4;
|
||||||
|
case nvinfer1::DataType::kHALF: return 2;
|
||||||
|
case nvinfer1::DataType::kINT8: return 1;
|
||||||
|
}
|
||||||
|
throw std::runtime_error("Invalid DataType.");
|
||||||
|
return 0;
|
||||||
|
}
|
||||||
|
#endif // 0
|
||||||
|
|
||||||
|
inline int64_t volume(const nvinfer1::Dims& d)
|
||||||
|
{
|
||||||
|
return std::accumulate(d.d, d.d + d.nbDims, 1, std::multiplies<int64_t>());
|
||||||
|
}
|
||||||
|
|
||||||
|
// Struct to maintain command-line arguments.
|
||||||
|
struct Args
|
||||||
|
{
|
||||||
|
bool runInInt8 = false;
|
||||||
|
};
|
||||||
|
|
||||||
|
// Populates the Args struct with the provided command-line parameters.
|
||||||
|
inline void parseArgs(Args& args, int argc, char* argv[])
|
||||||
|
{
|
||||||
|
if (argc >= 1)
|
||||||
|
{
|
||||||
|
for (int i = 1; i < argc; ++i)
|
||||||
|
{
|
||||||
|
if (!strcmp(argv[i], "--int8")) args.runInInt8 = true;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
template <int C, int H, int W>
|
||||||
|
struct PPM
|
||||||
|
{
|
||||||
|
std::string magic, fileName;
|
||||||
|
int h, w, max;
|
||||||
|
uint8_t buffer[C * H * W];
|
||||||
|
};
|
||||||
|
|
||||||
|
struct BBox
|
||||||
|
{
|
||||||
|
float x1, y1, x2, y2;
|
||||||
|
};
|
||||||
|
|
||||||
|
template <int C, int H, int W>
|
||||||
|
inline void writePPMFileWithBBox(const std::string& filename, PPM<C, H, W>& ppm, const BBox& bbox)
|
||||||
|
{
|
||||||
|
std::ofstream outfile("./" + filename, std::ofstream::binary);
|
||||||
|
assert(!outfile.fail());
|
||||||
|
outfile << "P6" << "\n" << ppm.w << " " << ppm.h << "\n" << ppm.max << "\n";
|
||||||
|
auto round = [](float x) -> int { return int(std::floor(x + 0.5f)); };
|
||||||
|
const int x1 = std::min(std::max(0, round(int(bbox.x1))), W - 1);
|
||||||
|
const int x2 = std::min(std::max(0, round(int(bbox.x2))), W - 1);
|
||||||
|
const int y1 = std::min(std::max(0, round(int(bbox.y1))), H - 1);
|
||||||
|
const int y2 = std::min(std::max(0, round(int(bbox.y2))), H - 1);
|
||||||
|
for (int x = x1; x <= x2; ++x)
|
||||||
|
{
|
||||||
|
// bbox top border
|
||||||
|
ppm.buffer[(y1 * ppm.w + x) * 3] = 255;
|
||||||
|
ppm.buffer[(y1 * ppm.w + x) * 3 + 1] = 0;
|
||||||
|
ppm.buffer[(y1 * ppm.w + x) * 3 + 2] = 0;
|
||||||
|
// bbox bottom border
|
||||||
|
ppm.buffer[(y2 * ppm.w + x) * 3] = 255;
|
||||||
|
ppm.buffer[(y2 * ppm.w + x) * 3 + 1] = 0;
|
||||||
|
ppm.buffer[(y2 * ppm.w + x) * 3 + 2] = 0;
|
||||||
|
}
|
||||||
|
for (int y = y1; y <= y2; ++y)
|
||||||
|
{
|
||||||
|
// bbox left border
|
||||||
|
ppm.buffer[(y * ppm.w + x1) * 3] = 255;
|
||||||
|
ppm.buffer[(y * ppm.w + x1) * 3 + 1] = 0;
|
||||||
|
ppm.buffer[(y * ppm.w + x1) * 3 + 2] = 0;
|
||||||
|
// bbox right border
|
||||||
|
ppm.buffer[(y * ppm.w + x2) * 3] = 255;
|
||||||
|
ppm.buffer[(y * ppm.w + x2) * 3 + 1] = 0;
|
||||||
|
ppm.buffer[(y * ppm.w + x2) * 3 + 2] = 0;
|
||||||
|
}
|
||||||
|
outfile.write(reinterpret_cast<char*>(ppm.buffer), ppm.w * ppm.h * 3);
|
||||||
|
}
|
||||||
|
|
||||||
|
} // namespace samples_common
|
||||||
|
|
||||||
|
#endif // _TRT_COMMON_H_
|
||||||
|
|
@ -0,0 +1,104 @@
|
||||||
|
"""eval_ssd.py
|
||||||
|
|
||||||
|
This script is for evaluating mAP (accuracy) of SSD models. The
|
||||||
|
model being evaluated could be either a TensorFlow frozen inference
|
||||||
|
graph (pb) or a TensorRT engine.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
import sys
|
||||||
|
import json
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import pycuda.autoinit # This is needed for initializing CUDA driver
|
||||||
|
from pycocotools.coco import COCO
|
||||||
|
from pycocotools.cocoeval import COCOeval
|
||||||
|
from progressbar import progressbar
|
||||||
|
|
||||||
|
from utils.ssd import TrtSSD
|
||||||
|
from utils.ssd_tf import TfSSD
|
||||||
|
|
||||||
|
|
||||||
|
INPUT_HW = (300, 300)
|
||||||
|
SUPPORTED_MODELS = [
|
||||||
|
'ssd_mobilenet_v1_coco',
|
||||||
|
'ssd_mobilenet_v2_coco',
|
||||||
|
]
|
||||||
|
|
||||||
|
HOME = os.environ['HOME']
|
||||||
|
VAL_IMGS_DIR = HOME + '/data/coco/images/val2017'
|
||||||
|
VAL_ANNOTATIONS = HOME + '/data/coco/annotations/instances_val2017.json'
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = 'Evaluate mAP of SSD model'
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser.add_argument('--mode', type=str, default='trt',
|
||||||
|
choices=['tf', 'trt'])
|
||||||
|
parser.add_argument('--imgs_dir', type=str, default=VAL_IMGS_DIR,
|
||||||
|
help='directory of validation images [%s]' % VAL_IMGS_DIR)
|
||||||
|
parser.add_argument('--annotations', type=str, default=VAL_ANNOTATIONS,
|
||||||
|
help='groundtruth annotations [%s]' % VAL_ANNOTATIONS)
|
||||||
|
parser.add_argument('model', type=str, choices=SUPPORTED_MODELS)
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def check_args(args):
|
||||||
|
"""Check and make sure command-line arguments are valid."""
|
||||||
|
if not os.path.isdir(args.imgs_dir):
|
||||||
|
sys.exit('%s is not a valid directory' % args.imgs_dir)
|
||||||
|
if not os.path.isfile(args.annotations):
|
||||||
|
sys.exit('%s is not a valid file' % args.annotations)
|
||||||
|
|
||||||
|
|
||||||
|
def generate_results(ssd, imgs_dir, jpgs, results_file):
|
||||||
|
"""Run detection on each jpg and write results to file."""
|
||||||
|
results = []
|
||||||
|
for jpg in progressbar(jpgs):
|
||||||
|
img = cv2.imread(os.path.join(imgs_dir, jpg))
|
||||||
|
image_id = int(jpg.split('.')[0].split('_')[-1])
|
||||||
|
boxes, confs, clss = ssd.detect(img, conf_th=1e-2)
|
||||||
|
for box, conf, cls in zip(boxes, confs, clss):
|
||||||
|
x = float(box[0])
|
||||||
|
y = float(box[1])
|
||||||
|
w = float(box[2] - box[0] + 1)
|
||||||
|
h = float(box[3] - box[1] + 1)
|
||||||
|
results.append({'image_id': image_id,
|
||||||
|
'category_id': int(cls),
|
||||||
|
'bbox': [x, y, w, h],
|
||||||
|
'score': float(conf)})
|
||||||
|
with open(results_file, 'w') as f:
|
||||||
|
f.write(json.dumps(results, indent=4))
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
check_args(args)
|
||||||
|
|
||||||
|
results_file = 'ssd/results_%s_%s.json' % (args.model, args.mode)
|
||||||
|
if args.mode == 'trt':
|
||||||
|
ssd = TrtSSD(args.model, INPUT_HW)
|
||||||
|
else:
|
||||||
|
ssd = TfSSD(args.model, INPUT_HW)
|
||||||
|
|
||||||
|
jpgs = [j for j in os.listdir(args.imgs_dir) if j.endswith('.jpg')]
|
||||||
|
generate_results(ssd, args.imgs_dir, jpgs, results_file)
|
||||||
|
|
||||||
|
# Run COCO mAP evaluation
|
||||||
|
# Reference: https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
|
||||||
|
cocoGt = COCO(args.annotations)
|
||||||
|
cocoDt = cocoGt.loadRes(results_file)
|
||||||
|
imgIds = sorted(cocoGt.getImgIds())
|
||||||
|
cocoEval = COCOeval(cocoGt, cocoDt, 'bbox')
|
||||||
|
cocoEval.params.imgIds = imgIds
|
||||||
|
cocoEval.evaluate()
|
||||||
|
cocoEval.accumulate()
|
||||||
|
cocoEval.summarize()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,116 @@
|
||||||
|
"""eval_yolo.py
|
||||||
|
|
||||||
|
This script is for evaluating mAP (accuracy) of YOLO models.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
import sys
|
||||||
|
import json
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import pycuda.autoinit # This is needed for initializing CUDA driver
|
||||||
|
|
||||||
|
from pycocotools.coco import COCO
|
||||||
|
from pycocotools.cocoeval import COCOeval
|
||||||
|
from progressbar import progressbar
|
||||||
|
|
||||||
|
from utils.yolo_with_plugins import TrtYOLO
|
||||||
|
from utils.yolo_classes import yolo_cls_to_ssd
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
HOME = os.environ['HOME']
|
||||||
|
VAL_IMGS_DIR = HOME + '/data/coco/images/val2017'
|
||||||
|
VAL_ANNOTATIONS = HOME + '/data/coco/annotations/instances_val2017.json'
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = 'Evaluate mAP of YOLO model'
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser.add_argument(
|
||||||
|
'--imgs_dir', type=str, default=VAL_IMGS_DIR,
|
||||||
|
help='directory of validation images [%s]' % VAL_IMGS_DIR)
|
||||||
|
parser.add_argument(
|
||||||
|
'--annotations', type=str, default=VAL_ANNOTATIONS,
|
||||||
|
help='groundtruth annotations [%s]' % VAL_ANNOTATIONS)
|
||||||
|
parser.add_argument(
|
||||||
|
'--non_coco', action='store_true',
|
||||||
|
help='don\'t do coco class translation [False]')
|
||||||
|
parser.add_argument(
|
||||||
|
'-c', '--category_num', type=int, default=80,
|
||||||
|
help='number of object categories [80]')
|
||||||
|
parser.add_argument(
|
||||||
|
'-m', '--model', type=str, required=True,
|
||||||
|
help=('[yolov3|yolov3-tiny|yolov3-spp|yolov4|yolov4-tiny]-'
|
||||||
|
'[{dimension}], where dimension could be a single '
|
||||||
|
'number (e.g. 288, 416, 608) or WxH (e.g. 416x256)'))
|
||||||
|
parser.add_argument(
|
||||||
|
'-l', '--letter_box', action='store_true',
|
||||||
|
help='inference with letterboxed image [False]')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def check_args(args):
|
||||||
|
"""Check and make sure command-line arguments are valid."""
|
||||||
|
if not os.path.isdir(args.imgs_dir):
|
||||||
|
sys.exit('%s is not a valid directory' % args.imgs_dir)
|
||||||
|
if not os.path.isfile(args.annotations):
|
||||||
|
sys.exit('%s is not a valid file' % args.annotations)
|
||||||
|
|
||||||
|
|
||||||
|
def generate_results(trt_yolo, imgs_dir, jpgs, results_file, non_coco):
|
||||||
|
"""Run detection on each jpg and write results to file."""
|
||||||
|
results = []
|
||||||
|
for jpg in progressbar(jpgs):
|
||||||
|
img = cv2.imread(os.path.join(imgs_dir, jpg))
|
||||||
|
image_id = int(jpg.split('.')[0].split('_')[-1])
|
||||||
|
boxes, confs, clss = trt_yolo.detect(img, conf_th=1e-2)
|
||||||
|
for box, conf, cls in zip(boxes, confs, clss):
|
||||||
|
x = float(box[0])
|
||||||
|
y = float(box[1])
|
||||||
|
w = float(box[2] - box[0] + 1)
|
||||||
|
h = float(box[3] - box[1] + 1)
|
||||||
|
cls = int(cls)
|
||||||
|
cls = cls if non_coco else yolo_cls_to_ssd[cls]
|
||||||
|
results.append({'image_id': image_id,
|
||||||
|
'category_id': cls,
|
||||||
|
'bbox': [x, y, w, h],
|
||||||
|
'score': float(conf)})
|
||||||
|
with open(results_file, 'w') as f:
|
||||||
|
f.write(json.dumps(results, indent=4))
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
check_args(args)
|
||||||
|
if args.category_num <= 0:
|
||||||
|
raise SystemExit('ERROR: bad category_num (%d)!' % args.category_num)
|
||||||
|
if not os.path.isfile('yolo/%s.trt' % args.model):
|
||||||
|
raise SystemExit('ERROR: file (yolo/%s.trt) not found!' % args.model)
|
||||||
|
|
||||||
|
results_file = 'yolo/results_%s.json' % args.model
|
||||||
|
|
||||||
|
trt_yolo = TrtYOLO(args.model, args.category_num, args.letter_box)
|
||||||
|
|
||||||
|
jpgs = [j for j in os.listdir(args.imgs_dir) if j.endswith('.jpg')]
|
||||||
|
generate_results(trt_yolo, args.imgs_dir, jpgs, results_file,
|
||||||
|
non_coco=args.non_coco)
|
||||||
|
|
||||||
|
# Run COCO mAP evaluation
|
||||||
|
# Reference: https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
|
||||||
|
cocoGt = COCO(args.annotations)
|
||||||
|
cocoDt = cocoGt.loadRes(results_file)
|
||||||
|
imgIds = sorted(cocoGt.getImgIds())
|
||||||
|
cocoEval = COCOeval(cocoGt, cocoDt, 'bbox')
|
||||||
|
cocoEval.params.imgIds = imgIds
|
||||||
|
cocoEval.evaluate()
|
||||||
|
cocoEval.accumulate()
|
||||||
|
cocoEval.summarize()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
OUTNAME_RELEASE = create_engine
|
||||||
|
OUTNAME_DEBUG = create_engine_debug
|
||||||
|
MAKEFILE_CONFIG ?= ../common/Makefile.config
|
||||||
|
include $(MAKEFILE_CONFIG)
|
||||||
|
|
||||||
|
all: release
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
The caffe prototxt and model files in this directory were copied from [BVLC/caffe/models/bvlc_googlenet/](https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet).
|
||||||
|
|
@ -0,0 +1,222 @@
|
||||||
|
// create_engine.cpp
|
||||||
|
//
|
||||||
|
// This program creates TensorRT engine for the GoogLeNet model.
|
||||||
|
//
|
||||||
|
// Inputs:
|
||||||
|
// deploy.prototxt
|
||||||
|
// deploy.caffemodel
|
||||||
|
//
|
||||||
|
// Outputs:
|
||||||
|
// deploy.engine
|
||||||
|
|
||||||
|
#include <assert.h>
|
||||||
|
#include <fstream>
|
||||||
|
#include <sstream>
|
||||||
|
#include <iostream>
|
||||||
|
#include <cmath>
|
||||||
|
#include <algorithm>
|
||||||
|
#include <sys/stat.h>
|
||||||
|
#include <cmath>
|
||||||
|
#include <time.h>
|
||||||
|
#include <cuda_runtime_api.h>
|
||||||
|
|
||||||
|
#include "NvInfer.h"
|
||||||
|
#include "NvCaffeParser.h"
|
||||||
|
#include "common.h"
|
||||||
|
|
||||||
|
using namespace nvinfer1;
|
||||||
|
using namespace nvcaffeparser1;
|
||||||
|
|
||||||
|
//static Logger gLogger(ILogger::Severity::kINFO);
|
||||||
|
static Logger gLogger(ILogger::Severity::kWARNING);
|
||||||
|
|
||||||
|
class IHostMemoryFromFile : public IHostMemory
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
IHostMemoryFromFile(std::string filename);
|
||||||
|
#if NV_TENSORRT_MAJOR >= 6
|
||||||
|
void* data() const noexcept { return mem; }
|
||||||
|
std::size_t size() const noexcept { return s; }
|
||||||
|
DataType type () const noexcept { return DataType::kFLOAT; } // not used
|
||||||
|
void destroy() noexcept { free(mem); }
|
||||||
|
#else // NV_TENSORRT_MAJOR < 6
|
||||||
|
void* data() const { return mem; }
|
||||||
|
std::size_t size() const { return s; }
|
||||||
|
DataType type () const { return DataType::kFLOAT; } // not used
|
||||||
|
void destroy() { free(mem); }
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
private:
|
||||||
|
void *mem{nullptr};
|
||||||
|
std::size_t s;
|
||||||
|
};
|
||||||
|
|
||||||
|
IHostMemoryFromFile::IHostMemoryFromFile(std::string filename)
|
||||||
|
{
|
||||||
|
std::ifstream infile(filename, std::ifstream::binary | std::ifstream::ate);
|
||||||
|
s = infile.tellg();
|
||||||
|
infile.seekg(0, std::ios::beg);
|
||||||
|
mem = malloc(s);
|
||||||
|
infile.read(reinterpret_cast<char*>(mem), s);
|
||||||
|
}
|
||||||
|
|
||||||
|
std::string locateFile(const std::string& input)
|
||||||
|
{
|
||||||
|
std::vector<std::string> dirs{"./"};
|
||||||
|
return locateFile(input, dirs);
|
||||||
|
}
|
||||||
|
|
||||||
|
void caffeToTRTModel(const std::string& deployFile, // name for caffe prototxt
|
||||||
|
const std::string& modelFile, // name for model
|
||||||
|
const std::vector<std::string>& outputs, // network outputs
|
||||||
|
unsigned int maxBatchSize, // batch size - NB must be at least as large as the batch we want to run with)
|
||||||
|
IHostMemory *&trtModelStream)
|
||||||
|
{
|
||||||
|
// create API root class - must span the lifetime of the engine usage
|
||||||
|
IBuilder* builder = createInferBuilder(gLogger);
|
||||||
|
#if NV_TENSORRT_MAJOR >= 7
|
||||||
|
INetworkDefinition* network = builder->createNetworkV2(0); // no kEXPLICIT_BATCH
|
||||||
|
#else // NV_TENSORRT_MAJOR < 7
|
||||||
|
INetworkDefinition* network = builder->createNetwork();
|
||||||
|
#endif
|
||||||
|
|
||||||
|
// parse the caffe model to populate the network, then set the outputs
|
||||||
|
ICaffeParser* parser = createCaffeParser();
|
||||||
|
|
||||||
|
bool useFp16 = builder->platformHasFastFp16();
|
||||||
|
|
||||||
|
// create a 16-bit model if it's natively supported
|
||||||
|
DataType modelDataType = useFp16 ? DataType::kHALF : DataType::kFLOAT;
|
||||||
|
const IBlobNameToTensor *blobNameToTensor =
|
||||||
|
parser->parse(locateFile(deployFile).c_str(), // caffe deploy file
|
||||||
|
locateFile(modelFile).c_str(), // caffe model file
|
||||||
|
*network, // network definition that the parser will populate
|
||||||
|
modelDataType);
|
||||||
|
assert(blobNameToTensor != nullptr);
|
||||||
|
|
||||||
|
// the caffe file has no notion of outputs, so we need to manually say which tensors the engine should generate
|
||||||
|
for (auto& s : outputs)
|
||||||
|
network->markOutput(*blobNameToTensor->find(s.c_str()));
|
||||||
|
|
||||||
|
#if NV_TENSORRT_MAJOR >= 7
|
||||||
|
auto config = builder->createBuilderConfig();
|
||||||
|
assert(config != nullptr);
|
||||||
|
|
||||||
|
builder->setMaxBatchSize(maxBatchSize);
|
||||||
|
config->setMaxWorkspaceSize(64_MB);
|
||||||
|
if (useFp16) {
|
||||||
|
config->setFlag(BuilderFlag::kFP16);
|
||||||
|
cout << "Building TensorRT engine in FP16 mode..." << endl;
|
||||||
|
} else {
|
||||||
|
cout << "Building TensorRT engine in FP32 mode..." << endl;
|
||||||
|
}
|
||||||
|
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
|
||||||
|
config->destroy();
|
||||||
|
#else // NV_TENSORRT_MAJOR < 7
|
||||||
|
// Build the engine
|
||||||
|
builder->setMaxBatchSize(maxBatchSize);
|
||||||
|
builder->setMaxWorkspaceSize(64_MB);
|
||||||
|
|
||||||
|
// set up the network for paired-fp16 format if available
|
||||||
|
if (useFp16) {
|
||||||
|
#if NV_TENSORRT_MAJOR >= 4
|
||||||
|
builder->setFp16Mode(true);
|
||||||
|
#else // NV_TENSORRT_MAJOR < 4
|
||||||
|
builder->setHalf2Mode(true);
|
||||||
|
#endif
|
||||||
|
}
|
||||||
|
ICudaEngine* engine = builder->buildCudaEngine(*network);
|
||||||
|
#endif // NV_TENSORRT_MAJOR >= 7
|
||||||
|
assert(engine != nullptr);
|
||||||
|
|
||||||
|
// we don't need the network any more, and we can destroy the parser
|
||||||
|
parser->destroy();
|
||||||
|
network->destroy();
|
||||||
|
|
||||||
|
// serialize the engine, then close everything down
|
||||||
|
trtModelStream = engine->serialize();
|
||||||
|
engine->destroy();
|
||||||
|
builder->destroy();
|
||||||
|
}
|
||||||
|
|
||||||
|
void giestream_to_file(IHostMemory *trtModelStream, const std::string filename)
|
||||||
|
{
|
||||||
|
assert(trtModelStream != nullptr);
|
||||||
|
std::ofstream outfile(filename, std::ofstream::binary);
|
||||||
|
assert(!outfile.fail());
|
||||||
|
outfile.write(reinterpret_cast<char*>(trtModelStream->data()), trtModelStream->size());
|
||||||
|
outfile.close();
|
||||||
|
}
|
||||||
|
|
||||||
|
void file_to_giestream(const std::string filename, IHostMemoryFromFile *&trtModelStream)
|
||||||
|
{
|
||||||
|
trtModelStream = new IHostMemoryFromFile(filename);
|
||||||
|
}
|
||||||
|
|
||||||
|
void verify_engine(std::string det_name)
|
||||||
|
{
|
||||||
|
std::stringstream ss;
|
||||||
|
ss << det_name << ".engine";
|
||||||
|
IHostMemoryFromFile *trtModelStream{nullptr};
|
||||||
|
file_to_giestream(ss.str(), trtModelStream);
|
||||||
|
|
||||||
|
// create an engine
|
||||||
|
IRuntime* infer = createInferRuntime(gLogger);
|
||||||
|
assert(infer != nullptr);
|
||||||
|
ICudaEngine* engine = infer->deserializeCudaEngine(
|
||||||
|
trtModelStream->data(),
|
||||||
|
trtModelStream->size(),
|
||||||
|
nullptr);
|
||||||
|
assert(engine != nullptr);
|
||||||
|
|
||||||
|
assert(engine->getNbBindings() == 2);
|
||||||
|
std::cout << "Bindings for " << det_name << " after deserializing:"
|
||||||
|
<< std::endl;
|
||||||
|
for (int bi = 0; bi < 2; bi++) {
|
||||||
|
#if NV_TENSORRT_MAJOR >= 4
|
||||||
|
Dims3 dim = static_cast<Dims3&&>(engine->getBindingDimensions(bi));
|
||||||
|
if (engine->bindingIsInput(bi) == true) {
|
||||||
|
std::cout << " Input ";
|
||||||
|
} else {
|
||||||
|
std::cout << " Output ";
|
||||||
|
}
|
||||||
|
std::cout << bi << ": " << engine->getBindingName(bi) << ", "
|
||||||
|
<< dim.d[0] << "x" << dim.d[1] << "x" << dim.d[2]
|
||||||
|
<< std::endl;
|
||||||
|
#else // NV_TENSORRT_MAJOR < 4
|
||||||
|
DimsCHW dim = static_cast<DimsCHW&&>(engine->getBindingDimensions(bi));
|
||||||
|
if (engine->bindingIsInput(bi) == true) {
|
||||||
|
std::cout << " Input ";
|
||||||
|
} else {
|
||||||
|
std::cout << " Output ";
|
||||||
|
}
|
||||||
|
std::cout << bi << ": " << engine->getBindingName(bi) << ", "
|
||||||
|
<< dim.c() << "x" << dim.h() << "x" << dim.w()
|
||||||
|
<< std::endl;
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
}
|
||||||
|
engine->destroy();
|
||||||
|
infer->destroy();
|
||||||
|
trtModelStream->destroy();
|
||||||
|
}
|
||||||
|
|
||||||
|
int main(int argc, char** argv)
|
||||||
|
{
|
||||||
|
IHostMemory *trtModelStream{nullptr};
|
||||||
|
|
||||||
|
std::cout << "Building deploy.engine, maxBatchSize = 1" << std::endl;
|
||||||
|
caffeToTRTModel("deploy.prototxt",
|
||||||
|
"deploy.caffemodel",
|
||||||
|
std::vector <std::string> { "prob" },
|
||||||
|
1, // batch size
|
||||||
|
trtModelStream);
|
||||||
|
giestream_to_file(trtModelStream, "deploy.engine");
|
||||||
|
trtModelStream->destroy();
|
||||||
|
//delete trtModelStream;
|
||||||
|
|
||||||
|
shutdownProtobufLibrary();
|
||||||
|
|
||||||
|
std::cout << std::endl << "Verifying engine..." << std::endl;
|
||||||
|
verify_engine("deploy");
|
||||||
|
std::cout << "Done." << std::endl;
|
||||||
|
return 0;
|
||||||
|
}
|
||||||
Binary file not shown.
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,51 @@
|
||||||
|
# How to convert the original PyTorch MODNet model to ONNX
|
||||||
|
|
||||||
|
The original pre-trained PyTorch MODNet model comes from [ZHKKKe/MODNet](https://github.com/ZHKKKe/MODNet). Note that this pre-trained model is under [Creative Commons Attribution NonCommercial ShareAlike 4.0 license](https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
|
||||||
|
|
||||||
|
You could use the script in this repository to convert the original PyTorch model to ONNX. I recommend to do such conversion within a python3 virtual environment, since you'd need to use some specific versions of pip3 packages. Below is a step-by-step guide about how to build the python3 virtual environment and then convert the PyTorch MODNet model to ONNX.
|
||||||
|
|
||||||
|
1. Make sure python3 "venv" module is installed.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ sudo apt install python3-venv
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Create a virtual environment named "venv-onnx" and activate it.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ cd ${HOME}/project/tensorrt_demos/modnet
|
||||||
|
$ python3 -m venv venv-onnx
|
||||||
|
$ source venv-onnx/bin/activate
|
||||||
|
```
|
||||||
|
|
||||||
|
At this point, you should have entered the virtual environment and would see shell prompt proceeded with "(venv-onnx) ". You could do `deactivate` to quit the virtual environment when you are done using it.
|
||||||
|
|
||||||
|
Download "torch-1.7.0-cp36-cp36m-linux_aarch64.whl" from here: [PyTorch for Jetson](https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-8-0-now-available/72048). Then install all required packages into the virtual environment. (Note the following should be done inside the "venv-onnx" virtual environment.)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
### update pip to the latest version in the virtual env
|
||||||
|
$ curl https://bootstrap.pypa.io/get-pip.py | python
|
||||||
|
### udpate these essential packages
|
||||||
|
$ python -m pip install -U setuptools Cython
|
||||||
|
### I recommend numpy 1.16.x on Jetson
|
||||||
|
$ python -m pip install "numpy<1.17.0"
|
||||||
|
### install cv2 into the virtual env
|
||||||
|
$ cp -r /usr/lib/python3.6/dist-packages/cv2 venv-onnx/lib/python3.6/site-packages/
|
||||||
|
### install PyImage, onnx and onnxruntime
|
||||||
|
$ python -m pip install PyImage onnx==1.8.1 onnxruntime==1.6.0
|
||||||
|
### install PyTorch v1.7.0
|
||||||
|
$ sudo apt install libopenblas-base libopenmpi-dev
|
||||||
|
$ python -m pip install ${HOME}/Downloads/torch-1.7.0-cp36-cp36m-linux_aarch64.whl
|
||||||
|
```
|
||||||
|
|
||||||
|
In addition, you might also install [onnx-graphsurgeon](https://pypi.org/project/onnx-graphsurgeon/) and [polygraphy](https://pypi.org/project/polygraphy/) for debugging. Otherwise, you could do some simple testing to make sure "onnx" and "torch" are working OK in the virtual env.
|
||||||
|
|
||||||
|
3. Download the pre-trained MODNet model (PyTorch checkpoint file) from the link on this page: [/ZHKKKe/MODNet/pretrained](https://github.com/ZHKKKe/MODNet/tree/master/pretrained). I recommend using "modnet_webcam_portrait_matting.ckpt". Just put the file in the current directory.
|
||||||
|
|
||||||
|
4. Do the conversion using the following command. The ouput "modnet.onnx" would be generated.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
$ python -m torch2onnx.export modnet_webcam_portrait_matting.ckpt modnet.onnx
|
||||||
|
```
|
||||||
|
|
||||||
|
By default, the "torch2onnx.export" script sets input image width and height to 512x288. They could be modified by the "--width" and "--height" command-line options. In addition, the "-v" command-line option could be used to enable verbose logs of `torch.onnx.export()`.
|
||||||
|
|
@ -0,0 +1,43 @@
|
||||||
|
#!/bin/bash
|
||||||
|
#
|
||||||
|
# Reference for installing 'pycuda': https://wiki.tiker.net/PyCuda/Installation/Linux/Ubuntu
|
||||||
|
|
||||||
|
set -e
|
||||||
|
|
||||||
|
if ! which nvcc > /dev/null; then
|
||||||
|
echo "ERROR: nvcc not found"
|
||||||
|
exit
|
||||||
|
fi
|
||||||
|
|
||||||
|
arch=$(uname -m)
|
||||||
|
folder=${HOME}/src
|
||||||
|
mkdir -p $folder
|
||||||
|
|
||||||
|
echo "** Install requirements"
|
||||||
|
sudo apt-get install -y build-essential python3-dev
|
||||||
|
sudo apt-get install -y libboost-python-dev libboost-thread-dev
|
||||||
|
sudo pip3 install setuptools
|
||||||
|
|
||||||
|
boost_pylib=$(basename /usr/lib/${arch}-linux-gnu/libboost_python*-py3?.so)
|
||||||
|
boost_pylibname=${boost_pylib%.so}
|
||||||
|
boost_pyname=${boost_pylibname/lib/}
|
||||||
|
|
||||||
|
echo "** Download pycuda-2019.1.2 sources"
|
||||||
|
pushd $folder
|
||||||
|
if [ ! -f pycuda-2019.1.2.tar.gz ]; then
|
||||||
|
wget https://files.pythonhosted.org/packages/5e/3f/5658c38579b41866ba21ee1b5020b8225cec86fe717e4b1c5c972de0a33c/pycuda-2019.1.2.tar.gz
|
||||||
|
fi
|
||||||
|
|
||||||
|
echo "** Build and install pycuda-2019.1.2"
|
||||||
|
CPU_CORES=$(nproc)
|
||||||
|
echo "** cpu cores available: " $CPU_CORES
|
||||||
|
tar xzvf pycuda-2019.1.2.tar.gz
|
||||||
|
cd pycuda-2019.1.2
|
||||||
|
python3 ./configure.py --python-exe=/usr/bin/python3 --cuda-root=/usr/local/cuda --cudadrv-lib-dir=/usr/lib/${arch}-linux-gnu --boost-inc-dir=/usr/include --boost-lib-dir=/usr/lib/${arch}-linux-gnu --boost-python-libname=${boost_pyname} --boost-thread-libname=boost_thread --no-use-shipped-boost
|
||||||
|
make -j$CPU_CORES
|
||||||
|
python3 setup.py build
|
||||||
|
sudo python3 setup.py install
|
||||||
|
|
||||||
|
popd
|
||||||
|
|
||||||
|
python3 -c "import pycuda; print('pycuda version:', pycuda.VERSION)"
|
||||||
|
|
@ -0,0 +1,117 @@
|
||||||
|
"""onnx_to_tensorrt.py
|
||||||
|
|
||||||
|
For converting a MODNet ONNX model to a TensorRT engine.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import tensorrt as trt
|
||||||
|
|
||||||
|
if trt.__version__[0] < '7':
|
||||||
|
raise SystemExit('TensorRT version < 7')
|
||||||
|
|
||||||
|
|
||||||
|
BATCH_SIZE = 1
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse command-line options and arguments."""
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument(
|
||||||
|
'-v', '--verbose', action='store_true',
|
||||||
|
help='enable verbose output (for debugging) [False]')
|
||||||
|
parser.add_argument(
|
||||||
|
'--int8', action='store_true',
|
||||||
|
help='build INT8 TensorRT engine [False]')
|
||||||
|
parser.add_argument(
|
||||||
|
'--dla_core', type=int, default=-1,
|
||||||
|
help='id of DLA core for inference, ranging from 0 to N-1 [-1]')
|
||||||
|
parser.add_argument(
|
||||||
|
'--width', type=int, default=640,
|
||||||
|
help='input image width of the model [640]')
|
||||||
|
parser.add_argument(
|
||||||
|
'--height', type=int, default=480,
|
||||||
|
help='input image height of the model [480]')
|
||||||
|
parser.add_argument(
|
||||||
|
'input_onnx', type=str, help='the input onnx file')
|
||||||
|
parser.add_argument(
|
||||||
|
'output_engine', type=str, help='the output TensorRT engine file')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def load_onnx(onnx_file_path):
|
||||||
|
"""Read the ONNX file."""
|
||||||
|
with open(onnx_file_path, 'rb') as f:
|
||||||
|
return f.read()
|
||||||
|
|
||||||
|
|
||||||
|
def set_net_batch(network, batch_size):
|
||||||
|
"""Set network input batch size."""
|
||||||
|
shape = list(network.get_input(0).shape)
|
||||||
|
shape[0] = batch_size
|
||||||
|
network.get_input(0).shape = shape
|
||||||
|
return network
|
||||||
|
|
||||||
|
|
||||||
|
def build_engine(onnx_file_path, width, height,
|
||||||
|
do_int8=False, dla_core=False, verbose=False):
|
||||||
|
"""Build a TensorRT engine from ONNX using the older API."""
|
||||||
|
onnx_data = load_onnx(onnx_file_path)
|
||||||
|
|
||||||
|
TRT_LOGGER = trt.Logger(trt.Logger.VERBOSE) if verbose else trt.Logger()
|
||||||
|
EXPLICIT_BATCH = [1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)]
|
||||||
|
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(*EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
|
||||||
|
if do_int8 and not builder.platform_has_fast_int8:
|
||||||
|
raise RuntimeError('INT8 not supported on this platform')
|
||||||
|
if not parser.parse(onnx_data):
|
||||||
|
print('ERROR: Failed to parse the ONNX file.')
|
||||||
|
for error in range(parser.num_errors):
|
||||||
|
print(parser.get_error(error))
|
||||||
|
return None
|
||||||
|
network = set_net_batch(network, BATCH_SIZE)
|
||||||
|
|
||||||
|
builder.max_batch_size = BATCH_SIZE
|
||||||
|
config = builder.create_builder_config()
|
||||||
|
config.max_workspace_size = 1 << 30
|
||||||
|
config.set_flag(trt.BuilderFlag.GPU_FALLBACK)
|
||||||
|
config.set_flag(trt.BuilderFlag.FP16)
|
||||||
|
profile = builder.create_optimization_profile()
|
||||||
|
profile.set_shape(
|
||||||
|
'Input', # input tensor name
|
||||||
|
(BATCH_SIZE, 3, height, width), # min shape
|
||||||
|
(BATCH_SIZE, 3, height, width), # opt shape
|
||||||
|
(BATCH_SIZE, 3, height, width)) # max shape
|
||||||
|
config.add_optimization_profile(profile)
|
||||||
|
if do_int8:
|
||||||
|
raise RuntimeError('INT8 not implemented yet')
|
||||||
|
if dla_core >= 0:
|
||||||
|
raise RuntimeError('DLA_core not implemented yet')
|
||||||
|
engine = builder.build_engine(network, config)
|
||||||
|
|
||||||
|
return engine
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
if not os.path.isfile(args.input_onnx):
|
||||||
|
raise FileNotFoundError(args.input_onnx)
|
||||||
|
|
||||||
|
print('Building an engine. This would take a while...')
|
||||||
|
print('(Use "-v" or "--verbose" to enable verbose logging.)')
|
||||||
|
engine = build_engine(
|
||||||
|
args.input_onnx, args.width, args.height,
|
||||||
|
args.int8, args.dla_core, args.verbose)
|
||||||
|
if engine is None:
|
||||||
|
raise SystemExit('ERROR: failed to build the TensorRT engine!')
|
||||||
|
print('Completed creating engine.')
|
||||||
|
|
||||||
|
with open(args.output_engine, 'wb') as f:
|
||||||
|
f.write(engine.serialize())
|
||||||
|
print('Serialized the TensorRT engine to file: %s' % args.output_engine)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,29 @@
|
||||||
|
"""run_onnx.py
|
||||||
|
|
||||||
|
A simple script for verifying the modnet.onnx model.
|
||||||
|
|
||||||
|
I used the following image for testing:
|
||||||
|
$ gdown --id 1fkyh03NEuSwvjFttYVwV7TjnJML04Xn6 -O image.jpg
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
import onnx
|
||||||
|
import onnxruntime
|
||||||
|
|
||||||
|
img = cv2.imread('image.jpg')
|
||||||
|
img = cv2.resize(img, (512, 288), cv2.INTER_AREA)
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
||||||
|
img = img.transpose((2, 0, 1)).astype(np.float32)
|
||||||
|
img = (img - 127.5) / 127.5
|
||||||
|
img = np.expand_dims(img, axis=0)
|
||||||
|
|
||||||
|
session = onnxruntime.InferenceSession('modnet.onnx', None)
|
||||||
|
input_name = session.get_inputs()[0].name
|
||||||
|
output_name = session.get_outputs()[0].name
|
||||||
|
result = session.run([output_name], {input_name: img})
|
||||||
|
matte = np.squeeze(result[0])
|
||||||
|
cv2.imshow('Matte', (matte * 255.).astype(np.uint8))
|
||||||
|
cv2.waitKey(0)
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
@ -0,0 +1,87 @@
|
||||||
|
"""backbone.py
|
||||||
|
|
||||||
|
This is a copy of:
|
||||||
|
https://github.com/ZHKKKe/MODNet/blob/master/src/models/backbones/wrapper.py
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
from functools import reduce
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
|
||||||
|
from .mobilenetv2 import MobileNetV2
|
||||||
|
|
||||||
|
|
||||||
|
class BaseBackbone(nn.Module):
|
||||||
|
"""Superclass of Replaceable Backbone Model for Semantic Estimation"""
|
||||||
|
|
||||||
|
def __init__(self, in_channels):
|
||||||
|
super(BaseBackbone, self).__init__()
|
||||||
|
self.in_channels = in_channels
|
||||||
|
|
||||||
|
self.model = None
|
||||||
|
self.enc_channels = []
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def load_pretrained_ckpt(self):
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
|
class MobileNetV2Backbone(BaseBackbone):
|
||||||
|
"""MobileNetV2 Backbone"""
|
||||||
|
|
||||||
|
def __init__(self, in_channels):
|
||||||
|
super(MobileNetV2Backbone, self).__init__(in_channels)
|
||||||
|
|
||||||
|
self.model = MobileNetV2(self.in_channels, alpha=1.0, expansion=6, num_classes=None)
|
||||||
|
self.enc_channels = [16, 24, 32, 96, 1280]
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
# x = reduce(lambda x, n: self.model.features[n](x), list(range(0, 2)), x)
|
||||||
|
x = self.model.features[0](x)
|
||||||
|
x = self.model.features[1](x)
|
||||||
|
enc2x = x
|
||||||
|
|
||||||
|
# x = reduce(lambda x, n: self.model.features[n](x), list(range(2, 4)), x)
|
||||||
|
x = self.model.features[2](x)
|
||||||
|
x = self.model.features[3](x)
|
||||||
|
enc4x = x
|
||||||
|
|
||||||
|
# x = reduce(lambda x, n: self.model.features[n](x), list(range(4, 7)), x)
|
||||||
|
x = self.model.features[4](x)
|
||||||
|
x = self.model.features[5](x)
|
||||||
|
x = self.model.features[6](x)
|
||||||
|
enc8x = x
|
||||||
|
|
||||||
|
# x = reduce(lambda x, n: self.model.features[n](x), list(range(7, 14)), x)
|
||||||
|
x = self.model.features[7](x)
|
||||||
|
x = self.model.features[8](x)
|
||||||
|
x = self.model.features[9](x)
|
||||||
|
x = self.model.features[10](x)
|
||||||
|
x = self.model.features[11](x)
|
||||||
|
x = self.model.features[12](x)
|
||||||
|
x = self.model.features[13](x)
|
||||||
|
enc16x = x
|
||||||
|
|
||||||
|
# x = reduce(lambda x, n: self.model.features[n](x), list(range(14, 19)), x)
|
||||||
|
x = self.model.features[14](x)
|
||||||
|
x = self.model.features[15](x)
|
||||||
|
x = self.model.features[16](x)
|
||||||
|
x = self.model.features[17](x)
|
||||||
|
x = self.model.features[18](x)
|
||||||
|
enc32x = x
|
||||||
|
return [enc2x, enc4x, enc8x, enc16x, enc32x]
|
||||||
|
|
||||||
|
def load_pretrained_ckpt(self):
|
||||||
|
# the pre-trained model is provided by https://github.com/thuyngch/Human-Segmentation-PyTorch
|
||||||
|
ckpt_path = './pretrained/mobilenetv2_human_seg.ckpt'
|
||||||
|
if not os.path.exists(ckpt_path):
|
||||||
|
print('cannot find the pretrained mobilenetv2 backbone')
|
||||||
|
exit()
|
||||||
|
|
||||||
|
ckpt = torch.load(ckpt_path)
|
||||||
|
self.model.load_state_dict(ckpt)
|
||||||
|
|
@ -0,0 +1,63 @@
|
||||||
|
"""export.py
|
||||||
|
|
||||||
|
This script is an adatped copy of:
|
||||||
|
https://github.com/ZHKKKe/MODNet/blob/master/onnx/export_onnx.py
|
||||||
|
|
||||||
|
This script is for converting a PyTorch MODNet model to ONNX. The
|
||||||
|
output ONNX model will have fixed batch size (1) and input image
|
||||||
|
width/height. The input image width and height could be specified
|
||||||
|
by command-line options (default to 512x288).
|
||||||
|
|
||||||
|
Example usage: (Recommended to run this inside a virtual environment)
|
||||||
|
$ python export.py --width 512 --height 288 \
|
||||||
|
modnet_photographic_portrait_matting.ckpt \
|
||||||
|
modnet.onnx
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from torch.autograd import Variable
|
||||||
|
|
||||||
|
from .modnet import MODNet
|
||||||
|
|
||||||
|
|
||||||
|
BATCH_SIZE = 1
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument(
|
||||||
|
'--width', type=int, default=512,
|
||||||
|
help='image width of the converted ONNX model [512]')
|
||||||
|
parser.add_argument(
|
||||||
|
'--height', type=int, default=288,
|
||||||
|
help='image width of the converted ONNX model [288]')
|
||||||
|
parser.add_argument(
|
||||||
|
'-v', '--verbose', action='store_true',
|
||||||
|
help='enable verbose logging [False]')
|
||||||
|
parser.add_argument(
|
||||||
|
'input_ckpt', type=str, help='the input PyTorch checkpoint file path')
|
||||||
|
parser.add_argument(
|
||||||
|
'output_onnx', type=str, help='the output ONNX file path')
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
if not os.path.isfile(args.input_ckpt):
|
||||||
|
raise SystemExit('ERROR: file (%s) not found!' % args.input_ckpt)
|
||||||
|
|
||||||
|
# define model & load checkpoint
|
||||||
|
modnet = torch.nn.DataParallel(MODNet()).cuda()
|
||||||
|
modnet.load_state_dict(torch.load(args.input_ckpt))
|
||||||
|
modnet.eval()
|
||||||
|
|
||||||
|
# prepare dummy input
|
||||||
|
dummy_img = torch.rand(BATCH_SIZE, 3, args.height, args.width) * 2. - 1.
|
||||||
|
dummy_img = dummy_img.cuda()
|
||||||
|
|
||||||
|
# export to onnx model
|
||||||
|
torch.onnx.export(
|
||||||
|
modnet.module, dummy_img, args.output_onnx,
|
||||||
|
opset_version=11, export_params=True, verbose=args.verbose,
|
||||||
|
input_names=['input'], output_names=['output'])
|
||||||
|
|
@ -0,0 +1,204 @@
|
||||||
|
"""mobilenetv2.py
|
||||||
|
|
||||||
|
This is a copy of:
|
||||||
|
https://github.com/ZHKKKe/MODNet/blob/master/src/models/backbones/mobilenetv2.py
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import math
|
||||||
|
import json
|
||||||
|
from functools import reduce
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from torch import nn
|
||||||
|
|
||||||
|
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
# Useful functions
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
def _make_divisible(v, divisor, min_value=None):
|
||||||
|
if min_value is None:
|
||||||
|
min_value = divisor
|
||||||
|
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
|
||||||
|
# Make sure that round down does not go down by more than 10%.
|
||||||
|
if new_v < 0.9 * v:
|
||||||
|
new_v += divisor
|
||||||
|
return new_v
|
||||||
|
|
||||||
|
|
||||||
|
def conv_bn(inp, oup, stride):
|
||||||
|
return nn.Sequential(
|
||||||
|
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
|
||||||
|
nn.BatchNorm2d(oup),
|
||||||
|
nn.ReLU6(inplace=True)
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def conv_1x1_bn(inp, oup):
|
||||||
|
return nn.Sequential(
|
||||||
|
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
|
||||||
|
nn.BatchNorm2d(oup),
|
||||||
|
nn.ReLU6(inplace=True)
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
# Class of Inverted Residual block
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
class InvertedResidual(nn.Module):
|
||||||
|
def __init__(self, inp, oup, stride, expansion, dilation=1):
|
||||||
|
super(InvertedResidual, self).__init__()
|
||||||
|
self.stride = stride
|
||||||
|
assert stride in [1, 2]
|
||||||
|
|
||||||
|
hidden_dim = round(inp * expansion)
|
||||||
|
self.use_res_connect = self.stride == 1 and inp == oup
|
||||||
|
|
||||||
|
if expansion == 1:
|
||||||
|
self.conv = nn.Sequential(
|
||||||
|
# dw
|
||||||
|
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, dilation=dilation, bias=False),
|
||||||
|
nn.BatchNorm2d(hidden_dim),
|
||||||
|
nn.ReLU6(inplace=True),
|
||||||
|
# pw-linear
|
||||||
|
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
|
||||||
|
nn.BatchNorm2d(oup),
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
self.conv = nn.Sequential(
|
||||||
|
# pw
|
||||||
|
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
|
||||||
|
nn.BatchNorm2d(hidden_dim),
|
||||||
|
nn.ReLU6(inplace=True),
|
||||||
|
# dw
|
||||||
|
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, dilation=dilation, bias=False),
|
||||||
|
nn.BatchNorm2d(hidden_dim),
|
||||||
|
nn.ReLU6(inplace=True),
|
||||||
|
# pw-linear
|
||||||
|
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
|
||||||
|
nn.BatchNorm2d(oup),
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
if self.use_res_connect:
|
||||||
|
return x + self.conv(x)
|
||||||
|
else:
|
||||||
|
return self.conv(x)
|
||||||
|
|
||||||
|
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
# Class of MobileNetV2
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
class MobileNetV2(nn.Module):
|
||||||
|
def __init__(self, in_channels, alpha=1.0, expansion=6, num_classes=1000):
|
||||||
|
super(MobileNetV2, self).__init__()
|
||||||
|
self.in_channels = in_channels
|
||||||
|
self.num_classes = num_classes
|
||||||
|
input_channel = 32
|
||||||
|
last_channel = 1280
|
||||||
|
interverted_residual_setting = [
|
||||||
|
# t, c, n, s
|
||||||
|
[1 , 16, 1, 1],
|
||||||
|
[expansion, 24, 2, 2],
|
||||||
|
[expansion, 32, 3, 2],
|
||||||
|
[expansion, 64, 4, 2],
|
||||||
|
[expansion, 96, 3, 1],
|
||||||
|
[expansion, 160, 3, 2],
|
||||||
|
[expansion, 320, 1, 1],
|
||||||
|
]
|
||||||
|
|
||||||
|
# building first layer
|
||||||
|
input_channel = _make_divisible(input_channel*alpha, 8)
|
||||||
|
self.last_channel = _make_divisible(last_channel*alpha, 8) if alpha > 1.0 else last_channel
|
||||||
|
self.features = [conv_bn(self.in_channels, input_channel, 2)]
|
||||||
|
|
||||||
|
# building inverted residual blocks
|
||||||
|
for t, c, n, s in interverted_residual_setting:
|
||||||
|
output_channel = _make_divisible(int(c*alpha), 8)
|
||||||
|
for i in range(n):
|
||||||
|
if i == 0:
|
||||||
|
self.features.append(InvertedResidual(input_channel, output_channel, s, expansion=t))
|
||||||
|
else:
|
||||||
|
self.features.append(InvertedResidual(input_channel, output_channel, 1, expansion=t))
|
||||||
|
input_channel = output_channel
|
||||||
|
|
||||||
|
# building last several layers
|
||||||
|
self.features.append(conv_1x1_bn(input_channel, self.last_channel))
|
||||||
|
|
||||||
|
# make it nn.Sequential
|
||||||
|
self.features = nn.Sequential(*self.features)
|
||||||
|
|
||||||
|
# building classifier
|
||||||
|
if self.num_classes is not None:
|
||||||
|
self.classifier = nn.Sequential(
|
||||||
|
nn.Dropout(0.2),
|
||||||
|
nn.Linear(self.last_channel, num_classes),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Initialize weights
|
||||||
|
self._init_weights()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
# Stage1
|
||||||
|
x = self.features[0](x)
|
||||||
|
x = self.features[1](x)
|
||||||
|
# Stage2
|
||||||
|
x = self.features[2](x)
|
||||||
|
x = self.features[3](x)
|
||||||
|
# Stage3
|
||||||
|
x = self.features[4](x)
|
||||||
|
x = self.features[5](x)
|
||||||
|
x = self.features[6](x)
|
||||||
|
# Stage4
|
||||||
|
x = self.features[7](x)
|
||||||
|
x = self.features[8](x)
|
||||||
|
x = self.features[9](x)
|
||||||
|
x = self.features[10](x)
|
||||||
|
x = self.features[11](x)
|
||||||
|
x = self.features[12](x)
|
||||||
|
x = self.features[13](x)
|
||||||
|
# Stage5
|
||||||
|
x = self.features[14](x)
|
||||||
|
x = self.features[15](x)
|
||||||
|
x = self.features[16](x)
|
||||||
|
x = self.features[17](x)
|
||||||
|
x = self.features[18](x)
|
||||||
|
|
||||||
|
# Classification
|
||||||
|
if self.num_classes is not None:
|
||||||
|
x = x.mean(dim=(2,3))
|
||||||
|
x = self.classifier(x)
|
||||||
|
|
||||||
|
# Output
|
||||||
|
return x
|
||||||
|
|
||||||
|
def _load_pretrained_model(self, pretrained_file):
|
||||||
|
pretrain_dict = torch.load(pretrained_file, map_location='cpu')
|
||||||
|
model_dict = {}
|
||||||
|
state_dict = self.state_dict()
|
||||||
|
print("[MobileNetV2] Loading pretrained model...")
|
||||||
|
for k, v in pretrain_dict.items():
|
||||||
|
if k in state_dict:
|
||||||
|
model_dict[k] = v
|
||||||
|
else:
|
||||||
|
print(k, "is ignored")
|
||||||
|
state_dict.update(model_dict)
|
||||||
|
self.load_state_dict(state_dict)
|
||||||
|
|
||||||
|
def _init_weights(self):
|
||||||
|
for m in self.modules():
|
||||||
|
if isinstance(m, nn.Conv2d):
|
||||||
|
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
||||||
|
m.weight.data.normal_(0, math.sqrt(2. / n))
|
||||||
|
if m.bias is not None:
|
||||||
|
m.bias.data.zero_()
|
||||||
|
elif isinstance(m, nn.BatchNorm2d):
|
||||||
|
m.weight.data.fill_(1)
|
||||||
|
m.bias.data.zero_()
|
||||||
|
elif isinstance(m, nn.Linear):
|
||||||
|
n = m.weight.size(1)
|
||||||
|
m.weight.data.normal_(0, 0.01)
|
||||||
|
m.bias.data.zero_()
|
||||||
|
|
@ -0,0 +1,248 @@
|
||||||
|
"""modnet.py
|
||||||
|
|
||||||
|
This is a modified version of:
|
||||||
|
https://github.com/ZHKKKe/MODNet/blob/master/onnx/modnet_onnx.py
|
||||||
|
|
||||||
|
* "scale_factor" replaced by "size" in all F.interpolate()
|
||||||
|
* SEBlock takes only 1 "channels" argument
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
from .backbone import MobileNetV2Backbone
|
||||||
|
|
||||||
|
|
||||||
|
SUPPORTED_BACKBONES = {'mobilenetv2': MobileNetV2Backbone}
|
||||||
|
|
||||||
|
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
# MODNet Basic Modules
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
class IBNorm(nn.Module):
|
||||||
|
"""Combine Instance Norm and Batch Norm into One Layer"""
|
||||||
|
|
||||||
|
def __init__(self, in_channels):
|
||||||
|
super(IBNorm, self).__init__()
|
||||||
|
assert in_channels % 2 == 0
|
||||||
|
self.bnorm_channels = in_channels // 2
|
||||||
|
self.inorm_channels = in_channels - self.bnorm_channels
|
||||||
|
|
||||||
|
self.bnorm = nn.BatchNorm2d(self.bnorm_channels, affine=True)
|
||||||
|
self.inorm = nn.InstanceNorm2d(self.inorm_channels, affine=False)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
bn_x = self.bnorm(x[:, :self.bnorm_channels, ...].contiguous())
|
||||||
|
in_x = self.inorm(x[:, self.bnorm_channels:, ...].contiguous())
|
||||||
|
|
||||||
|
return torch.cat((bn_x, in_x), 1)
|
||||||
|
|
||||||
|
|
||||||
|
class Conv2dIBNormRelu(nn.Module):
|
||||||
|
"""Convolution + IBNorm + ReLu"""
|
||||||
|
|
||||||
|
def __init__(self, in_channels, out_channels, kernel_size,
|
||||||
|
stride=1, padding=0, dilation=1, groups=1, bias=True,
|
||||||
|
with_ibn=True, with_relu=True):
|
||||||
|
super(Conv2dIBNormRelu, self).__init__()
|
||||||
|
|
||||||
|
layers = [
|
||||||
|
nn.Conv2d(in_channels, out_channels, kernel_size,
|
||||||
|
stride=stride, padding=padding, dilation=dilation,
|
||||||
|
groups=groups, bias=bias)
|
||||||
|
]
|
||||||
|
|
||||||
|
if with_ibn:
|
||||||
|
layers.append(IBNorm(out_channels))
|
||||||
|
if with_relu:
|
||||||
|
layers.append(nn.ReLU(inplace=True))
|
||||||
|
|
||||||
|
self.layers = nn.Sequential(*layers)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return self.layers(x)
|
||||||
|
|
||||||
|
|
||||||
|
class SEBlock(nn.Module):
|
||||||
|
"""SE Block as proposed in https://arxiv.org/pdf/1709.01507.pdf"""
|
||||||
|
|
||||||
|
def __init__(self, channels, reduction=1):
|
||||||
|
super(SEBlock, self).__init__()
|
||||||
|
self.channels = channels
|
||||||
|
self.pool = nn.AdaptiveAvgPool2d(1)
|
||||||
|
self.fc = nn.Sequential(
|
||||||
|
nn.Linear(channels, channels // reduction, bias=False),
|
||||||
|
nn.ReLU(inplace=True),
|
||||||
|
nn.Linear(channels // reduction, channels, bias=False),
|
||||||
|
nn.Sigmoid()
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
b = x.size()[0]
|
||||||
|
w = self.pool(x).view(b, self.channels)
|
||||||
|
w = self.fc(w).view(b, self.channels, 1, 1)
|
||||||
|
return x * w
|
||||||
|
|
||||||
|
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
# MODNet Branches
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
class LRBranch(nn.Module):
|
||||||
|
"""Low Resolution Branch of MODNet"""
|
||||||
|
|
||||||
|
def __init__(self, backbone):
|
||||||
|
super(LRBranch, self).__init__()
|
||||||
|
|
||||||
|
enc_channels = backbone.enc_channels
|
||||||
|
|
||||||
|
self.backbone = backbone
|
||||||
|
self.se_block = SEBlock(enc_channels[4], reduction=4)
|
||||||
|
self.conv_lr16x = Conv2dIBNormRelu(enc_channels[4], enc_channels[3], 5, stride=1, padding=2)
|
||||||
|
self.conv_lr8x = Conv2dIBNormRelu(enc_channels[3], enc_channels[2], 5, stride=1, padding=2)
|
||||||
|
self.conv_lr = Conv2dIBNormRelu(enc_channels[2], 1, kernel_size=3, stride=2, padding=1, with_ibn=False, with_relu=False)
|
||||||
|
|
||||||
|
def forward(self, img):
|
||||||
|
enc_features = self.backbone.forward(img)
|
||||||
|
enc2x, enc4x, enc32x = enc_features[0], enc_features[1], enc_features[4]
|
||||||
|
|
||||||
|
enc32x = self.se_block(enc32x)
|
||||||
|
h, w = enc32x.size()[2:] # replacing "scale_factor"
|
||||||
|
lr16x = F.interpolate(enc32x, size=(h*2, w*2), mode='bilinear', align_corners=False)
|
||||||
|
lr16x = self.conv_lr16x(lr16x)
|
||||||
|
h, w = lr16x.size()[2:] # replacing "scale_factor"
|
||||||
|
lr8x = F.interpolate(lr16x, size=(h*2, w*2), mode='bilinear', align_corners=False)
|
||||||
|
lr8x = self.conv_lr8x(lr8x)
|
||||||
|
|
||||||
|
return lr8x, [enc2x, enc4x]
|
||||||
|
|
||||||
|
|
||||||
|
class HRBranch(nn.Module):
|
||||||
|
"""High Resolution Branch of MODNet"""
|
||||||
|
|
||||||
|
def __init__(self, hr_channels, enc_channels):
|
||||||
|
super(HRBranch, self).__init__()
|
||||||
|
|
||||||
|
self.tohr_enc2x = Conv2dIBNormRelu(enc_channels[0], hr_channels, 1, stride=1, padding=0)
|
||||||
|
self.conv_enc2x = Conv2dIBNormRelu(hr_channels + 3, hr_channels, 3, stride=2, padding=1)
|
||||||
|
|
||||||
|
self.tohr_enc4x = Conv2dIBNormRelu(enc_channels[1], hr_channels, 1, stride=1, padding=0)
|
||||||
|
self.conv_enc4x = Conv2dIBNormRelu(2 * hr_channels, 2 * hr_channels, 3, stride=1, padding=1)
|
||||||
|
|
||||||
|
self.conv_hr4x = nn.Sequential(
|
||||||
|
Conv2dIBNormRelu(3 * hr_channels + 3, 2 * hr_channels, 3, stride=1, padding=1),
|
||||||
|
Conv2dIBNormRelu(2 * hr_channels, 2 * hr_channels, 3, stride=1, padding=1),
|
||||||
|
Conv2dIBNormRelu(2 * hr_channels, hr_channels, 3, stride=1, padding=1),
|
||||||
|
)
|
||||||
|
|
||||||
|
self.conv_hr2x = nn.Sequential(
|
||||||
|
Conv2dIBNormRelu(2 * hr_channels, 2 * hr_channels, 3, stride=1, padding=1),
|
||||||
|
Conv2dIBNormRelu(2 * hr_channels, hr_channels, 3, stride=1, padding=1),
|
||||||
|
Conv2dIBNormRelu(hr_channels, hr_channels, 3, stride=1, padding=1),
|
||||||
|
Conv2dIBNormRelu(hr_channels, hr_channels, 3, stride=1, padding=1),
|
||||||
|
)
|
||||||
|
|
||||||
|
self.conv_hr = nn.Sequential(
|
||||||
|
Conv2dIBNormRelu(hr_channels + 3, hr_channels, 3, stride=1, padding=1),
|
||||||
|
Conv2dIBNormRelu(hr_channels, 1, kernel_size=1, stride=1, padding=0, with_ibn=False, with_relu=False),
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, img, enc2x, enc4x, lr8x):
|
||||||
|
h, w = img.size()[2:] # replacing "scale_factor"
|
||||||
|
assert h % 4 == 0 and w % 4 == 0
|
||||||
|
img2x = F.interpolate(img, size=(h//2, w//2), mode='bilinear', align_corners=False)
|
||||||
|
img4x = F.interpolate(img, size=(h//4, w//4), mode='bilinear', align_corners=False)
|
||||||
|
|
||||||
|
enc2x = self.tohr_enc2x(enc2x)
|
||||||
|
hr4x = self.conv_enc2x(torch.cat((img2x, enc2x), dim=1))
|
||||||
|
|
||||||
|
enc4x = self.tohr_enc4x(enc4x)
|
||||||
|
hr4x = self.conv_enc4x(torch.cat((hr4x, enc4x), dim=1))
|
||||||
|
|
||||||
|
h, w = lr8x.size()[2:] # replacing "scale_factor"
|
||||||
|
lr4x = F.interpolate(lr8x, size=(h*2, w*2), mode='bilinear', align_corners=False)
|
||||||
|
hr4x = self.conv_hr4x(torch.cat((hr4x, lr4x, img4x), dim=1))
|
||||||
|
|
||||||
|
h, w = hr4x.size()[2:] # replacing "scale_factor"
|
||||||
|
hr2x = F.interpolate(hr4x, size=(h*2, w*2), mode='bilinear', align_corners=False)
|
||||||
|
hr2x = self.conv_hr2x(torch.cat((hr2x, enc2x), dim=1))
|
||||||
|
|
||||||
|
return hr2x
|
||||||
|
|
||||||
|
|
||||||
|
class FusionBranch(nn.Module):
|
||||||
|
"""Fusion Branch of MODNet"""
|
||||||
|
|
||||||
|
def __init__(self, hr_channels, enc_channels):
|
||||||
|
super(FusionBranch, self).__init__()
|
||||||
|
self.conv_lr4x = Conv2dIBNormRelu(enc_channels[2], hr_channels, 5, stride=1, padding=2)
|
||||||
|
|
||||||
|
self.conv_f2x = Conv2dIBNormRelu(2 * hr_channels, hr_channels, 3, stride=1, padding=1)
|
||||||
|
self.conv_f = nn.Sequential(
|
||||||
|
Conv2dIBNormRelu(hr_channels + 3, int(hr_channels / 2), 3, stride=1, padding=1),
|
||||||
|
Conv2dIBNormRelu(int(hr_channels / 2), 1, 1, stride=1, padding=0, with_ibn=False, with_relu=False),
|
||||||
|
)
|
||||||
|
|
||||||
|
def forward(self, img, lr8x, hr2x):
|
||||||
|
h, w = lr8x.size()[2:] # replacing "scale_factor"
|
||||||
|
lr4x = F.interpolate(lr8x, size=(h*2, w*2), mode='bilinear', align_corners=False)
|
||||||
|
lr4x = self.conv_lr4x(lr4x)
|
||||||
|
h, w = lr4x.size()[2:] # replacing "scale_factor"
|
||||||
|
lr2x = F.interpolate(lr4x, size=(h*2, w*2), mode='bilinear', align_corners=False)
|
||||||
|
|
||||||
|
f2x = self.conv_f2x(torch.cat((lr2x, hr2x), dim=1))
|
||||||
|
h, w = f2x.size()[2:] # replacing "scale_factor"
|
||||||
|
f = F.interpolate(f2x, size=(h*2, w*2), mode='bilinear', align_corners=False)
|
||||||
|
f = self.conv_f(torch.cat((f, img), dim=1))
|
||||||
|
pred_matte = torch.sigmoid(f)
|
||||||
|
|
||||||
|
return pred_matte
|
||||||
|
|
||||||
|
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
# MODNet
|
||||||
|
#------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
class MODNet(nn.Module):
|
||||||
|
"""Architecture of MODNet"""
|
||||||
|
|
||||||
|
def __init__(self, in_channels=3, hr_channels=32, backbone_arch='mobilenetv2', backbone_pretrained=False):
|
||||||
|
super(MODNet, self).__init__()
|
||||||
|
|
||||||
|
self.in_channels = in_channels
|
||||||
|
self.hr_channels = hr_channels
|
||||||
|
self.backbone_arch = backbone_arch
|
||||||
|
|
||||||
|
self.backbone = SUPPORTED_BACKBONES[self.backbone_arch](self.in_channels)
|
||||||
|
self.lr_branch = LRBranch(self.backbone)
|
||||||
|
self.hr_branch = HRBranch(self.hr_channels, self.backbone.enc_channels)
|
||||||
|
self.f_branch = FusionBranch(self.hr_channels, self.backbone.enc_channels)
|
||||||
|
|
||||||
|
for m in self.modules():
|
||||||
|
if isinstance(m, nn.Conv2d):
|
||||||
|
self._init_conv(m)
|
||||||
|
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.InstanceNorm2d):
|
||||||
|
self._init_norm(m)
|
||||||
|
|
||||||
|
if backbone_pretrained:
|
||||||
|
self.backbone.load_pretrained_ckpt()
|
||||||
|
|
||||||
|
def forward(self, img):
|
||||||
|
lr8x, [enc2x, enc4x] = self.lr_branch(img)
|
||||||
|
hr2x = self.hr_branch(img, enc2x, enc4x, lr8x)
|
||||||
|
pred_matte = self.f_branch(img, lr8x, hr2x)
|
||||||
|
return pred_matte
|
||||||
|
|
||||||
|
def _init_conv(self, conv):
|
||||||
|
nn.init.kaiming_uniform_(
|
||||||
|
conv.weight, a=0, mode='fan_in', nonlinearity='relu')
|
||||||
|
if conv.bias is not None:
|
||||||
|
nn.init.constant_(conv.bias, 0)
|
||||||
|
|
||||||
|
def _init_norm(self, norm):
|
||||||
|
if norm.weight is not None:
|
||||||
|
nn.init.constant_(norm.weight, 1)
|
||||||
|
nn.init.constant_(norm.bias, 0)
|
||||||
|
|
@ -0,0 +1,8 @@
|
||||||
|
Cython
|
||||||
|
numpy
|
||||||
|
scikit-build
|
||||||
|
opencv-python
|
||||||
|
PyImage
|
||||||
|
onnx==1.8.1
|
||||||
|
onnxruntime==1.6.0
|
||||||
|
torch==1.7.1
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
OUTNAME_RELEASE = create_engines
|
||||||
|
OUTNAME_DEBUG = create_engines_debug
|
||||||
|
MAKEFILE_CONFIG ?= ../common/Makefile.config
|
||||||
|
include $(MAKEFILE_CONFIG)
|
||||||
|
|
||||||
|
all: release
|
||||||
|
|
@ -0,0 +1,8 @@
|
||||||
|
The MTCNN caffe model files are taken from [https://github.com/PKUZHOU/MTCNN_FaceDetection_TensorRT](https://github.com/PKUZHOU/MTCNN_FaceDetection_TensorRT). These model files contains a workaround which replaces 'PReLU' with 'ReLU', 'Scale' and 'Elementwise Addition' layers. I use them to get around the issue of TensorRT 3.x/4.x not supporting PReLU layers. Please refer to the original GitHub page (linked above) for more details.
|
||||||
|
|
||||||
|
* det1_relu.prototxt
|
||||||
|
* det1_relu.caffemodel
|
||||||
|
* det2_relu.prototxt
|
||||||
|
* det2_relu.caffemodel
|
||||||
|
* det3_relu.prototxt
|
||||||
|
* det3_relu.caffemodel
|
||||||
|
|
@ -0,0 +1,251 @@
|
||||||
|
// create_engines.cpp
|
||||||
|
//
|
||||||
|
// This program creates TensorRT engines for MTCNN models.
|
||||||
|
//
|
||||||
|
// Inputs:
|
||||||
|
// det1.prototxt
|
||||||
|
// det1.caffemodel
|
||||||
|
// det2.prototxt
|
||||||
|
// det2.caffemodel
|
||||||
|
// det3.prototxt
|
||||||
|
// det3.caffemodel
|
||||||
|
//
|
||||||
|
// Outputs:
|
||||||
|
// det1.engine
|
||||||
|
// det2.engine
|
||||||
|
// det3.engine
|
||||||
|
|
||||||
|
#include <assert.h>
|
||||||
|
#include <fstream>
|
||||||
|
#include <sstream>
|
||||||
|
#include <iostream>
|
||||||
|
#include <cmath>
|
||||||
|
#include <algorithm>
|
||||||
|
#include <sys/stat.h>
|
||||||
|
#include <cmath>
|
||||||
|
#include <time.h>
|
||||||
|
#include <cuda_runtime_api.h>
|
||||||
|
|
||||||
|
#include "NvInfer.h"
|
||||||
|
#include "NvCaffeParser.h"
|
||||||
|
#include "common.h"
|
||||||
|
|
||||||
|
using namespace nvinfer1;
|
||||||
|
using namespace nvcaffeparser1;
|
||||||
|
|
||||||
|
//static Logger gLogger(ILogger::Severity::kINFO);
|
||||||
|
static Logger gLogger(ILogger::Severity::kWARNING);
|
||||||
|
|
||||||
|
class IHostMemoryFromFile : public IHostMemory
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
IHostMemoryFromFile(std::string filename);
|
||||||
|
#if NV_TENSORRT_MAJOR >= 6
|
||||||
|
void* data() const noexcept { return mem; }
|
||||||
|
std::size_t size() const noexcept { return s; }
|
||||||
|
DataType type () const noexcept { return DataType::kFLOAT; } // not used
|
||||||
|
void destroy() noexcept { free(mem); }
|
||||||
|
#else // NV_TENSORRT_MAJOR < 6
|
||||||
|
void* data() const { return mem; }
|
||||||
|
std::size_t size() const { return s; }
|
||||||
|
DataType type () const { return DataType::kFLOAT; } // not used
|
||||||
|
void destroy() { free(mem); }
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
private:
|
||||||
|
void *mem{nullptr};
|
||||||
|
std::size_t s;
|
||||||
|
};
|
||||||
|
|
||||||
|
IHostMemoryFromFile::IHostMemoryFromFile(std::string filename)
|
||||||
|
{
|
||||||
|
std::ifstream infile(filename, std::ifstream::binary | std::ifstream::ate);
|
||||||
|
s = infile.tellg();
|
||||||
|
infile.seekg(0, std::ios::beg);
|
||||||
|
mem = malloc(s);
|
||||||
|
infile.read(reinterpret_cast<char*>(mem), s);
|
||||||
|
}
|
||||||
|
|
||||||
|
std::string locateFile(const std::string& input)
|
||||||
|
{
|
||||||
|
std::vector<std::string> dirs{"./"};
|
||||||
|
return locateFile(input, dirs);
|
||||||
|
}
|
||||||
|
|
||||||
|
void caffeToTRTModel(const std::string& deployFile, // name for caffe prototxt
|
||||||
|
const std::string& modelFile, // name for model
|
||||||
|
const std::vector<std::string>& outputs, // network outputs
|
||||||
|
unsigned int maxBatchSize, // batch size - NB must be at least as large as the batch we want to run with)
|
||||||
|
IHostMemory *&trtModelStream)
|
||||||
|
{
|
||||||
|
// create API root class - must span the lifetime of the engine usage
|
||||||
|
IBuilder* builder = createInferBuilder(gLogger);
|
||||||
|
#if NV_TENSORRT_MAJOR >= 7
|
||||||
|
INetworkDefinition* network = builder->createNetworkV2(0); // no kEXPLICIT_BATCH
|
||||||
|
#else // NV_TENSORRT_MAJOR < 7
|
||||||
|
INetworkDefinition* network = builder->createNetwork();
|
||||||
|
#endif
|
||||||
|
|
||||||
|
// parse the caffe model to populate the network, then set the outputs
|
||||||
|
ICaffeParser* parser = createCaffeParser();
|
||||||
|
|
||||||
|
bool useFp16 = builder->platformHasFastFp16();
|
||||||
|
|
||||||
|
// create a 16-bit model if it's natively supported
|
||||||
|
DataType modelDataType = useFp16 ? DataType::kHALF : DataType::kFLOAT;
|
||||||
|
const IBlobNameToTensor *blobNameToTensor =
|
||||||
|
parser->parse(locateFile(deployFile).c_str(), // caffe deploy file
|
||||||
|
locateFile(modelFile).c_str(), // caffe model file
|
||||||
|
*network, // network definition that the parser will populate
|
||||||
|
modelDataType);
|
||||||
|
assert(blobNameToTensor != nullptr);
|
||||||
|
|
||||||
|
// the caffe file has no notion of outputs, so we need to manually say which tensors the engine should generate
|
||||||
|
for (auto& s : outputs)
|
||||||
|
network->markOutput(*blobNameToTensor->find(s.c_str()));
|
||||||
|
|
||||||
|
#if NV_TENSORRT_MAJOR >= 7
|
||||||
|
auto config = builder->createBuilderConfig();
|
||||||
|
assert(config != nullptr);
|
||||||
|
|
||||||
|
builder->setMaxBatchSize(maxBatchSize);
|
||||||
|
config->setMaxWorkspaceSize(64_MB);
|
||||||
|
if (useFp16) {
|
||||||
|
config->setFlag(BuilderFlag::kFP16);
|
||||||
|
cout << "Building TensorRT engine in FP16 mode..." << endl;
|
||||||
|
} else {
|
||||||
|
cout << "Building TensorRT engine in FP32 mode..." << endl;
|
||||||
|
}
|
||||||
|
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
|
||||||
|
config->destroy();
|
||||||
|
#else // NV_TENSORRT_MAJOR < 7
|
||||||
|
// Build the engine
|
||||||
|
builder->setMaxBatchSize(maxBatchSize);
|
||||||
|
builder->setMaxWorkspaceSize(64_MB);
|
||||||
|
|
||||||
|
// set up the network for paired-fp16 format if available
|
||||||
|
if (useFp16) {
|
||||||
|
#if NV_TENSORRT_MAJOR >= 4
|
||||||
|
builder->setFp16Mode(true);
|
||||||
|
#else // NV_TENSORRT_MAJOR < 4
|
||||||
|
builder->setHalf2Mode(true);
|
||||||
|
#endif
|
||||||
|
}
|
||||||
|
ICudaEngine* engine = builder->buildCudaEngine(*network);
|
||||||
|
#endif // NV_TENSORRT_MAJOR >= 7
|
||||||
|
assert(engine != nullptr);
|
||||||
|
|
||||||
|
// we don't need the network any more, and we can destroy the parser
|
||||||
|
parser->destroy();
|
||||||
|
network->destroy();
|
||||||
|
|
||||||
|
// serialize the engine, then close everything down
|
||||||
|
trtModelStream = engine->serialize();
|
||||||
|
engine->destroy();
|
||||||
|
builder->destroy();
|
||||||
|
}
|
||||||
|
|
||||||
|
void giestream_to_file(IHostMemory *trtModelStream, const std::string filename)
|
||||||
|
{
|
||||||
|
assert(trtModelStream != nullptr);
|
||||||
|
std::ofstream outfile(filename, std::ofstream::binary);
|
||||||
|
assert(!outfile.fail());
|
||||||
|
outfile.write(reinterpret_cast<char*>(trtModelStream->data()), trtModelStream->size());
|
||||||
|
outfile.close();
|
||||||
|
}
|
||||||
|
|
||||||
|
void file_to_giestream(const std::string filename, IHostMemoryFromFile *&trtModelStream)
|
||||||
|
{
|
||||||
|
trtModelStream = new IHostMemoryFromFile(filename);
|
||||||
|
}
|
||||||
|
|
||||||
|
void verify_engine(std::string det_name, int num_bindings)
|
||||||
|
{
|
||||||
|
std::stringstream ss;
|
||||||
|
ss << det_name << ".engine";
|
||||||
|
IHostMemoryFromFile *trtModelStream{nullptr};
|
||||||
|
file_to_giestream(ss.str(), trtModelStream);
|
||||||
|
|
||||||
|
// create an engine
|
||||||
|
IRuntime* infer = createInferRuntime(gLogger);
|
||||||
|
assert(infer != nullptr);
|
||||||
|
ICudaEngine* engine = infer->deserializeCudaEngine(
|
||||||
|
trtModelStream->data(),
|
||||||
|
trtModelStream->size(),
|
||||||
|
nullptr);
|
||||||
|
assert(engine != nullptr);
|
||||||
|
|
||||||
|
assert(engine->getNbBindings() == num_bindings);
|
||||||
|
std::cout << "Bindings for " << det_name << " after deserializing:"
|
||||||
|
<< std::endl;
|
||||||
|
for (int bi = 0; bi < num_bindings; bi++) {
|
||||||
|
#if NV_TENSORRT_MAJOR >= 4
|
||||||
|
Dims3 dim = static_cast<Dims3&&>(engine->getBindingDimensions(bi));
|
||||||
|
if (engine->bindingIsInput(bi) == true) {
|
||||||
|
std::cout << " Input ";
|
||||||
|
} else {
|
||||||
|
std::cout << " Output ";
|
||||||
|
}
|
||||||
|
std::cout << bi << ": " << engine->getBindingName(bi) << ", "
|
||||||
|
<< dim.d[0] << "x" << dim.d[1] << "x" << dim.d[2]
|
||||||
|
<< std::endl;
|
||||||
|
#else // NV_TENSORRT_MAJOR < 4
|
||||||
|
DimsCHW dim = static_cast<DimsCHW&&>(engine->getBindingDimensions(bi));
|
||||||
|
if (engine->bindingIsInput(bi) == true) {
|
||||||
|
std::cout << " Input ";
|
||||||
|
} else {
|
||||||
|
std::cout << " Output ";
|
||||||
|
}
|
||||||
|
std::cout << bi << ": " << engine->getBindingName(bi) << ", "
|
||||||
|
<< dim.c() << "x" << dim.h() << "x" << dim.w()
|
||||||
|
<< std::endl;
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
}
|
||||||
|
engine->destroy();
|
||||||
|
infer->destroy();
|
||||||
|
trtModelStream->destroy();
|
||||||
|
}
|
||||||
|
|
||||||
|
int main(int argc, char** argv)
|
||||||
|
{
|
||||||
|
IHostMemory *trtModelStream{nullptr};
|
||||||
|
|
||||||
|
std::cout << "Building det1.engine (PNet), maxBatchSize = 1"
|
||||||
|
<< std::endl;
|
||||||
|
caffeToTRTModel("det1_relu.prototxt",
|
||||||
|
"det1_relu.caffemodel",
|
||||||
|
std::vector <std::string> { "prob1", "conv4-2" },
|
||||||
|
1, // max batch size
|
||||||
|
trtModelStream);
|
||||||
|
giestream_to_file(trtModelStream, "det1.engine");
|
||||||
|
trtModelStream->destroy();
|
||||||
|
|
||||||
|
std::cout << "Building det2.engine (RNet), maxBatchSize = 256"
|
||||||
|
<< std::endl;
|
||||||
|
caffeToTRTModel("det2_relu.prototxt",
|
||||||
|
"det2_relu.caffemodel",
|
||||||
|
std::vector <std::string> { "prob1", "conv5-2" },
|
||||||
|
256, // max batch size
|
||||||
|
trtModelStream);
|
||||||
|
giestream_to_file(trtModelStream, "det2.engine");
|
||||||
|
trtModelStream->destroy();
|
||||||
|
|
||||||
|
std::cout << "Building det3.engine (ONet), maxBatchSize = 64"
|
||||||
|
<< std::endl;
|
||||||
|
caffeToTRTModel("det3_relu.prototxt",
|
||||||
|
"det3_relu.caffemodel",
|
||||||
|
std::vector <std::string> { "prob1", "conv6-2", "conv6-3" },
|
||||||
|
64, // max batch size
|
||||||
|
trtModelStream);
|
||||||
|
giestream_to_file(trtModelStream, "det3.engine");
|
||||||
|
trtModelStream->destroy();
|
||||||
|
//delete trtModelStream;
|
||||||
|
|
||||||
|
shutdownProtobufLibrary();
|
||||||
|
|
||||||
|
std::cout << std::endl << "Verifying engines..." << std::endl;
|
||||||
|
verify_engine("det1", 3);
|
||||||
|
verify_engine("det2", 3);
|
||||||
|
verify_engine("det3", 4);
|
||||||
|
std::cout << "Done." << std::endl;
|
||||||
|
return 0;
|
||||||
|
}
|
||||||
Binary file not shown.
|
|
@ -0,0 +1,290 @@
|
||||||
|
name: "PNet"
|
||||||
|
layer
|
||||||
|
{
|
||||||
|
name: "data"
|
||||||
|
type: "Input"
|
||||||
|
top: "data"
|
||||||
|
#
|
||||||
|
# Max allowed input image size as: 1280x720
|
||||||
|
# 'minsize' = 40
|
||||||
|
#
|
||||||
|
# Input dimension of the 1st 'scale':
|
||||||
|
# 720 * 12 / 40 = 216
|
||||||
|
# 1280 * 12 / 40 = 384
|
||||||
|
#
|
||||||
|
# H's in all scales: (scale factor = 0.709)
|
||||||
|
# Original: 216.0, 153.1, 108.6 77.0, 54.6, 38.7, 27.4, 19.5, 13.8, (9.8)
|
||||||
|
# Rounded: 216, 154, 108, 78, 54, 38, 28, 20, 14
|
||||||
|
# Offsets: 0, 216, 370, 478, 556, 610, 648, 676, 696, (710)
|
||||||
|
#
|
||||||
|
# Input dimension of the 'stacked image': 710x384
|
||||||
|
#
|
||||||
|
# Output dimension: (stride=2)
|
||||||
|
# (710 - 12) / 2 + 1 = 350
|
||||||
|
# (384 - 12) / 2 + 1 = 187
|
||||||
|
#
|
||||||
|
input_param{shape:{dim:1 dim:3 dim:710 dim:384}}
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv1"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "data"
|
||||||
|
top: "conv1"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 10
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU1"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv1"
|
||||||
|
top: "conv1_1"
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "scale1_1"
|
||||||
|
bottom: "conv1"
|
||||||
|
top: "conv1_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU1_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv1_2"
|
||||||
|
top: "conv1_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale1_2"
|
||||||
|
bottom: "conv1_2"
|
||||||
|
top: "conv1_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum1"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv1_1"
|
||||||
|
bottom: "conv1_2"
|
||||||
|
top: "conv1_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "pool1"
|
||||||
|
type: "Pooling"
|
||||||
|
bottom: "conv1_3"
|
||||||
|
top: "pool1"
|
||||||
|
pooling_param {
|
||||||
|
pool: MAX
|
||||||
|
kernel_size: 2
|
||||||
|
stride: 2
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv2"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "pool1"
|
||||||
|
top: "conv2"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 16
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv2"
|
||||||
|
top: "conv2_1"
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "scale2_1"
|
||||||
|
bottom: "conv2"
|
||||||
|
top: "conv2_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU2_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv2_2"
|
||||||
|
top: "conv2_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale2_2"
|
||||||
|
bottom: "conv2_2"
|
||||||
|
top: "conv2_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum2"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv2_1"
|
||||||
|
bottom: "conv2_2"
|
||||||
|
top: "conv2_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv3"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "conv2_3"
|
||||||
|
top: "conv3"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 32
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU3"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv3"
|
||||||
|
top: "conv3_1"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale3_1"
|
||||||
|
bottom: "conv3"
|
||||||
|
top: "conv3_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU3_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv3_2"
|
||||||
|
top: "conv3_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale3_2"
|
||||||
|
bottom: "conv3_2"
|
||||||
|
top: "conv3_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum3"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv3_1"
|
||||||
|
bottom: "conv3_2"
|
||||||
|
top: "conv3_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv4-1"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "conv3_3"
|
||||||
|
top: "conv4-1"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 2
|
||||||
|
kernel_size: 1
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv4-2"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "conv3_3"
|
||||||
|
top: "conv4-2"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 4
|
||||||
|
kernel_size: 1
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "prob1"
|
||||||
|
type: "Softmax"
|
||||||
|
bottom: "conv4-1"
|
||||||
|
top: "prob1"
|
||||||
|
}
|
||||||
Binary file not shown.
|
|
@ -0,0 +1,370 @@
|
||||||
|
name: "RNet"
|
||||||
|
layer
|
||||||
|
{
|
||||||
|
name: "data"
|
||||||
|
type: "Input"
|
||||||
|
top: "data"
|
||||||
|
input_param{shape:{dim:1 dim:3 dim:24 dim:24}}
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv1"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "data"
|
||||||
|
top: "conv1"
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 28
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "relu1_1"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv1"
|
||||||
|
top: "conv1_1"
|
||||||
|
propagate_down: true
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "scale1_1"
|
||||||
|
bottom: "conv1"
|
||||||
|
top: "conv1_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU1_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv1_2"
|
||||||
|
top: "conv1_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale1_2"
|
||||||
|
bottom: "conv1_2"
|
||||||
|
top: "conv1_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum1"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv1_1"
|
||||||
|
bottom: "conv1_2"
|
||||||
|
top: "conv1_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "pool1"
|
||||||
|
type: "Pooling"
|
||||||
|
bottom: "conv1_3"
|
||||||
|
top: "pool1"
|
||||||
|
pooling_param {
|
||||||
|
pool: MAX
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 2
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv2"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "pool1"
|
||||||
|
top: "conv2"
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 48
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "relu2_1"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv2"
|
||||||
|
top: "conv2_1"
|
||||||
|
propagate_down: true
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "scale2_1"
|
||||||
|
bottom: "conv2"
|
||||||
|
top: "conv2_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU2_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv2_2"
|
||||||
|
top: "conv2_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale2_2"
|
||||||
|
bottom: "conv2_2"
|
||||||
|
top: "conv2_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum2"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv2_1"
|
||||||
|
bottom: "conv2_2"
|
||||||
|
top: "conv2_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "pool2"
|
||||||
|
type: "Pooling"
|
||||||
|
bottom: "conv2_3"
|
||||||
|
top: "pool2"
|
||||||
|
pooling_param {
|
||||||
|
pool: MAX
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 2
|
||||||
|
}
|
||||||
|
}
|
||||||
|
####################################
|
||||||
|
|
||||||
|
##################################
|
||||||
|
layer {
|
||||||
|
name: "conv3"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "pool2"
|
||||||
|
top: "conv3"
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 64
|
||||||
|
kernel_size: 2
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "scale3_1"
|
||||||
|
bottom: "conv3"
|
||||||
|
top: "conv3_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU3_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv3_2"
|
||||||
|
top: "conv3_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale3_2"
|
||||||
|
bottom: "conv3_2"
|
||||||
|
top: "conv3_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "relu3"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv3"
|
||||||
|
top: "conv3_1"
|
||||||
|
propagate_down: true
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum3"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv3_1"
|
||||||
|
bottom: "conv3_2"
|
||||||
|
top: "conv3_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
|
||||||
|
###############################
|
||||||
|
|
||||||
|
###############################
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv4"
|
||||||
|
type: "InnerProduct"
|
||||||
|
bottom: "conv3_3"
|
||||||
|
top: "conv4"
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
inner_product_param {
|
||||||
|
num_output: 128
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "relu4_1"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv4"
|
||||||
|
top: "conv4_1"
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "scale4_1"
|
||||||
|
bottom: "conv4"
|
||||||
|
top: "conv4_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU4_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv4_2"
|
||||||
|
top: "conv4_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale4_2"
|
||||||
|
bottom: "conv4_2"
|
||||||
|
top: "conv4_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum4"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv4_1"
|
||||||
|
bottom: "conv4_2"
|
||||||
|
top: "conv4_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv5-1"
|
||||||
|
type: "InnerProduct"
|
||||||
|
bottom: "conv4_3"
|
||||||
|
top: "conv5-1"
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 0
|
||||||
|
decay_mult: 0
|
||||||
|
}
|
||||||
|
inner_product_param {
|
||||||
|
num_output: 2
|
||||||
|
#kernel_size: 1
|
||||||
|
#stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "conv5-2"
|
||||||
|
type: "InnerProduct"
|
||||||
|
bottom: "conv4_3"
|
||||||
|
top: "conv5-2"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
inner_product_param {
|
||||||
|
num_output: 4
|
||||||
|
#kernel_size: 1
|
||||||
|
#stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "prob1"
|
||||||
|
type: "Softmax"
|
||||||
|
bottom: "conv5-1"
|
||||||
|
top: "prob1"
|
||||||
|
}
|
||||||
Binary file not shown.
|
|
@ -0,0 +1,457 @@
|
||||||
|
name: "ONet"
|
||||||
|
input: "data"
|
||||||
|
input_dim: 1
|
||||||
|
input_dim: 3
|
||||||
|
input_dim: 48
|
||||||
|
input_dim: 48
|
||||||
|
##################################
|
||||||
|
layer {
|
||||||
|
name: "conv1"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "data"
|
||||||
|
top: "conv1"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 32
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "relu1_1"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv1"
|
||||||
|
top: "conv1_1"
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "scale1_1"
|
||||||
|
bottom: "conv1"
|
||||||
|
top: "conv1_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU1_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv1_2"
|
||||||
|
top: "conv1_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale1_2"
|
||||||
|
bottom: "conv1_2"
|
||||||
|
top: "conv1_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum1"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv1_1"
|
||||||
|
bottom: "conv1_2"
|
||||||
|
top: "conv1_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "pool1"
|
||||||
|
type: "Pooling"
|
||||||
|
bottom: "conv1_3"
|
||||||
|
top: "pool1"
|
||||||
|
pooling_param {
|
||||||
|
pool: MAX
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 2
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "conv2"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "pool1"
|
||||||
|
top: "conv2"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 64
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 1
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "relu2_1"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv2"
|
||||||
|
top: "conv2_1"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale2_1"
|
||||||
|
bottom: "conv2"
|
||||||
|
top: "conv2_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU2_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv2_2"
|
||||||
|
top: "conv2_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale2_2"
|
||||||
|
bottom: "conv2_2"
|
||||||
|
top: "conv2_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum2"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv2_1"
|
||||||
|
bottom: "conv2_2"
|
||||||
|
top: "conv2_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "pool2"
|
||||||
|
type: "Pooling"
|
||||||
|
bottom: "conv2_3"
|
||||||
|
top: "pool2"
|
||||||
|
pooling_param {
|
||||||
|
pool: MAX
|
||||||
|
kernel_size: 3
|
||||||
|
stride: 2
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv3"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "pool2"
|
||||||
|
top: "conv3"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 64
|
||||||
|
kernel_size: 3
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "relu3_1"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv3"
|
||||||
|
top: "conv3_1"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale3_1"
|
||||||
|
bottom: "conv3"
|
||||||
|
top: "conv3_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU3_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv3_2"
|
||||||
|
top: "conv3_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale3_2"
|
||||||
|
bottom: "conv3_2"
|
||||||
|
top: "conv3_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum3"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv3_1"
|
||||||
|
bottom: "conv3_2"
|
||||||
|
top: "conv3_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "pool3"
|
||||||
|
type: "Pooling"
|
||||||
|
bottom: "conv3_3"
|
||||||
|
top: "pool3"
|
||||||
|
pooling_param {
|
||||||
|
pool: MAX
|
||||||
|
kernel_size: 2
|
||||||
|
stride: 2
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "conv4"
|
||||||
|
type: "Convolution"
|
||||||
|
bottom: "pool3"
|
||||||
|
top: "conv4"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
convolution_param {
|
||||||
|
num_output: 128
|
||||||
|
kernel_size: 2
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "relu4"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv4"
|
||||||
|
top: "conv4_1"
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "scale4_1"
|
||||||
|
bottom: "conv4"
|
||||||
|
top: "conv4_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU4_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv4_2"
|
||||||
|
top: "conv4_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale4_2"
|
||||||
|
bottom: "conv4_2"
|
||||||
|
top: "conv4_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum4"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv4_1"
|
||||||
|
bottom: "conv4_2"
|
||||||
|
top: "conv4_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv5"
|
||||||
|
type: "InnerProduct"
|
||||||
|
bottom: "conv4_3"
|
||||||
|
top: "conv5"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
inner_product_param {
|
||||||
|
#kernel_size: 3
|
||||||
|
num_output: 256
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "relu5_1"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv5"
|
||||||
|
top: "conv5_1"
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "scale5_1"
|
||||||
|
bottom: "conv5"
|
||||||
|
top: "conv5_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "ReLU5_2"
|
||||||
|
type: "ReLU"
|
||||||
|
bottom: "conv5_2"
|
||||||
|
top: "conv5_2"
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "scale5_2"
|
||||||
|
bottom: "conv5_2"
|
||||||
|
top: "conv5_2"
|
||||||
|
type: "Scale"
|
||||||
|
scale_param {
|
||||||
|
axis: 1
|
||||||
|
bias_term:false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "eltwise-sum5"
|
||||||
|
type: "Eltwise"
|
||||||
|
bottom: "conv5_1"
|
||||||
|
bottom: "conv5_2"
|
||||||
|
top: "conv5_3"
|
||||||
|
eltwise_param { operation: SUM }
|
||||||
|
}
|
||||||
|
|
||||||
|
layer {
|
||||||
|
name: "conv6-1"
|
||||||
|
type: "InnerProduct"
|
||||||
|
bottom: "conv5_3"
|
||||||
|
top: "conv6-1"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
inner_product_param {
|
||||||
|
#kernel_size: 1
|
||||||
|
num_output: 2
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "conv6-2"
|
||||||
|
type: "InnerProduct"
|
||||||
|
bottom: "conv5_3"
|
||||||
|
top: "conv6-2"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
inner_product_param {
|
||||||
|
#kernel_size: 1
|
||||||
|
num_output: 4
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "conv6-3"
|
||||||
|
type: "InnerProduct"
|
||||||
|
bottom: "conv5_3"
|
||||||
|
top: "conv6-3"
|
||||||
|
param {
|
||||||
|
lr_mult: 1
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
param {
|
||||||
|
lr_mult: 2
|
||||||
|
decay_mult: 1
|
||||||
|
}
|
||||||
|
inner_product_param {
|
||||||
|
#kernel_size: 1
|
||||||
|
num_output: 10
|
||||||
|
weight_filler {
|
||||||
|
type: "xavier"
|
||||||
|
}
|
||||||
|
bias_filler {
|
||||||
|
type: "constant"
|
||||||
|
value: 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
layer {
|
||||||
|
name: "prob1"
|
||||||
|
type: "Softmax"
|
||||||
|
bottom: "conv6-1"
|
||||||
|
top: "prob1"
|
||||||
|
}
|
||||||
|
|
@ -0,0 +1,37 @@
|
||||||
|
CC=g++
|
||||||
|
LD=ld
|
||||||
|
CXXFLAGS=-Wall -std=c++11 -g -O
|
||||||
|
|
||||||
|
NVCC=nvcc
|
||||||
|
|
||||||
|
# space separated compute values ex: computes=70 75. If not present will fetch device's CC
|
||||||
|
computes=
|
||||||
|
|
||||||
|
ifeq ($(computes), )
|
||||||
|
computes= $(shell python gpu_cc.py)
|
||||||
|
$(info computes: $(computes))
|
||||||
|
endif
|
||||||
|
|
||||||
|
NVCCFLAGS= $(foreach compute, $(computes),-gencode arch=compute_$(compute),code=[sm_$(compute),compute_$(compute)])
|
||||||
|
$(info NVCCFLAGS: $(NVCCFLAGS))
|
||||||
|
|
||||||
|
# These are the directories where I installed TensorRT on my x86_64 PC.
|
||||||
|
TENSORRT_INCS=-I"/usr/local/TensorRT-7.1.3.4/include"
|
||||||
|
TENSORRT_LIBS=-L"/usr/local/TensorRT-7.1.3.4/lib"
|
||||||
|
|
||||||
|
# INCS and LIBS
|
||||||
|
INCS=-I"/usr/local/cuda/include" $(TENSORRT_INCS) -I"/usr/local/include" -I"plugin"
|
||||||
|
LIBS=-L"/usr/local/cuda/lib64" $(TENSORRT_LIBS) -L"/usr/local/lib" -Wl,--start-group -lnvinfer -lnvparsers -lnvinfer_plugin -lcudnn -lcublas -lnvToolsExt -lcudart -lrt -ldl -lpthread -Wl,--end-group
|
||||||
|
|
||||||
|
.PHONY: all clean
|
||||||
|
|
||||||
|
all: libyolo_layer.so
|
||||||
|
|
||||||
|
clean:
|
||||||
|
rm -f *.so *.o
|
||||||
|
|
||||||
|
libyolo_layer.so: yolo_layer.o
|
||||||
|
$(CC) -shared -o $@ $< $(LIBS)
|
||||||
|
|
||||||
|
yolo_layer.o: yolo_layer.cu yolo_layer.h
|
||||||
|
$(NVCC) -ccbin $(CC) $(INCS) $(NVCCFLAGS) -Xcompiler -fPIC -c -o $@ $<
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
The "yolo_layer.h" and "yolo_layer.cu" were taken and modified from [wang-xinyu/tensorrtx/yolov4](https://github.com/wang-xinyu/tensorrtx/tree/master/yolov4). The original code is under [MIT License](https://github.com/wang-xinyu/tensorrtx/blob/master/LICENSE).
|
||||||
|
|
@ -0,0 +1,53 @@
|
||||||
|
#!/usr/bin/env python
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
|
||||||
|
'''
|
||||||
|
# ported from https://gist.github.com/f0k/63a664160d016a491b2cbea15913d549
|
||||||
|
'''
|
||||||
|
|
||||||
|
import ctypes
|
||||||
|
|
||||||
|
CUDA_SUCCESS = 0
|
||||||
|
|
||||||
|
def get_gpu_archs():
|
||||||
|
libnames = ('libcuda.so', 'libcuda.dylib', 'cuda.dll')
|
||||||
|
for libname in libnames:
|
||||||
|
try:
|
||||||
|
cuda = ctypes.CDLL(libname)
|
||||||
|
except OSError:
|
||||||
|
continue
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
else:
|
||||||
|
return
|
||||||
|
|
||||||
|
gpu_archs = set()
|
||||||
|
|
||||||
|
n_gpus = ctypes.c_int()
|
||||||
|
cc_major = ctypes.c_int()
|
||||||
|
cc_minor = ctypes.c_int()
|
||||||
|
|
||||||
|
result = ctypes.c_int()
|
||||||
|
device = ctypes.c_int()
|
||||||
|
error_str = ctypes.c_char_p()
|
||||||
|
|
||||||
|
result = cuda.cuInit(0)
|
||||||
|
if result != CUDA_SUCCESS:
|
||||||
|
cuda.cuGetErrorString(result, ctypes.byref(error_str))
|
||||||
|
# print('cuInit failed with error code %d: %s' % (result, error_str.value.decode()))
|
||||||
|
return []
|
||||||
|
|
||||||
|
result = cuda.cuDeviceGetCount(ctypes.byref(n_gpus))
|
||||||
|
if result != CUDA_SUCCESS:
|
||||||
|
cuda.cuGetErrorString(result, ctypes.byref(error_str))
|
||||||
|
# print('cuDeviceGetCount failed with error code %d: %s' % (result, error_str.value.decode()))
|
||||||
|
return []
|
||||||
|
|
||||||
|
for i in range(n_gpus.value):
|
||||||
|
if cuda.cuDeviceComputeCapability(ctypes.byref(cc_major), ctypes.byref(cc_minor), device) == CUDA_SUCCESS:
|
||||||
|
gpu_archs.add(str(cc_major.value) + str(cc_minor.value))
|
||||||
|
|
||||||
|
return list(gpu_archs)
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
print(' '.join(get_gpu_archs()))
|
||||||
|
|
@ -0,0 +1,372 @@
|
||||||
|
/*
|
||||||
|
* yolo_layer.cu
|
||||||
|
*
|
||||||
|
* This code was originally written by wang-xinyu under MIT license.
|
||||||
|
* I took it from:
|
||||||
|
*
|
||||||
|
* https://github.com/wang-xinyu/tensorrtx/tree/master/yolov4
|
||||||
|
*
|
||||||
|
* and made necessary modifications.
|
||||||
|
*
|
||||||
|
* - JK Jung
|
||||||
|
*/
|
||||||
|
|
||||||
|
#include "yolo_layer.h"
|
||||||
|
|
||||||
|
using namespace Yolo;
|
||||||
|
|
||||||
|
namespace
|
||||||
|
{
|
||||||
|
// Write values into buffer
|
||||||
|
template <typename T>
|
||||||
|
void write(char*& buffer, const T& val)
|
||||||
|
{
|
||||||
|
*reinterpret_cast<T*>(buffer) = val;
|
||||||
|
buffer += sizeof(T);
|
||||||
|
}
|
||||||
|
|
||||||
|
// Read values from buffer
|
||||||
|
template <typename T>
|
||||||
|
void read(const char*& buffer, T& val)
|
||||||
|
{
|
||||||
|
val = *reinterpret_cast<const T*>(buffer);
|
||||||
|
buffer += sizeof(T);
|
||||||
|
}
|
||||||
|
} // namespace
|
||||||
|
|
||||||
|
namespace nvinfer1
|
||||||
|
{
|
||||||
|
YoloLayerPlugin::YoloLayerPlugin(int yolo_width, int yolo_height, int num_anchors, float* anchors, int num_classes, int input_width, int input_height, float scale_x_y, int new_coords)
|
||||||
|
{
|
||||||
|
mYoloWidth = yolo_width;
|
||||||
|
mYoloHeight = yolo_height;
|
||||||
|
mNumAnchors = num_anchors;
|
||||||
|
memcpy(mAnchorsHost, anchors, num_anchors * 2 * sizeof(float));
|
||||||
|
mNumClasses = num_classes;
|
||||||
|
mInputWidth = input_width;
|
||||||
|
mInputHeight = input_height;
|
||||||
|
mScaleXY = scale_x_y;
|
||||||
|
mNewCoords = new_coords;
|
||||||
|
|
||||||
|
CHECK(cudaMalloc(&mAnchors, MAX_ANCHORS * 2 * sizeof(float)));
|
||||||
|
CHECK(cudaMemcpy(mAnchors, mAnchorsHost, mNumAnchors * 2 * sizeof(float), cudaMemcpyHostToDevice));
|
||||||
|
}
|
||||||
|
|
||||||
|
YoloLayerPlugin::YoloLayerPlugin(const void* data, size_t length)
|
||||||
|
{
|
||||||
|
const char *d = reinterpret_cast<const char *>(data), *a = d;
|
||||||
|
read(d, mThreadCount);
|
||||||
|
read(d, mYoloWidth);
|
||||||
|
read(d, mYoloHeight);
|
||||||
|
read(d, mNumAnchors);
|
||||||
|
memcpy(mAnchorsHost, d, MAX_ANCHORS * 2 * sizeof(float));
|
||||||
|
d += MAX_ANCHORS * 2 * sizeof(float);
|
||||||
|
read(d, mNumClasses);
|
||||||
|
read(d, mInputWidth);
|
||||||
|
read(d, mInputHeight);
|
||||||
|
read(d, mScaleXY);
|
||||||
|
read(d, mNewCoords);
|
||||||
|
|
||||||
|
CHECK(cudaMalloc(&mAnchors, MAX_ANCHORS * 2 * sizeof(float)));
|
||||||
|
CHECK(cudaMemcpy(mAnchors, mAnchorsHost, mNumAnchors * 2 * sizeof(float), cudaMemcpyHostToDevice));
|
||||||
|
|
||||||
|
assert(d == a + length);
|
||||||
|
}
|
||||||
|
|
||||||
|
IPluginV2IOExt* YoloLayerPlugin::clone() const NOEXCEPT
|
||||||
|
{
|
||||||
|
YoloLayerPlugin *p = new YoloLayerPlugin(mYoloWidth, mYoloHeight, mNumAnchors, (float*) mAnchorsHost, mNumClasses, mInputWidth, mInputHeight, mScaleXY, mNewCoords);
|
||||||
|
p->setPluginNamespace(mPluginNamespace);
|
||||||
|
return p;
|
||||||
|
}
|
||||||
|
|
||||||
|
void YoloLayerPlugin::terminate() NOEXCEPT
|
||||||
|
{
|
||||||
|
CHECK(cudaFree(mAnchors));
|
||||||
|
}
|
||||||
|
|
||||||
|
size_t YoloLayerPlugin::getSerializationSize() const NOEXCEPT
|
||||||
|
{
|
||||||
|
return sizeof(mThreadCount) + \
|
||||||
|
sizeof(mYoloWidth) + sizeof(mYoloHeight) + \
|
||||||
|
sizeof(mNumAnchors) + MAX_ANCHORS * 2 * sizeof(float) + \
|
||||||
|
sizeof(mNumClasses) + \
|
||||||
|
sizeof(mInputWidth) + sizeof(mInputHeight) + \
|
||||||
|
sizeof(mScaleXY) + sizeof(mNewCoords);
|
||||||
|
}
|
||||||
|
|
||||||
|
void YoloLayerPlugin::serialize(void* buffer) const NOEXCEPT
|
||||||
|
{
|
||||||
|
char* d = static_cast<char*>(buffer), *a = d;
|
||||||
|
write(d, mThreadCount);
|
||||||
|
write(d, mYoloWidth);
|
||||||
|
write(d, mYoloHeight);
|
||||||
|
write(d, mNumAnchors);
|
||||||
|
memcpy(d, mAnchorsHost, MAX_ANCHORS * 2 * sizeof(float));
|
||||||
|
d += MAX_ANCHORS * 2 * sizeof(float);
|
||||||
|
write(d, mNumClasses);
|
||||||
|
write(d, mInputWidth);
|
||||||
|
write(d, mInputHeight);
|
||||||
|
write(d, mScaleXY);
|
||||||
|
write(d, mNewCoords);
|
||||||
|
|
||||||
|
assert(d == a + getSerializationSize());
|
||||||
|
}
|
||||||
|
|
||||||
|
Dims YoloLayerPlugin::getOutputDimensions(int index, const Dims* inputs, int nbInputDims) NOEXCEPT
|
||||||
|
{
|
||||||
|
assert(index == 0);
|
||||||
|
assert(nbInputDims == 1);
|
||||||
|
assert(inputs[0].d[0] == (mNumClasses + 5) * mNumAnchors);
|
||||||
|
assert(inputs[0].d[1] == mYoloHeight);
|
||||||
|
assert(inputs[0].d[2] == mYoloWidth);
|
||||||
|
// output detection results to the channel dimension
|
||||||
|
int totalsize = mYoloWidth * mYoloHeight * mNumAnchors * sizeof(Detection) / sizeof(float);
|
||||||
|
return Dims3(totalsize, 1, 1);
|
||||||
|
}
|
||||||
|
|
||||||
|
inline __device__ float sigmoidGPU(float x) { return 1.0f / (1.0f + __expf(-x)); }
|
||||||
|
|
||||||
|
inline __device__ float scale_sigmoidGPU(float x, float s)
|
||||||
|
{
|
||||||
|
return s * sigmoidGPU(x) - (s - 1.0f) * 0.5f;
|
||||||
|
}
|
||||||
|
|
||||||
|
// CalDetection(): This kernel processes 1 yolo layer calculation. It
|
||||||
|
// distributes calculations so that 1 GPU thread would be responsible
|
||||||
|
// for each grid/anchor combination.
|
||||||
|
// NOTE: The output (x, y, w, h) are between 0.0 and 1.0
|
||||||
|
// (relative to orginal image width and height).
|
||||||
|
__global__ void CalDetection(const float *input, float *output,
|
||||||
|
int batch_size,
|
||||||
|
int yolo_width, int yolo_height,
|
||||||
|
int num_anchors, const float *anchors,
|
||||||
|
int num_classes, int input_w, int input_h,
|
||||||
|
float scale_x_y)
|
||||||
|
{
|
||||||
|
int idx = threadIdx.x + blockDim.x * blockIdx.x;
|
||||||
|
Detection* det = ((Detection*) output) + idx;
|
||||||
|
int total_grids = yolo_width * yolo_height;
|
||||||
|
if (idx >= batch_size * total_grids * num_anchors) return;
|
||||||
|
|
||||||
|
int info_len = 5 + num_classes;
|
||||||
|
//int batch_idx = idx / (total_grids * num_anchors);
|
||||||
|
int group_idx = idx / total_grids;
|
||||||
|
int anchor_idx = group_idx % num_anchors;
|
||||||
|
const float* cur_input = input + group_idx * (info_len * total_grids) + (idx % total_grids);
|
||||||
|
|
||||||
|
int class_id;
|
||||||
|
float max_cls_logit = -CUDART_INF_F; // minus infinity
|
||||||
|
for (int i = 5; i < info_len; ++i) {
|
||||||
|
float l = *(cur_input + i * total_grids);
|
||||||
|
if (l > max_cls_logit) {
|
||||||
|
max_cls_logit = l;
|
||||||
|
class_id = i - 5;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
float max_cls_prob = sigmoidGPU(max_cls_logit);
|
||||||
|
float box_prob = sigmoidGPU(*(cur_input + 4 * total_grids));
|
||||||
|
//if (max_cls_prob < IGNORE_THRESH || box_prob < IGNORE_THRESH)
|
||||||
|
// return;
|
||||||
|
|
||||||
|
int row = (idx % total_grids) / yolo_width;
|
||||||
|
int col = (idx % total_grids) % yolo_width;
|
||||||
|
|
||||||
|
det->bbox[0] = (col + scale_sigmoidGPU(*(cur_input + 0 * total_grids), scale_x_y)) / yolo_width; // [0, 1]
|
||||||
|
det->bbox[1] = (row + scale_sigmoidGPU(*(cur_input + 1 * total_grids), scale_x_y)) / yolo_height; // [0, 1]
|
||||||
|
det->bbox[2] = __expf(*(cur_input + 2 * total_grids)) * *(anchors + 2 * anchor_idx + 0) / input_w; // [0, 1]
|
||||||
|
det->bbox[3] = __expf(*(cur_input + 3 * total_grids)) * *(anchors + 2 * anchor_idx + 1) / input_h; // [0, 1]
|
||||||
|
|
||||||
|
det->bbox[0] -= det->bbox[2] / 2; // shift from center to top-left
|
||||||
|
det->bbox[1] -= det->bbox[3] / 2;
|
||||||
|
|
||||||
|
det->det_confidence = box_prob;
|
||||||
|
det->class_id = class_id;
|
||||||
|
det->class_confidence = max_cls_prob;
|
||||||
|
}
|
||||||
|
|
||||||
|
inline __device__ float scale(float x, float s)
|
||||||
|
{
|
||||||
|
return s * x - (s - 1.0f) * 0.5f;
|
||||||
|
}
|
||||||
|
|
||||||
|
inline __device__ float square(float x)
|
||||||
|
{
|
||||||
|
return x * x;
|
||||||
|
}
|
||||||
|
|
||||||
|
__global__ void CalDetection_NewCoords(const float *input, float *output,
|
||||||
|
int batch_size,
|
||||||
|
int yolo_width, int yolo_height,
|
||||||
|
int num_anchors, const float *anchors,
|
||||||
|
int num_classes, int input_w, int input_h,
|
||||||
|
float scale_x_y)
|
||||||
|
{
|
||||||
|
int idx = threadIdx.x + blockDim.x * blockIdx.x;
|
||||||
|
Detection* det = ((Detection*) output) + idx;
|
||||||
|
int total_grids = yolo_width * yolo_height;
|
||||||
|
if (idx >= batch_size * total_grids * num_anchors) return;
|
||||||
|
|
||||||
|
int info_len = 5 + num_classes;
|
||||||
|
//int batch_idx = idx / (total_grids * num_anchors);
|
||||||
|
int group_idx = idx / total_grids;
|
||||||
|
int anchor_idx = group_idx % num_anchors;
|
||||||
|
const float* cur_input = input + group_idx * (info_len * total_grids) + (idx % total_grids);
|
||||||
|
|
||||||
|
int class_id;
|
||||||
|
float max_cls_prob = -CUDART_INF_F; // minus infinity
|
||||||
|
for (int i = 5; i < info_len; ++i) {
|
||||||
|
float l = *(cur_input + i * total_grids);
|
||||||
|
if (l > max_cls_prob) {
|
||||||
|
max_cls_prob = l;
|
||||||
|
class_id = i - 5;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
float box_prob = *(cur_input + 4 * total_grids);
|
||||||
|
//if (max_cls_prob < IGNORE_THRESH || box_prob < IGNORE_THRESH)
|
||||||
|
// return;
|
||||||
|
|
||||||
|
int row = (idx % total_grids) / yolo_width;
|
||||||
|
int col = (idx % total_grids) % yolo_width;
|
||||||
|
|
||||||
|
det->bbox[0] = (col + scale(*(cur_input + 0 * total_grids), scale_x_y)) / yolo_width; // [0, 1]
|
||||||
|
det->bbox[1] = (row + scale(*(cur_input + 1 * total_grids), scale_x_y)) / yolo_height; // [0, 1]
|
||||||
|
det->bbox[2] = square(*(cur_input + 2 * total_grids)) * 4 * *(anchors + 2 * anchor_idx + 0) / input_w; // [0, 1]
|
||||||
|
det->bbox[3] = square(*(cur_input + 3 * total_grids)) * 4 * *(anchors + 2 * anchor_idx + 1) / input_h; // [0, 1]
|
||||||
|
|
||||||
|
det->bbox[0] -= det->bbox[2] / 2; // shift from center to top-left
|
||||||
|
det->bbox[1] -= det->bbox[3] / 2;
|
||||||
|
|
||||||
|
det->det_confidence = box_prob;
|
||||||
|
det->class_id = class_id;
|
||||||
|
det->class_confidence = max_cls_prob;
|
||||||
|
}
|
||||||
|
|
||||||
|
void YoloLayerPlugin::forwardGpu(const float* const* inputs, float* output, cudaStream_t stream, int batchSize)
|
||||||
|
{
|
||||||
|
int num_elements = batchSize * mNumAnchors * mYoloWidth * mYoloHeight;
|
||||||
|
|
||||||
|
//CHECK(cudaMemset(output, 0, num_elements * sizeof(Detection)));
|
||||||
|
|
||||||
|
if (mNewCoords) {
|
||||||
|
CalDetection_NewCoords<<<(num_elements + mThreadCount - 1) / mThreadCount, mThreadCount, 0, stream>>>
|
||||||
|
(inputs[0], output, batchSize, mYoloWidth, mYoloHeight, mNumAnchors, (const float*) mAnchors, mNumClasses, mInputWidth, mInputHeight, mScaleXY);
|
||||||
|
} else {
|
||||||
|
CalDetection<<<(num_elements + mThreadCount - 1) / mThreadCount, mThreadCount, 0, stream>>>
|
||||||
|
(inputs[0], output, batchSize, mYoloWidth, mYoloHeight, mNumAnchors, (const float*) mAnchors, mNumClasses, mInputWidth, mInputHeight, mScaleXY);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
#if NV_TENSORRT_MAJOR >= 8
|
||||||
|
int32_t YoloLayerPlugin::enqueue(int32_t batchSize, void const* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream) NOEXCEPT
|
||||||
|
#else // NV_TENSORRT_MAJOR < 8
|
||||||
|
int YoloLayerPlugin::enqueue(int batchSize, const void*const * inputs, void** outputs, void* workspace, cudaStream_t stream)
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
{
|
||||||
|
forwardGpu((const float* const*)inputs, (float*)outputs[0], stream, batchSize);
|
||||||
|
return 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
YoloPluginCreator::YoloPluginCreator()
|
||||||
|
{
|
||||||
|
mPluginAttributes.clear();
|
||||||
|
|
||||||
|
mFC.nbFields = mPluginAttributes.size();
|
||||||
|
mFC.fields = mPluginAttributes.data();
|
||||||
|
}
|
||||||
|
|
||||||
|
const char* YoloPluginCreator::getPluginName() const NOEXCEPT
|
||||||
|
{
|
||||||
|
return "YoloLayer_TRT";
|
||||||
|
}
|
||||||
|
|
||||||
|
const char* YoloPluginCreator::getPluginVersion() const NOEXCEPT
|
||||||
|
{
|
||||||
|
return "1";
|
||||||
|
}
|
||||||
|
|
||||||
|
const PluginFieldCollection* YoloPluginCreator::getFieldNames() NOEXCEPT
|
||||||
|
{
|
||||||
|
return &mFC;
|
||||||
|
}
|
||||||
|
|
||||||
|
IPluginV2IOExt* YoloPluginCreator::createPlugin(const char* name, const PluginFieldCollection* fc) NOEXCEPT
|
||||||
|
{
|
||||||
|
assert(!strcmp(name, getPluginName()));
|
||||||
|
const PluginField* fields = fc->fields;
|
||||||
|
int yolo_width, yolo_height, num_anchors = 0;
|
||||||
|
float anchors[MAX_ANCHORS * 2];
|
||||||
|
int num_classes, input_multiplier, new_coords = 0;
|
||||||
|
float scale_x_y = 1.0;
|
||||||
|
|
||||||
|
for (int i = 0; i < fc->nbFields; ++i)
|
||||||
|
{
|
||||||
|
const char* attrName = fields[i].name;
|
||||||
|
if (!strcmp(attrName, "yoloWidth"))
|
||||||
|
{
|
||||||
|
assert(fields[i].type == PluginFieldType::kINT32);
|
||||||
|
yolo_width = *(static_cast<const int*>(fields[i].data));
|
||||||
|
}
|
||||||
|
else if (!strcmp(attrName, "yoloHeight"))
|
||||||
|
{
|
||||||
|
assert(fields[i].type == PluginFieldType::kINT32);
|
||||||
|
yolo_height = *(static_cast<const int*>(fields[i].data));
|
||||||
|
}
|
||||||
|
else if (!strcmp(attrName, "numAnchors"))
|
||||||
|
{
|
||||||
|
assert(fields[i].type == PluginFieldType::kINT32);
|
||||||
|
num_anchors = *(static_cast<const int*>(fields[i].data));
|
||||||
|
}
|
||||||
|
else if (!strcmp(attrName, "numClasses"))
|
||||||
|
{
|
||||||
|
assert(fields[i].type == PluginFieldType::kINT32);
|
||||||
|
num_classes = *(static_cast<const int*>(fields[i].data));
|
||||||
|
}
|
||||||
|
else if (!strcmp(attrName, "inputMultiplier"))
|
||||||
|
{
|
||||||
|
assert(fields[i].type == PluginFieldType::kINT32);
|
||||||
|
input_multiplier = *(static_cast<const int*>(fields[i].data));
|
||||||
|
}
|
||||||
|
else if (!strcmp(attrName, "anchors")){
|
||||||
|
assert(num_anchors > 0 && num_anchors <= MAX_ANCHORS);
|
||||||
|
assert(fields[i].type == PluginFieldType::kFLOAT32);
|
||||||
|
memcpy(anchors, static_cast<const float*>(fields[i].data), num_anchors * 2 * sizeof(float));
|
||||||
|
}
|
||||||
|
else if (!strcmp(attrName, "scaleXY"))
|
||||||
|
{
|
||||||
|
assert(fields[i].type == PluginFieldType::kFLOAT32);
|
||||||
|
scale_x_y = *(static_cast<const float*>(fields[i].data));
|
||||||
|
}
|
||||||
|
else if (!strcmp(attrName, "newCoords"))
|
||||||
|
{
|
||||||
|
assert(fields[i].type == PluginFieldType::kINT32);
|
||||||
|
new_coords = *(static_cast<const int*>(fields[i].data));
|
||||||
|
}
|
||||||
|
else
|
||||||
|
{
|
||||||
|
std::cerr << "Unknown attribute: " << attrName << std::endl;
|
||||||
|
assert(0);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
assert(yolo_width > 0 && yolo_height > 0);
|
||||||
|
assert(anchors[0] > 0.0f && anchors[1] > 0.0f);
|
||||||
|
assert(num_classes > 0);
|
||||||
|
assert(input_multiplier == 64 || input_multiplier == 32 || \
|
||||||
|
input_multiplier == 16 || input_multiplier == 8);
|
||||||
|
assert(scale_x_y >= 1.0);
|
||||||
|
|
||||||
|
YoloLayerPlugin* obj = new YoloLayerPlugin(yolo_width, yolo_height, num_anchors, anchors, num_classes, yolo_width * input_multiplier, yolo_height * input_multiplier, scale_x_y, new_coords);
|
||||||
|
obj->setPluginNamespace(mNamespace.c_str());
|
||||||
|
return obj;
|
||||||
|
}
|
||||||
|
|
||||||
|
IPluginV2IOExt* YoloPluginCreator::deserializePlugin(const char* name, const void* serialData, size_t serialLength) NOEXCEPT
|
||||||
|
{
|
||||||
|
YoloLayerPlugin* obj = new YoloLayerPlugin(serialData, serialLength);
|
||||||
|
obj->setPluginNamespace(mNamespace.c_str());
|
||||||
|
return obj;
|
||||||
|
}
|
||||||
|
|
||||||
|
PluginFieldCollection YoloPluginCreator::mFC{};
|
||||||
|
std::vector<PluginField> YoloPluginCreator::mPluginAttributes;
|
||||||
|
} // namespace nvinfer1
|
||||||
|
|
@ -0,0 +1,150 @@
|
||||||
|
#ifndef _YOLO_LAYER_H
|
||||||
|
#define _YOLO_LAYER_H
|
||||||
|
|
||||||
|
#include <cassert>
|
||||||
|
#include <vector>
|
||||||
|
#include <string>
|
||||||
|
#include <iostream>
|
||||||
|
#include "math_constants.h"
|
||||||
|
#include "NvInfer.h"
|
||||||
|
|
||||||
|
#define MAX_ANCHORS 6
|
||||||
|
|
||||||
|
#if NV_TENSORRT_MAJOR >= 8
|
||||||
|
#define NOEXCEPT noexcept
|
||||||
|
#else
|
||||||
|
#define NOEXCEPT
|
||||||
|
#endif
|
||||||
|
|
||||||
|
#define CHECK(status) \
|
||||||
|
do { \
|
||||||
|
auto ret = status; \
|
||||||
|
if (ret != 0) { \
|
||||||
|
std::cerr << "Cuda failure in file '" << __FILE__ \
|
||||||
|
<< "' line " << __LINE__ \
|
||||||
|
<< ": " << ret << std::endl; \
|
||||||
|
abort(); \
|
||||||
|
} \
|
||||||
|
} while (0)
|
||||||
|
|
||||||
|
namespace Yolo
|
||||||
|
{
|
||||||
|
static constexpr float IGNORE_THRESH = 0.01f;
|
||||||
|
|
||||||
|
struct alignas(float) Detection {
|
||||||
|
float bbox[4]; // x, y, w, h
|
||||||
|
float det_confidence;
|
||||||
|
float class_id;
|
||||||
|
float class_confidence;
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
|
namespace nvinfer1
|
||||||
|
{
|
||||||
|
class YoloLayerPlugin: public IPluginV2IOExt
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
YoloLayerPlugin(int yolo_width, int yolo_height, int num_anchors, float* anchors, int num_classes, int input_width, int input_height, float scale_x_y, int new_coords);
|
||||||
|
YoloLayerPlugin(const void* data, size_t length);
|
||||||
|
|
||||||
|
~YoloLayerPlugin() override = default;
|
||||||
|
|
||||||
|
IPluginV2IOExt* clone() const NOEXCEPT override;
|
||||||
|
|
||||||
|
int initialize() NOEXCEPT override { return 0; }
|
||||||
|
|
||||||
|
void terminate() NOEXCEPT override;
|
||||||
|
|
||||||
|
void destroy() NOEXCEPT override { delete this; }
|
||||||
|
|
||||||
|
size_t getSerializationSize() const NOEXCEPT override;
|
||||||
|
|
||||||
|
void serialize(void* buffer) const NOEXCEPT override;
|
||||||
|
|
||||||
|
int getNbOutputs() const NOEXCEPT override { return 1; }
|
||||||
|
|
||||||
|
Dims getOutputDimensions(int index, const Dims* inputs, int nbInputDims) NOEXCEPT override;
|
||||||
|
|
||||||
|
size_t getWorkspaceSize(int maxBatchSize) const NOEXCEPT override { return 0; }
|
||||||
|
|
||||||
|
bool supportsFormatCombination(int pos, const PluginTensorDesc* inOut, int nbInputs, int nbOutputs) const NOEXCEPT override { return inOut[pos].format == TensorFormat::kLINEAR && inOut[pos].type == DataType::kFLOAT; }
|
||||||
|
|
||||||
|
const char* getPluginType() const NOEXCEPT override { return "YoloLayer_TRT"; }
|
||||||
|
|
||||||
|
const char* getPluginVersion() const NOEXCEPT override { return "1"; }
|
||||||
|
|
||||||
|
void setPluginNamespace(const char* pluginNamespace) NOEXCEPT override { mPluginNamespace = pluginNamespace; }
|
||||||
|
|
||||||
|
const char* getPluginNamespace() const NOEXCEPT override { return mPluginNamespace; }
|
||||||
|
|
||||||
|
DataType getOutputDataType(int index, const DataType* inputTypes, int nbInputs) const NOEXCEPT override { return DataType::kFLOAT; }
|
||||||
|
|
||||||
|
bool isOutputBroadcastAcrossBatch(int outputIndex, const bool* inputIsBroadcasted, int nbInputs) const NOEXCEPT override { return false; }
|
||||||
|
|
||||||
|
bool canBroadcastInputAcrossBatch(int inputIndex) const NOEXCEPT override { return false; }
|
||||||
|
|
||||||
|
void attachToContext(cudnnContext* cudnnContext, cublasContext* cublasContext, IGpuAllocator* gpuAllocator) NOEXCEPT override {}
|
||||||
|
|
||||||
|
//using IPluginV2IOExt::configurePlugin;
|
||||||
|
void configurePlugin(const PluginTensorDesc* in, int nbInput, const PluginTensorDesc* out, int nbOutput) NOEXCEPT override {}
|
||||||
|
|
||||||
|
void detachFromContext() NOEXCEPT override {}
|
||||||
|
|
||||||
|
#if NV_TENSORRT_MAJOR >= 8
|
||||||
|
int32_t enqueue(int32_t batchSize, void const* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream) NOEXCEPT override;
|
||||||
|
#else
|
||||||
|
int enqueue(int batchSize, const void* const * inputs, void** outputs, void* workspace, cudaStream_t stream) NOEXCEPT override;
|
||||||
|
#endif
|
||||||
|
|
||||||
|
private:
|
||||||
|
void forwardGpu(const float* const* inputs, float* output, cudaStream_t stream, int batchSize = 1);
|
||||||
|
|
||||||
|
int mThreadCount = 64;
|
||||||
|
int mYoloWidth, mYoloHeight, mNumAnchors;
|
||||||
|
float mAnchorsHost[MAX_ANCHORS * 2];
|
||||||
|
float *mAnchors; // allocated on GPU
|
||||||
|
int mNumClasses;
|
||||||
|
int mInputWidth, mInputHeight;
|
||||||
|
float mScaleXY;
|
||||||
|
int mNewCoords = 0;
|
||||||
|
|
||||||
|
const char* mPluginNamespace;
|
||||||
|
};
|
||||||
|
|
||||||
|
class YoloPluginCreator : public IPluginCreator
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
YoloPluginCreator();
|
||||||
|
|
||||||
|
~YoloPluginCreator() override = default;
|
||||||
|
|
||||||
|
const char* getPluginName() const NOEXCEPT override;
|
||||||
|
|
||||||
|
const char* getPluginVersion() const NOEXCEPT override;
|
||||||
|
|
||||||
|
const PluginFieldCollection* getFieldNames() NOEXCEPT override;
|
||||||
|
|
||||||
|
IPluginV2IOExt* createPlugin(const char* name, const PluginFieldCollection* fc) NOEXCEPT override;
|
||||||
|
|
||||||
|
IPluginV2IOExt* deserializePlugin(const char* name, const void* serialData, size_t serialLength) NOEXCEPT override;
|
||||||
|
|
||||||
|
void setPluginNamespace(const char* libNamespace) NOEXCEPT override
|
||||||
|
{
|
||||||
|
mNamespace = libNamespace;
|
||||||
|
}
|
||||||
|
|
||||||
|
const char* getPluginNamespace() const NOEXCEPT override
|
||||||
|
{
|
||||||
|
return mNamespace.c_str();
|
||||||
|
}
|
||||||
|
|
||||||
|
private:
|
||||||
|
static PluginFieldCollection mFC;
|
||||||
|
static std::vector<PluginField> mPluginAttributes;
|
||||||
|
std::string mNamespace;
|
||||||
|
};
|
||||||
|
|
||||||
|
REGISTER_TENSORRT_PLUGIN(YoloPluginCreator);
|
||||||
|
};
|
||||||
|
|
||||||
|
#endif
|
||||||
|
|
@ -0,0 +1,22 @@
|
||||||
|
from libcpp.string cimport string
|
||||||
|
|
||||||
|
cdef extern from 'trtNet.cpp' namespace 'trtnet':
|
||||||
|
pass
|
||||||
|
|
||||||
|
cdef extern from 'trtNet.h' namespace 'trtnet':
|
||||||
|
cdef cppclass TrtGooglenet:
|
||||||
|
TrtGooglenet() except +
|
||||||
|
void initEngine(string, int *, int *)
|
||||||
|
void forward(float *, float *)
|
||||||
|
void destroy()
|
||||||
|
|
||||||
|
cdef cppclass TrtMtcnnDet:
|
||||||
|
TrtMtcnnDet() except +
|
||||||
|
void initDet1(string, int *, int *, int *)
|
||||||
|
void initDet2(string, int *, int *, int *)
|
||||||
|
void initDet3(string, int *, int *, int *, int *)
|
||||||
|
void setBatchSize(int)
|
||||||
|
int getBatchSize()
|
||||||
|
void forward(float *, float *, float *)
|
||||||
|
void forward(float *, float *, float *, float *)
|
||||||
|
void destroy()
|
||||||
|
|
@ -0,0 +1,134 @@
|
||||||
|
import cython
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
cimport numpy as np
|
||||||
|
from libcpp.string cimport string
|
||||||
|
|
||||||
|
from pytrt cimport TrtGooglenet
|
||||||
|
from pytrt cimport TrtMtcnnDet
|
||||||
|
|
||||||
|
cdef class PyTrtGooglenet:
|
||||||
|
cdef TrtGooglenet *c_trtnet
|
||||||
|
cdef tuple data_dims, prob_dims
|
||||||
|
|
||||||
|
def __cinit__(PyTrtGooglenet self):
|
||||||
|
self.c_trtnet = NULL
|
||||||
|
|
||||||
|
def __init__(PyTrtGooglenet self,
|
||||||
|
str engine_path, tuple shape0, tuple shape1):
|
||||||
|
assert len(shape0) == 3 and len(shape1) == 3
|
||||||
|
self.c_trtnet = new TrtGooglenet()
|
||||||
|
self.data_dims = shape0
|
||||||
|
self.prob_dims = shape1
|
||||||
|
cdef int[:] v0 = np.array(shape0, dtype=np.intc)
|
||||||
|
cdef int[:] v1 = np.array(shape1, dtype=np.intc)
|
||||||
|
cdef string c_str = engine_path.encode('UTF-8')
|
||||||
|
self.c_trtnet.initEngine(c_str, &v0[0], &v1[0])
|
||||||
|
|
||||||
|
def forward(PyTrtGooglenet self,
|
||||||
|
np.ndarray[np.float32_t, ndim=4] np_imgs not None):
|
||||||
|
"""Do a forward() computation on the input batch of imgs."""
|
||||||
|
assert np_imgs.shape[0] == 1 # only accept batch_size = 1
|
||||||
|
if not np_imgs.flags['C_CONTIGUOUS']:
|
||||||
|
np_imgs = np.ascontiguousarray(np_imgs)
|
||||||
|
np_prob = np.ascontiguousarray(
|
||||||
|
np.zeros((1,) + self.prob_dims, dtype=np.float32)
|
||||||
|
)
|
||||||
|
cdef float[:,:,:,::1] v_imgs = np_imgs
|
||||||
|
cdef float[:,:,:,::1] v_prob = np_prob
|
||||||
|
self.c_trtnet.forward(&v_imgs[0][0][0][0], &v_prob[0][0][0][0])
|
||||||
|
return { 'prob': np_prob }
|
||||||
|
|
||||||
|
def destroy(PyTrtGooglenet self):
|
||||||
|
self.c_trtnet.destroy()
|
||||||
|
|
||||||
|
|
||||||
|
cdef class PyTrtMtcnn:
|
||||||
|
cdef TrtMtcnnDet *c_trtnet
|
||||||
|
cdef int batch_size
|
||||||
|
cdef int num_bindings
|
||||||
|
cdef tuple data_dims, prob1_dims, boxes_dims, marks_dims
|
||||||
|
|
||||||
|
def __cinit__(PyTrtMtcnn self):
|
||||||
|
self.c_trtnet = NULL
|
||||||
|
|
||||||
|
def __init__(PyTrtMtcnn self,
|
||||||
|
str engine_path,
|
||||||
|
tuple shape0, tuple shape1, tuple shape2, tuple shape3=None):
|
||||||
|
self.num_bindings = 4 if shape3 else 3
|
||||||
|
assert len(shape0) == 3 and len(shape1) == 3 and len(shape2) == 3
|
||||||
|
if shape3: assert len(shape3) == 3
|
||||||
|
else: shape3 = (0, 0, 0) # set to a dummy shape
|
||||||
|
self.c_trtnet = new TrtMtcnnDet()
|
||||||
|
self.batch_size = 0
|
||||||
|
self.data_dims = shape0
|
||||||
|
self.prob1_dims = shape1
|
||||||
|
self.boxes_dims = shape2
|
||||||
|
self.marks_dims = shape3
|
||||||
|
cdef int[:] v0 = np.array(shape0, dtype=np.intc)
|
||||||
|
cdef int[:] v1 = np.array(shape1, dtype=np.intc)
|
||||||
|
cdef int[:] v2 = np.array(shape2, dtype=np.intc)
|
||||||
|
cdef int[:] v3 = np.array(shape3, dtype=np.intc)
|
||||||
|
cdef string c_str = engine_path.encode('UTF-8')
|
||||||
|
if 'det1' in engine_path:
|
||||||
|
self.c_trtnet.initDet1(c_str, &v0[0], &v1[0], &v2[0])
|
||||||
|
elif 'det2' in engine_path:
|
||||||
|
self.c_trtnet.initDet2(c_str, &v0[0], &v1[0], &v2[0])
|
||||||
|
elif 'det3' in engine_path:
|
||||||
|
self.c_trtnet.initDet3(c_str, &v0[0], &v1[0], &v2[0], &v3[0])
|
||||||
|
else:
|
||||||
|
raise ValueError('engine is neither of det1, det2 or det3!')
|
||||||
|
|
||||||
|
def set_batchsize(PyTrtMtcnn self, int batch_size):
|
||||||
|
self.c_trtnet.setBatchSize(batch_size)
|
||||||
|
self.batch_size = batch_size
|
||||||
|
|
||||||
|
def _forward_3(PyTrtMtcnn self,
|
||||||
|
np.ndarray[np.float32_t, ndim=4] np_imgs not None,
|
||||||
|
np.ndarray[np.float32_t, ndim=4] np_prob1 not None,
|
||||||
|
np.ndarray[np.float32_t, ndim=4] np_boxes not None):
|
||||||
|
cdef float[:,:,:,::1] v_imgs = np_imgs
|
||||||
|
cdef float[:,:,:,::1] v_probs = np_prob1
|
||||||
|
cdef float[:,:,:,::1] v_boxes = np_boxes
|
||||||
|
self.c_trtnet.forward(&v_imgs[0][0][0][0],
|
||||||
|
&v_probs[0][0][0][0],
|
||||||
|
&v_boxes[0][0][0][0])
|
||||||
|
return { 'prob1': np_prob1, 'boxes': np_boxes }
|
||||||
|
|
||||||
|
def _forward_4(PyTrtMtcnn self,
|
||||||
|
np.ndarray[np.float32_t, ndim=4] np_imgs not None,
|
||||||
|
np.ndarray[np.float32_t, ndim=4] np_prob1 not None,
|
||||||
|
np.ndarray[np.float32_t, ndim=4] np_boxes not None,
|
||||||
|
np.ndarray[np.float32_t, ndim=4] np_marks not None):
|
||||||
|
cdef float[:,:,:,::1] v_imgs = np_imgs
|
||||||
|
cdef float[:,:,:,::1] v_probs = np_prob1
|
||||||
|
cdef float[:,:,:,::1] v_boxes = np_boxes
|
||||||
|
cdef float[:,:,:,::1] v_marks = np_marks
|
||||||
|
self.c_trtnet.forward(&v_imgs[0][0][0][0],
|
||||||
|
&v_probs[0][0][0][0],
|
||||||
|
&v_boxes[0][0][0][0],
|
||||||
|
&v_marks[0][0][0][0])
|
||||||
|
return { 'prob1': np_prob1, 'boxes': np_boxes, 'landmarks': np_marks }
|
||||||
|
|
||||||
|
def forward(PyTrtMtcnn self,
|
||||||
|
np.ndarray[np.float32_t, ndim=4] np_imgs not None):
|
||||||
|
"""Do a forward() computation on the input batch of imgs."""
|
||||||
|
assert(np_imgs.shape[0] == self.batch_size)
|
||||||
|
if not np_imgs.flags['C_CONTIGUOUS']:
|
||||||
|
np_imgs = np.ascontiguousarray(np_imgs)
|
||||||
|
np_prob1 = np.ascontiguousarray(
|
||||||
|
np.zeros((self.batch_size,) + self.prob1_dims, dtype=np.float32)
|
||||||
|
)
|
||||||
|
np_boxes = np.ascontiguousarray(
|
||||||
|
np.zeros((self.batch_size,) + self.boxes_dims, dtype=np.float32)
|
||||||
|
)
|
||||||
|
np_marks = np.ascontiguousarray(
|
||||||
|
np.zeros((self.batch_size,) + self.marks_dims, dtype=np.float32)
|
||||||
|
)
|
||||||
|
if self.num_bindings == 3:
|
||||||
|
return self._forward_3(np_imgs, np_prob1, np_boxes)
|
||||||
|
else: # self.num_bindings == 4
|
||||||
|
return self._forward_4(np_imgs, np_prob1, np_boxes, np_marks)
|
||||||
|
|
||||||
|
def destroy(PyTrtMtcnn self):
|
||||||
|
self.c_trtnet.destroy()
|
||||||
|
|
@ -0,0 +1,47 @@
|
||||||
|
from distutils.core import setup
|
||||||
|
from distutils.extension import Extension
|
||||||
|
from Cython.Distutils import build_ext
|
||||||
|
from Cython.Build import cythonize
|
||||||
|
|
||||||
|
import numpy
|
||||||
|
|
||||||
|
library_dirs = [
|
||||||
|
'/usr/local/cuda/lib64',
|
||||||
|
'/usr/local/TensorRT-7.1.3.4/lib', # for my x86_64 PC
|
||||||
|
'/usr/local/lib',
|
||||||
|
]
|
||||||
|
|
||||||
|
libraries = [
|
||||||
|
'nvinfer',
|
||||||
|
'cudnn',
|
||||||
|
'cublas',
|
||||||
|
'cudart_static',
|
||||||
|
'nvToolsExt',
|
||||||
|
'cudart',
|
||||||
|
'rt',
|
||||||
|
]
|
||||||
|
|
||||||
|
include_dirs = [
|
||||||
|
# in case the following numpy include path does not work, you
|
||||||
|
# could replace it manually with, say,
|
||||||
|
# '-I/usr/local/lib/python3.6/dist-packages/numpy/core/include',
|
||||||
|
'-I' + numpy.__path__[0] + '/core/include',
|
||||||
|
'-I/usr/local/cuda/include',
|
||||||
|
'-I/usr/local/TensorRT-7.1.3.4/include', # for my x86_64 PC
|
||||||
|
'-I/usr/local/include',
|
||||||
|
]
|
||||||
|
|
||||||
|
setup(
|
||||||
|
cmdclass={'build_ext': build_ext},
|
||||||
|
ext_modules=cythonize(
|
||||||
|
Extension(
|
||||||
|
'pytrt',
|
||||||
|
sources=['pytrt.pyx'],
|
||||||
|
language='c++',
|
||||||
|
library_dirs=library_dirs,
|
||||||
|
libraries=libraries,
|
||||||
|
extra_compile_args=['-O3', '-std=c++11'] + include_dirs
|
||||||
|
),
|
||||||
|
compiler_directives={'language_level': '3'}
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
@ -0,0 +1,12 @@
|
||||||
|
Reference:
|
||||||
|
|
||||||
|
1. [AastaNV/TRT_object_detection](https://github.com/AastaNV/TRT_object_detection)
|
||||||
|
2. ['sampleUffSSD' in TensorRT samples](https://docs.nvidia.com/deeplearning/sdk/tensorrt-sample-support-guide/index.html#uffssd_sample)
|
||||||
|
|
||||||
|
Sources of the trained models:
|
||||||
|
|
||||||
|
* 'ssd_mobilenet_v1_coco.pb' and 'ssd_mobilnet_v2_coco.pb': This is just the 'frozen_inference_graph.pb' file in [ssd_mobilenet_v1_coco_2018_01_28.tar.gz](http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2018_01_28.tar.gz) and [ssd_mobilenet_v2_coco_2018_03_29.tar.gz](http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz), i.e. 2 of the trained models in [TensorFlow 1 Detection Model Zoo](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md).
|
||||||
|
|
||||||
|
* 'ssd_mobilenet_v1_egohands.pb' and 'ssd_mobilenet_v2_egohands.pb': These models are trained using my [Hand Detection Tutorial](https://github.com/jkjung-avt/hand-detection-tutorial) code. After training, just run the [export.sh](https://github.com/jkjung-avt/hand-detection-tutorial/blob/master/export.sh) script to generated the frozen graph (pb) files.
|
||||||
|
|
||||||
|
* I've also added support for [ssd_inception_v2_coco](http://download.tensorflow.org/models/object_detection/ssd_inception_v2_coco_2018_01_28.tar.gz) in the code. You could download the .pb by following the link.
|
||||||
|
|
@ -0,0 +1,304 @@
|
||||||
|
"""build_engine.py
|
||||||
|
|
||||||
|
This script converts a SSD model (pb) to UFF and subsequently builds
|
||||||
|
the TensorRT engine.
|
||||||
|
|
||||||
|
Input : ssd_mobilenet_v[1|2]_[coco|egohands].pb
|
||||||
|
Output: TRT_ssd_mobilenet_v[1|2]_[coco|egohands].bin
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
import ctypes
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import uff
|
||||||
|
import tensorrt as trt
|
||||||
|
import graphsurgeon as gs
|
||||||
|
|
||||||
|
|
||||||
|
DIR_NAME = os.path.dirname(__file__)
|
||||||
|
LIB_FILE = os.path.abspath(os.path.join(DIR_NAME, 'libflattenconcat.so'))
|
||||||
|
MODEL_SPECS = {
|
||||||
|
'ssd_mobilenet_v1_coco': {
|
||||||
|
'input_pb': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_mobilenet_v1_coco.pb')),
|
||||||
|
'tmp_uff': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_mobilenet_v1_coco.uff')),
|
||||||
|
'output_bin': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'TRT_ssd_mobilenet_v1_coco.bin')),
|
||||||
|
'num_classes': 91,
|
||||||
|
'min_size': 0.2,
|
||||||
|
'max_size': 0.95,
|
||||||
|
'input_order': [0, 2, 1], # order of loc_data, conf_data, priorbox_data
|
||||||
|
},
|
||||||
|
'ssd_mobilenet_v1_egohands': {
|
||||||
|
'input_pb': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_mobilenet_v1_egohands.pb')),
|
||||||
|
'tmp_uff': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_mobilenet_v1_egohands.uff')),
|
||||||
|
'output_bin': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'TRT_ssd_mobilenet_v1_egohands.bin')),
|
||||||
|
'num_classes': 2,
|
||||||
|
'min_size': 0.05,
|
||||||
|
'max_size': 0.95,
|
||||||
|
'input_order': [0, 2, 1], # order of loc_data, conf_data, priorbox_data
|
||||||
|
},
|
||||||
|
'ssd_mobilenet_v2_coco': {
|
||||||
|
'input_pb': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_mobilenet_v2_coco.pb')),
|
||||||
|
'tmp_uff': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_mobilenet_v2_coco.uff')),
|
||||||
|
'output_bin': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'TRT_ssd_mobilenet_v2_coco.bin')),
|
||||||
|
'num_classes': 91,
|
||||||
|
'min_size': 0.2,
|
||||||
|
'max_size': 0.95,
|
||||||
|
'input_order': [1, 0, 2], # order of loc_data, conf_data, priorbox_data
|
||||||
|
},
|
||||||
|
'ssd_mobilenet_v2_egohands': {
|
||||||
|
'input_pb': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_mobilenet_v2_egohands.pb')),
|
||||||
|
'tmp_uff': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_mobilenet_v2_egohands.uff')),
|
||||||
|
'output_bin': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'TRT_ssd_mobilenet_v2_egohands.bin')),
|
||||||
|
'num_classes': 2,
|
||||||
|
'min_size': 0.05,
|
||||||
|
'max_size': 0.95,
|
||||||
|
'input_order': [0, 2, 1], # order of loc_data, conf_data, priorbox_data
|
||||||
|
},
|
||||||
|
'ssd_inception_v2_coco': {
|
||||||
|
'input_pb': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_inception_v2_coco.pb')),
|
||||||
|
'tmp_uff': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssd_inception_v2_coco.uff')),
|
||||||
|
'output_bin': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'TRT_ssd_inception_v2_coco.bin')),
|
||||||
|
'num_classes': 91,
|
||||||
|
'min_size': 0.2,
|
||||||
|
'max_size': 0.95,
|
||||||
|
'input_order': [0, 2, 1], # order of loc_data, conf_data, priorbox_data
|
||||||
|
},
|
||||||
|
'ssdlite_mobilenet_v2_coco': {
|
||||||
|
'input_pb': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssdlite_mobilenet_v2_coco.pb')),
|
||||||
|
'tmp_uff': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'ssdlite_mobilenet_v2_coco.uff')),
|
||||||
|
'output_bin': os.path.abspath(os.path.join(
|
||||||
|
DIR_NAME, 'TRT_ssdlite_mobilenet_v2_coco.bin')),
|
||||||
|
'num_classes': 91,
|
||||||
|
'min_size': 0.2,
|
||||||
|
'max_size': 0.95,
|
||||||
|
'input_order': [0, 2, 1], # order of loc_data, conf_data, priorbox_data
|
||||||
|
},
|
||||||
|
}
|
||||||
|
INPUT_DIMS = (3, 300, 300)
|
||||||
|
DEBUG_UFF = False
|
||||||
|
|
||||||
|
|
||||||
|
def replace_addv2(graph):
|
||||||
|
"""Replace all 'AddV2' in the graph with 'Add'.
|
||||||
|
|
||||||
|
'AddV2' is not supported by UFF parser.
|
||||||
|
|
||||||
|
Reference:
|
||||||
|
1. https://github.com/jkjung-avt/tensorrt_demos/issues/113#issuecomment-629900809
|
||||||
|
"""
|
||||||
|
for node in graph.find_nodes_by_op('AddV2'):
|
||||||
|
gs.update_node(node, op='Add')
|
||||||
|
return graph
|
||||||
|
|
||||||
|
|
||||||
|
def replace_fusedbnv3(graph):
|
||||||
|
"""Replace all 'FusedBatchNormV3' in the graph with 'FusedBatchNorm'.
|
||||||
|
|
||||||
|
'FusedBatchNormV3' is not supported by UFF parser.
|
||||||
|
|
||||||
|
Reference:
|
||||||
|
1. https://devtalk.nvidia.com/default/topic/1066445/tensorrt/tensorrt-6-0-1-tensorflow-1-14-no-conversion-function-registered-for-layer-fusedbatchnormv3-yet/post/5403567/#5403567
|
||||||
|
2. https://github.com/jkjung-avt/tensorrt_demos/issues/76#issuecomment-607879831
|
||||||
|
"""
|
||||||
|
for node in graph.find_nodes_by_op('FusedBatchNormV3'):
|
||||||
|
gs.update_node(node, op='FusedBatchNorm')
|
||||||
|
return graph
|
||||||
|
|
||||||
|
|
||||||
|
def add_anchor_input(graph):
|
||||||
|
"""Add the missing const input for the GridAnchor node.
|
||||||
|
|
||||||
|
Reference:
|
||||||
|
1. https://www.minds.ai/post/deploying-ssd-mobilenet-v2-on-the-nvidia-jetson-and-nano-platforms
|
||||||
|
"""
|
||||||
|
data = np.array([1, 1], dtype=np.float32)
|
||||||
|
anchor_input = gs.create_node('AnchorInput', 'Const', value=data)
|
||||||
|
graph.append(anchor_input)
|
||||||
|
graph.find_nodes_by_op('GridAnchor_TRT')[0].input.insert(0, 'AnchorInput')
|
||||||
|
return graph
|
||||||
|
|
||||||
|
def add_plugin(graph, model, spec):
|
||||||
|
"""add_plugin
|
||||||
|
|
||||||
|
Reference:
|
||||||
|
1. https://github.com/AastaNV/TRT_object_detection/blob/master/config/model_ssd_mobilenet_v1_coco_2018_01_28.py
|
||||||
|
2. https://github.com/AastaNV/TRT_object_detection/blob/master/config/model_ssd_mobilenet_v2_coco_2018_03_29.py
|
||||||
|
3. https://devtalk.nvidia.com/default/topic/1050465/jetson-nano/how-to-write-config-py-for-converting-ssd-mobilenetv2-to-uff-format/post/5333033/#5333033
|
||||||
|
"""
|
||||||
|
numClasses = spec['num_classes']
|
||||||
|
minSize = spec['min_size']
|
||||||
|
maxSize = spec['max_size']
|
||||||
|
inputOrder = spec['input_order']
|
||||||
|
|
||||||
|
all_assert_nodes = graph.find_nodes_by_op('Assert')
|
||||||
|
graph.remove(all_assert_nodes, remove_exclusive_dependencies=True)
|
||||||
|
|
||||||
|
all_identity_nodes = graph.find_nodes_by_op('Identity')
|
||||||
|
graph.forward_inputs(all_identity_nodes)
|
||||||
|
|
||||||
|
Input = gs.create_plugin_node(
|
||||||
|
name='Input',
|
||||||
|
op='Placeholder',
|
||||||
|
shape=(1,) + INPUT_DIMS
|
||||||
|
)
|
||||||
|
|
||||||
|
PriorBox = gs.create_plugin_node(
|
||||||
|
name='MultipleGridAnchorGenerator',
|
||||||
|
op='GridAnchor_TRT',
|
||||||
|
minSize=minSize, # was 0.2
|
||||||
|
maxSize=maxSize, # was 0.95
|
||||||
|
aspectRatios=[1.0, 2.0, 0.5, 3.0, 0.33],
|
||||||
|
variance=[0.1, 0.1, 0.2, 0.2],
|
||||||
|
featureMapShapes=[19, 10, 5, 3, 2, 1],
|
||||||
|
numLayers=6
|
||||||
|
)
|
||||||
|
|
||||||
|
NMS = gs.create_plugin_node(
|
||||||
|
name='NMS',
|
||||||
|
op='NMS_TRT',
|
||||||
|
shareLocation=1,
|
||||||
|
varianceEncodedInTarget=0,
|
||||||
|
backgroundLabelId=0,
|
||||||
|
confidenceThreshold=0.3, # was 1e-8
|
||||||
|
nmsThreshold=0.6,
|
||||||
|
topK=100,
|
||||||
|
keepTopK=100,
|
||||||
|
numClasses=numClasses, # was 91
|
||||||
|
inputOrder=inputOrder,
|
||||||
|
confSigmoid=1,
|
||||||
|
isNormalized=1
|
||||||
|
)
|
||||||
|
|
||||||
|
concat_priorbox = gs.create_node(
|
||||||
|
'concat_priorbox',
|
||||||
|
op='ConcatV2',
|
||||||
|
axis=2
|
||||||
|
)
|
||||||
|
|
||||||
|
if trt.__version__[0] >= '7':
|
||||||
|
concat_box_loc = gs.create_plugin_node(
|
||||||
|
'concat_box_loc',
|
||||||
|
op='FlattenConcat_TRT',
|
||||||
|
axis=1,
|
||||||
|
ignoreBatch=0
|
||||||
|
)
|
||||||
|
concat_box_conf = gs.create_plugin_node(
|
||||||
|
'concat_box_conf',
|
||||||
|
op='FlattenConcat_TRT',
|
||||||
|
axis=1,
|
||||||
|
ignoreBatch=0
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
concat_box_loc = gs.create_plugin_node(
|
||||||
|
'concat_box_loc',
|
||||||
|
op='FlattenConcat_TRT'
|
||||||
|
)
|
||||||
|
concat_box_conf = gs.create_plugin_node(
|
||||||
|
'concat_box_conf',
|
||||||
|
op='FlattenConcat_TRT'
|
||||||
|
)
|
||||||
|
|
||||||
|
namespace_for_removal = [
|
||||||
|
'ToFloat',
|
||||||
|
'image_tensor',
|
||||||
|
'Preprocessor/map/TensorArrayStack_1/TensorArrayGatherV3',
|
||||||
|
]
|
||||||
|
namespace_plugin_map = {
|
||||||
|
'MultipleGridAnchorGenerator': PriorBox,
|
||||||
|
'Postprocessor': NMS,
|
||||||
|
'Preprocessor': Input,
|
||||||
|
'ToFloat': Input,
|
||||||
|
'Cast': Input, # added for models trained with tf 1.15+
|
||||||
|
'image_tensor': Input,
|
||||||
|
'MultipleGridAnchorGenerator/Concatenate': concat_priorbox, # for 'ssd_mobilenet_v1_coco'
|
||||||
|
'Concatenate': concat_priorbox, # for other models
|
||||||
|
'concat': concat_box_loc,
|
||||||
|
'concat_1': concat_box_conf
|
||||||
|
}
|
||||||
|
|
||||||
|
graph.remove(graph.find_nodes_by_path(['Preprocessor/map/TensorArrayStack_1/TensorArrayGatherV3']), remove_exclusive_dependencies=False) # for 'ssd_inception_v2_coco'
|
||||||
|
|
||||||
|
graph.collapse_namespaces(namespace_plugin_map)
|
||||||
|
graph = replace_addv2(graph)
|
||||||
|
graph = replace_fusedbnv3(graph)
|
||||||
|
|
||||||
|
if 'image_tensor:0' in graph.find_nodes_by_name('Input')[0].input:
|
||||||
|
graph.find_nodes_by_name('Input')[0].input.remove('image_tensor:0')
|
||||||
|
if 'Input' in graph.find_nodes_by_name('NMS')[0].input:
|
||||||
|
graph.find_nodes_by_name('NMS')[0].input.remove('Input')
|
||||||
|
# Remove the Squeeze to avoid "Assertion 'isPlugin(layerName)' failed"
|
||||||
|
graph.forward_inputs(graph.find_node_inputs_by_name(graph.graph_outputs[0], 'Squeeze'))
|
||||||
|
if 'anchors' in [node.name for node in graph.graph_outputs]:
|
||||||
|
graph.remove('anchors', remove_exclusive_dependencies=False)
|
||||||
|
if len(graph.find_nodes_by_op('GridAnchor_TRT')[0].input) < 1:
|
||||||
|
graph = add_anchor_input(graph)
|
||||||
|
if 'NMS' not in [node.name for node in graph.graph_outputs]:
|
||||||
|
graph.remove(graph.graph_outputs, remove_exclusive_dependencies=False)
|
||||||
|
if 'NMS' not in [node.name for node in graph.graph_outputs]:
|
||||||
|
# We expect 'NMS' to be one of the outputs
|
||||||
|
raise RuntimeError('bad graph_outputs')
|
||||||
|
|
||||||
|
return graph
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('model', type=str, choices=list(MODEL_SPECS.keys()))
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
# initialize
|
||||||
|
if trt.__version__[0] < '7':
|
||||||
|
ctypes.CDLL(LIB_FILE)
|
||||||
|
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
|
||||||
|
trt.init_libnvinfer_plugins(TRT_LOGGER, '')
|
||||||
|
|
||||||
|
# compile the model into TensorRT engine
|
||||||
|
model = args.model
|
||||||
|
spec = MODEL_SPECS[model]
|
||||||
|
dynamic_graph = add_plugin(
|
||||||
|
gs.DynamicGraph(spec['input_pb']),
|
||||||
|
model,
|
||||||
|
spec)
|
||||||
|
_ = uff.from_tensorflow(
|
||||||
|
dynamic_graph.as_graph_def(),
|
||||||
|
output_nodes=['NMS'],
|
||||||
|
output_filename=spec['tmp_uff'],
|
||||||
|
text=True,
|
||||||
|
debug_mode=DEBUG_UFF)
|
||||||
|
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.UffParser() as parser:
|
||||||
|
builder.max_workspace_size = 1 << 28
|
||||||
|
builder.max_batch_size = 1
|
||||||
|
builder.fp16_mode = True
|
||||||
|
|
||||||
|
parser.register_input('Input', INPUT_DIMS)
|
||||||
|
parser.register_output('MarkOutput_0')
|
||||||
|
parser.parse(spec['tmp_uff'], network)
|
||||||
|
engine = builder.build_cuda_engine(network)
|
||||||
|
|
||||||
|
buf = engine.serialize()
|
||||||
|
with open(spec['output_bin'], 'wb') as f:
|
||||||
|
f.write(buf)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
set -xe
|
||||||
|
|
||||||
|
for model in ssd_mobilenet_v1_coco \
|
||||||
|
ssd_mobilenet_v1_egohands \
|
||||||
|
ssd_mobilenet_v2_coco \
|
||||||
|
ssd_mobilenet_v2_egohands ; do
|
||||||
|
python3 build_engine.py ${model}
|
||||||
|
done
|
||||||
|
|
@ -0,0 +1,12 @@
|
||||||
|
diff --git a/node_manipulation.py b/node_manipulation.py
|
||||||
|
index d2d012a..1ef30a0 100644
|
||||||
|
--- a/node_manipulation.py
|
||||||
|
+++ b/node_manipulation.py
|
||||||
|
@@ -30,6 +30,7 @@ def create_node(name, op=None, _do_suffix=False, **kwargs):
|
||||||
|
node = NodeDef()
|
||||||
|
node.name = name
|
||||||
|
node.op = op if op else name
|
||||||
|
+ node.attr["dtype"].type = 1
|
||||||
|
for key, val in kwargs.items():
|
||||||
|
if key == "dtype":
|
||||||
|
node.attr["dtype"].type = val.as_datatype_enum
|
||||||
|
|
@ -0,0 +1,11 @@
|
||||||
|
diff -Naur a/node_manipulation.py b/node_manipulation.py
|
||||||
|
--- a/node_manipulation.py 2019-10-24 13:17:10.203943256 +0800
|
||||||
|
+++ b/node_manipulation.py 2019-10-24 13:19:08.851943211 +0800
|
||||||
|
@@ -39,6 +39,7 @@
|
||||||
|
'''
|
||||||
|
node.name = name or node.name
|
||||||
|
node.op = op or node.op or node.name
|
||||||
|
+ node.attr["dtype"].type = 1
|
||||||
|
for key, val in kwargs.items():
|
||||||
|
if isinstance(val, tf.DType):
|
||||||
|
node.attr[key].type = val.as_datatype_enum
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
--- a/node_manipulation.py 2020-07-14 08:34:41.959988887 +0800
|
||||||
|
+++ b/node_manipulation.py 2020-07-14 08:36:11.863988853 +0800
|
||||||
|
@@ -86,6 +86,7 @@
|
||||||
|
'''
|
||||||
|
node.name = name or node.name
|
||||||
|
node.op = op or node.op or node.name
|
||||||
|
+ node.attr["dtype"].type = 1
|
||||||
|
for key, val in kwargs.items():
|
||||||
|
if isinstance(val, tf.DType):
|
||||||
|
node.attr[key].type = val.as_datatype_enum
|
||||||
|
|
@ -0,0 +1,36 @@
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
set -e
|
||||||
|
|
||||||
|
# install pycuda if necessary
|
||||||
|
if ! python3 -c "import pycuda" > /dev/null 2>&1; then
|
||||||
|
./install_pycuda.sh
|
||||||
|
fi
|
||||||
|
|
||||||
|
echo "** Patch 'graphsurgeon.py' in TensorRT"
|
||||||
|
|
||||||
|
script_path=$(realpath $0)
|
||||||
|
gs_path=$(ls /usr/lib/python3.?/dist-packages/graphsurgeon/node_manipulation.py)
|
||||||
|
patch_path=$(dirname $script_path)/graphsurgeon.patch
|
||||||
|
|
||||||
|
if head -30 ${gs_path} | tail -1 | grep -q NodeDef; then
|
||||||
|
# This is for JetPack-4.2
|
||||||
|
sudo patch -N -p1 -r - ${gs_path} ${patch_path}-4.2 && echo
|
||||||
|
fi
|
||||||
|
if head -22 ${gs_path} | tail -1 | grep -q update_node; then
|
||||||
|
# This is for JetPack-4.2.2
|
||||||
|
sudo patch -N -p1 -r - ${gs_path} ${patch_path}-4.2.2 && echo
|
||||||
|
fi
|
||||||
|
if head -69 ${gs_path} | tail -1 | grep -q update_node; then
|
||||||
|
# This is for JetPack-4.4
|
||||||
|
sudo patch -N -p1 -r - ${gs_path} ${patch_path}-4.4 && echo
|
||||||
|
fi
|
||||||
|
|
||||||
|
echo "** Making symbolic link of libflattenconcat.so"
|
||||||
|
|
||||||
|
trt_version=$(echo /usr/lib/aarch64-linux-gnu/libnvinfer.so.? | cut -d '.' -f 3)
|
||||||
|
if [ "${trt_version}" = "5" ] || [ "${trt_version}" = "6" ]; then
|
||||||
|
ln -sf libflattenconcat.so.${trt_version} libflattenconcat.so
|
||||||
|
fi
|
||||||
|
|
||||||
|
echo "** Installation done"
|
||||||
|
|
@ -0,0 +1,43 @@
|
||||||
|
#!/bin/bash
|
||||||
|
#
|
||||||
|
# Reference for installing 'pycuda': https://wiki.tiker.net/PyCuda/Installation/Linux/Ubuntu
|
||||||
|
|
||||||
|
set -e
|
||||||
|
|
||||||
|
if ! which nvcc > /dev/null; then
|
||||||
|
echo "ERROR: nvcc not found"
|
||||||
|
exit
|
||||||
|
fi
|
||||||
|
|
||||||
|
arch=$(uname -m)
|
||||||
|
folder=${HOME}/src
|
||||||
|
mkdir -p $folder
|
||||||
|
|
||||||
|
echo "** Install requirements"
|
||||||
|
sudo apt-get install -y build-essential python3-dev
|
||||||
|
sudo apt-get install -y libboost-python-dev libboost-thread-dev
|
||||||
|
sudo pip3 install setuptools
|
||||||
|
|
||||||
|
boost_pylib=$(basename /usr/lib/${arch}-linux-gnu/libboost_python*-py3?.so)
|
||||||
|
boost_pylibname=${boost_pylib%.so}
|
||||||
|
boost_pyname=${boost_pylibname/lib/}
|
||||||
|
|
||||||
|
echo "** Download pycuda-2019.1.2 sources"
|
||||||
|
pushd $folder
|
||||||
|
if [ ! -f pycuda-2019.1.2.tar.gz ]; then
|
||||||
|
wget https://files.pythonhosted.org/packages/5e/3f/5658c38579b41866ba21ee1b5020b8225cec86fe717e4b1c5c972de0a33c/pycuda-2019.1.2.tar.gz
|
||||||
|
fi
|
||||||
|
|
||||||
|
echo "** Build and install pycuda-2019.1.2"
|
||||||
|
CPU_CORES=$(nproc)
|
||||||
|
echo "** cpu cores available: " $CPU_CORES
|
||||||
|
tar xzvf pycuda-2019.1.2.tar.gz
|
||||||
|
cd pycuda-2019.1.2
|
||||||
|
python3 ./configure.py --python-exe=/usr/bin/python3 --cuda-root=/usr/local/cuda --cudadrv-lib-dir=/usr/lib/${arch}-linux-gnu --boost-inc-dir=/usr/include --boost-lib-dir=/usr/lib/${arch}-linux-gnu --boost-python-libname=${boost_pyname} --boost-thread-libname=boost_thread --no-use-shipped-boost
|
||||||
|
make -j$CPU_CORES
|
||||||
|
python3 setup.py build
|
||||||
|
sudo python3 setup.py install
|
||||||
|
|
||||||
|
popd
|
||||||
|
|
||||||
|
python3 -c "import pycuda; print('pycuda version:', pycuda.VERSION)"
|
||||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,12 @@
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
import pycuda.autoinit
|
||||||
|
from utils.modnet import TrtMODNet
|
||||||
|
|
||||||
|
img = cv2.imread('modnet/image.jpg')
|
||||||
|
modnet = TrtMODNet()
|
||||||
|
matte = modnet.infer(img)
|
||||||
|
cv2.imshow('Matte', matte)
|
||||||
|
cv2.waitKey(0)
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
@ -0,0 +1,303 @@
|
||||||
|
// trtNet.cpp
|
||||||
|
|
||||||
|
#include "trtNet.h"
|
||||||
|
|
||||||
|
using namespace nvinfer1;
|
||||||
|
using namespace nvcaffeparser1;
|
||||||
|
|
||||||
|
#define CHECK(status) \
|
||||||
|
do { \
|
||||||
|
auto ret = status; \
|
||||||
|
if (ret != 0) { \
|
||||||
|
std::cerr << "Cuda failure in file '" << __FILE__ \
|
||||||
|
<< "' line " << __LINE__ \
|
||||||
|
<< ": " << ret << std::endl; \
|
||||||
|
abort(); \
|
||||||
|
} \
|
||||||
|
} while (0)
|
||||||
|
|
||||||
|
#define my_assert(EXP, MSG) \
|
||||||
|
do { \
|
||||||
|
if (!(EXP)) { \
|
||||||
|
std::cerr << "Assertion fail in file '" << __FILE__ \
|
||||||
|
<< "' line " << __LINE__ \
|
||||||
|
<< ": " << (MSG) << std:: endl; \
|
||||||
|
throw std::exception(); \
|
||||||
|
} \
|
||||||
|
} while (0)
|
||||||
|
|
||||||
|
|
||||||
|
namespace trtnet {
|
||||||
|
|
||||||
|
//
|
||||||
|
// TrtGooglenet stuffs
|
||||||
|
//
|
||||||
|
|
||||||
|
TrtGooglenet::TrtGooglenet()
|
||||||
|
{
|
||||||
|
for (int i = 0; i < 2; i++) {
|
||||||
|
_gpu_buffers[i] = nullptr;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtGooglenet::_initEngine(std::string filePath)
|
||||||
|
{
|
||||||
|
_gieModelStream = new IHostMemoryFromFile(filePath);
|
||||||
|
_runtime = createInferRuntime(_gLogger);
|
||||||
|
my_assert(_runtime != nullptr, "_runtime is null");
|
||||||
|
_engine = _runtime->deserializeCudaEngine(
|
||||||
|
_gieModelStream->data(),
|
||||||
|
_gieModelStream->size(),
|
||||||
|
nullptr);
|
||||||
|
my_assert(_engine != nullptr, "_engine is null");
|
||||||
|
my_assert(_engine->getNbBindings() == 2, "wrong number of bindings");
|
||||||
|
_binding_data = _engine->getBindingIndex("data");
|
||||||
|
my_assert(_engine->bindingIsInput(_binding_data) == true, "bad type of binding 'data'");
|
||||||
|
_binding_prob = _engine->getBindingIndex("prob");
|
||||||
|
my_assert(_engine->bindingIsInput(_binding_prob) == false, "bad type of binding 'prob'");
|
||||||
|
_context = _engine->createExecutionContext();
|
||||||
|
my_assert(_context != nullptr, "_context is null");
|
||||||
|
_gieModelStream->destroy();
|
||||||
|
CHECK(cudaStreamCreate(&_stream));
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtGooglenet::initEngine(std::string filePath, int dataDims[3], int probDims[3])
|
||||||
|
{
|
||||||
|
_initEngine(filePath);
|
||||||
|
#if NV_TENSORRT_MAJOR >= 4
|
||||||
|
Dims3 d;
|
||||||
|
d = static_cast<Dims3&&>(_engine->getBindingDimensions(_binding_data));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'data'");
|
||||||
|
my_assert(d.d[0] == dataDims[0] && d.d[1] == dataDims[1] && d.d[2] == dataDims[2], "bad dims for 'data'");
|
||||||
|
_blob_sizes[_binding_data] = d.d[0] * d.d[1] * d.d[2];
|
||||||
|
|
||||||
|
d = static_cast<Dims3&&>(_engine->getBindingDimensions(_binding_prob));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'prob'");
|
||||||
|
my_assert(d.d[0] == probDims[0] && d.d[1] == probDims[1] && d.d[2] == probDims[2], "bad dims for 'prob'");
|
||||||
|
_blob_sizes[_binding_prob] = d.d[0] * d.d[1] * d.d[2];
|
||||||
|
#else // NV_TENSORRT_MAJOR < 4
|
||||||
|
DimsCHW d;
|
||||||
|
d = static_cast<DimsCHW&&>(_engine->getBindingDimensions(_binding_data));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'data'");
|
||||||
|
my_assert(d.c() == dataDims[0] && d.h() == dataDims[1] && d.w() == dataDims[2], "bad dims for 'data'");
|
||||||
|
_blob_sizes[_binding_data] = d.c() * d.h() * d.w();
|
||||||
|
|
||||||
|
d = static_cast<DimsCHW&&>(_engine->getBindingDimensions(_binding_prob));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'prob'");
|
||||||
|
my_assert(d.c() == probDims[0] && d.h() == probDims[1] && d.w() == probDims[2], "bad dims for 'prob'");
|
||||||
|
_blob_sizes[_binding_prob] = d.c() * d.h() * d.w();
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
|
||||||
|
for (int i = 0; i < 2; i++) {
|
||||||
|
CHECK(cudaMalloc(&_gpu_buffers[i], _blob_sizes[i] * sizeof(float)));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtGooglenet::forward(float *imgs, float *prob)
|
||||||
|
{
|
||||||
|
CHECK(cudaMemcpyAsync(_gpu_buffers[_binding_data],
|
||||||
|
imgs,
|
||||||
|
_blob_sizes[_binding_data] * sizeof(float),
|
||||||
|
cudaMemcpyHostToDevice,
|
||||||
|
_stream));
|
||||||
|
_context->enqueue(1, _gpu_buffers, _stream, nullptr);
|
||||||
|
CHECK(cudaMemcpyAsync(prob,
|
||||||
|
_gpu_buffers[_binding_prob],
|
||||||
|
_blob_sizes[_binding_prob] * sizeof(float),
|
||||||
|
cudaMemcpyDeviceToHost,
|
||||||
|
_stream));
|
||||||
|
cudaStreamSynchronize(_stream);
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtGooglenet::destroy()
|
||||||
|
{
|
||||||
|
for (int i = 0; i < 2; i++) {
|
||||||
|
if (_gpu_buffers[i] != nullptr) {
|
||||||
|
CHECK(cudaFree(_gpu_buffers[i]));
|
||||||
|
_gpu_buffers[i] = nullptr;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
cudaStreamDestroy(_stream);
|
||||||
|
_context->destroy();
|
||||||
|
_engine->destroy();
|
||||||
|
_runtime->destroy();
|
||||||
|
}
|
||||||
|
|
||||||
|
//
|
||||||
|
// TrtMtcnnDet stuffs
|
||||||
|
//
|
||||||
|
|
||||||
|
TrtMtcnnDet::TrtMtcnnDet()
|
||||||
|
{
|
||||||
|
for (int i = 0; i < 4; i++) {
|
||||||
|
_gpu_buffers[i] = nullptr;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtMtcnnDet::_initEngine(std::string filePath, const char *dataName, const char *prob1Name, const char *boxesName, const char *marksName="unspecified")
|
||||||
|
{
|
||||||
|
_gieModelStream = new IHostMemoryFromFile(filePath);
|
||||||
|
_runtime = createInferRuntime(_gLogger);
|
||||||
|
my_assert(_runtime != nullptr, "_runtime is null");
|
||||||
|
_engine = _runtime->deserializeCudaEngine(
|
||||||
|
_gieModelStream->data(),
|
||||||
|
_gieModelStream->size(),
|
||||||
|
nullptr);
|
||||||
|
my_assert(_engine != nullptr, "_engine is null");
|
||||||
|
my_assert(_engine->getNbBindings() == _num_bindings, "wrong number of bindings");
|
||||||
|
_binding_data = _engine->getBindingIndex(dataName);
|
||||||
|
my_assert(_engine->bindingIsInput(_binding_data) == true, "bad type of binding 'data'");
|
||||||
|
_binding_prob1 = _engine->getBindingIndex(prob1Name);
|
||||||
|
my_assert(_engine->bindingIsInput(_binding_prob1) == false, "bad type of binding 'prob1'");
|
||||||
|
_binding_boxes = _engine->getBindingIndex(boxesName);
|
||||||
|
my_assert(_engine->bindingIsInput(_binding_boxes) == false, "bad type of binding 'boxes'");
|
||||||
|
if (_num_bindings == 4) {
|
||||||
|
_binding_marks = _engine->getBindingIndex(marksName);
|
||||||
|
my_assert(_engine->bindingIsInput(_binding_marks) == false, "bad type of binding 'marks'");
|
||||||
|
}
|
||||||
|
_context = _engine->createExecutionContext();
|
||||||
|
my_assert(_context != nullptr, "_context is null");
|
||||||
|
_gieModelStream->destroy();
|
||||||
|
CHECK(cudaStreamCreate(&_stream));
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtMtcnnDet::_setBlobSizes(int dataDims[3], int prob1Dims[3], int boxesDims[3])
|
||||||
|
{
|
||||||
|
#if NV_TENSORRT_MAJOR >= 4
|
||||||
|
Dims3 d;
|
||||||
|
d = static_cast<Dims3&&>(_engine->getBindingDimensions(_binding_data));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'data'");
|
||||||
|
my_assert(d.d[0] == dataDims[0] && d.d[1] == dataDims[1] && d.d[2] == dataDims[2], "bad dims for 'data'");
|
||||||
|
_blob_sizes[_binding_data] = d.d[0] * d.d[1] * d.d[2];
|
||||||
|
|
||||||
|
d = static_cast<Dims3&&>(_engine->getBindingDimensions(_binding_prob1));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'prob1'");
|
||||||
|
my_assert(d.d[0] == prob1Dims[0] && d.d[1] == prob1Dims[1] && d.d[2] == prob1Dims[2], "bad dims for 'prob1'");
|
||||||
|
_blob_sizes[_binding_prob1] = d.d[0] * d.d[1] * d.d[2];
|
||||||
|
|
||||||
|
d = static_cast<Dims3&&>(_engine->getBindingDimensions(_binding_boxes));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'boxes'");
|
||||||
|
my_assert(d.d[0] == boxesDims[0] && d.d[1] == boxesDims[1] && d.d[2] == boxesDims[2], "bad dims for 'boxes'");
|
||||||
|
_blob_sizes[_binding_boxes] = d.d[0] * d.d[1] * d.d[2];
|
||||||
|
#else // NV_TENSORRT_MAJOR < 4
|
||||||
|
DimsCHW d;
|
||||||
|
d = static_cast<DimsCHW&&>(_engine->getBindingDimensions(_binding_data));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'data'");
|
||||||
|
my_assert(d.c() == dataDims[0] && d.h() == dataDims[1] && d.w() == dataDims[2], "bad dims for 'data'");
|
||||||
|
_blob_sizes[_binding_data] = d.c() * d.h() * d.w();
|
||||||
|
|
||||||
|
d = static_cast<DimsCHW&&>(_engine->getBindingDimensions(_binding_prob1));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'prob1'");
|
||||||
|
my_assert(d.c() == prob1Dims[0] && d.h() == prob1Dims[1] && d.w() == prob1Dims[2], "bad dims for 'prob1'");
|
||||||
|
_blob_sizes[_binding_prob1] = d.c() * d.h() * d.w();
|
||||||
|
|
||||||
|
d = static_cast<DimsCHW&&>(_engine->getBindingDimensions(_binding_boxes));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'boxes'");
|
||||||
|
my_assert(d.c() == boxesDims[0] && d.h() == boxesDims[1] && d.w() == boxesDims[2], "bad dims for 'boxes'");
|
||||||
|
_blob_sizes[_binding_boxes] = d.c() * d.h() * d.w();
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtMtcnnDet::initDet1(std::string filePath, int dataDims[3], int prob1Dims[3], int boxesDims[3])
|
||||||
|
{
|
||||||
|
_num_bindings = 3;
|
||||||
|
_initEngine(filePath, "data", "prob1", "conv4-2");
|
||||||
|
_setBlobSizes(dataDims, prob1Dims, boxesDims);
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtMtcnnDet::initDet2(std::string filePath, int dataDims[3], int prob1Dims[3], int boxesDims[3])
|
||||||
|
{
|
||||||
|
_num_bindings = 3;
|
||||||
|
_initEngine(filePath, "data", "prob1", "conv5-2");
|
||||||
|
_setBlobSizes(dataDims, prob1Dims, boxesDims);
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtMtcnnDet::initDet3(std::string filePath, int dataDims[3], int prob1Dims[3], int boxesDims[3], int marksDims[3])
|
||||||
|
{
|
||||||
|
_num_bindings = 4;
|
||||||
|
_initEngine(filePath, "data", "prob1", "conv6-2", "conv6-3");
|
||||||
|
_setBlobSizes(dataDims, prob1Dims, boxesDims);
|
||||||
|
|
||||||
|
#if NV_TENSORRT_MAJOR >= 4
|
||||||
|
Dims3 d;
|
||||||
|
d = static_cast<Dims3&&>(_engine->getBindingDimensions(_binding_marks));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'marks'");
|
||||||
|
my_assert(d.d[0] == marksDims[0] && d.d[1] == marksDims[1] && d.d[2] == marksDims[2], "bad dims for 'marks'");
|
||||||
|
_blob_sizes[_binding_marks] = d.d[0] * d.d[1] * d.d[2];
|
||||||
|
#else // NV_TENSORRT_MAJOR < 4
|
||||||
|
DimsCHW d;
|
||||||
|
d = static_cast<DimsCHW&&>(_engine->getBindingDimensions(_binding_marks));
|
||||||
|
my_assert(d.nbDims == 3, "bad nbDims for 'marks'");
|
||||||
|
my_assert(d.c() == marksDims[0] && d.h() == marksDims[1] && d.w() == marksDims[2], "bad dims for 'marks'");
|
||||||
|
_blob_sizes[_binding_marks] = d.c() * d.h() * d.w();
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtMtcnnDet::setBatchSize(int value)
|
||||||
|
{
|
||||||
|
my_assert(value > 0 && value <= 1024, "bad batch_size");
|
||||||
|
if (value == _batchsize || _engine == nullptr)
|
||||||
|
return; // do nothing
|
||||||
|
_batchsize = value;
|
||||||
|
for (int i = 0; i < _num_bindings; i++) {
|
||||||
|
if (_gpu_buffers[i] != nullptr) {
|
||||||
|
CHECK(cudaFree(_gpu_buffers[i]));
|
||||||
|
_gpu_buffers[i] = nullptr;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
for (int i = 0; i < _num_bindings; i++) {
|
||||||
|
CHECK(cudaMalloc(&_gpu_buffers[i],
|
||||||
|
_batchsize * _blob_sizes[i] * sizeof(float)));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
int TrtMtcnnDet::getBatchSize()
|
||||||
|
{
|
||||||
|
return _batchsize;
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtMtcnnDet::forward(float *imgs, float *probs, float *boxes, float *marks=nullptr)
|
||||||
|
{
|
||||||
|
my_assert(_batchsize > 0, "_batchsize is not set");
|
||||||
|
CHECK(cudaMemcpyAsync(_gpu_buffers[_binding_data],
|
||||||
|
imgs,
|
||||||
|
_batchsize * _blob_sizes[_binding_data] * sizeof(float),
|
||||||
|
cudaMemcpyHostToDevice,
|
||||||
|
_stream));
|
||||||
|
_context->enqueue(_batchsize, _gpu_buffers, _stream, nullptr);
|
||||||
|
CHECK(cudaMemcpyAsync(probs,
|
||||||
|
_gpu_buffers[_binding_prob1],
|
||||||
|
_batchsize * _blob_sizes[_binding_prob1] * sizeof(float),
|
||||||
|
cudaMemcpyDeviceToHost,
|
||||||
|
_stream));
|
||||||
|
CHECK(cudaMemcpyAsync(boxes,
|
||||||
|
_gpu_buffers[_binding_boxes],
|
||||||
|
_batchsize * _blob_sizes[_binding_boxes] * sizeof(float),
|
||||||
|
cudaMemcpyDeviceToHost,
|
||||||
|
_stream));
|
||||||
|
if (_num_bindings == 4) {
|
||||||
|
my_assert(marks != nullptr, "pointer 'marks' is null");
|
||||||
|
CHECK(cudaMemcpyAsync(marks,
|
||||||
|
_gpu_buffers[_binding_marks],
|
||||||
|
_batchsize * _blob_sizes[_binding_marks] * sizeof(float),
|
||||||
|
cudaMemcpyDeviceToHost,
|
||||||
|
_stream));
|
||||||
|
}
|
||||||
|
cudaStreamSynchronize(_stream);
|
||||||
|
}
|
||||||
|
|
||||||
|
void TrtMtcnnDet::destroy()
|
||||||
|
{
|
||||||
|
for (int i = 0; i < _num_bindings; i++) {
|
||||||
|
if (_gpu_buffers[i] != nullptr) {
|
||||||
|
CHECK(cudaFree(_gpu_buffers[i]));
|
||||||
|
_gpu_buffers[i] = nullptr;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
cudaStreamDestroy(_stream);
|
||||||
|
_context->destroy();
|
||||||
|
_engine->destroy();
|
||||||
|
_runtime->destroy();
|
||||||
|
}
|
||||||
|
|
||||||
|
} // namespace trtnet
|
||||||
|
|
@ -0,0 +1,121 @@
|
||||||
|
// trtNet.h
|
||||||
|
#ifndef __TRTNET_H__
|
||||||
|
#define __TRTNET_H__
|
||||||
|
|
||||||
|
#include <cassert>
|
||||||
|
#include <iostream>
|
||||||
|
#include <cstring>
|
||||||
|
#include <sstream>
|
||||||
|
#include <fstream>
|
||||||
|
#include <cuda_runtime_api.h>
|
||||||
|
|
||||||
|
#include "NvInfer.h"
|
||||||
|
#include "NvCaffeParser.h"
|
||||||
|
|
||||||
|
using namespace nvinfer1;
|
||||||
|
using namespace nvcaffeparser1;
|
||||||
|
|
||||||
|
#if NV_TENSORRT_MAJOR >= 8
|
||||||
|
#define NOEXCEPT noexcept
|
||||||
|
#else // NV_TENSORRT_MAJOR < 8
|
||||||
|
#define NOEXCEPT
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
|
||||||
|
namespace trtnet {
|
||||||
|
|
||||||
|
class Logger : public ILogger
|
||||||
|
{
|
||||||
|
void log(Severity severity, const char *msg) NOEXCEPT override
|
||||||
|
{
|
||||||
|
if (severity != Severity::kINFO)
|
||||||
|
std::cout << msg << std::endl;
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|
||||||
|
class IHostMemoryFromFile : public IHostMemory
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
IHostMemoryFromFile(std::string filename) {
|
||||||
|
std::ifstream infile(filename, std::ifstream::binary |
|
||||||
|
std::ifstream::ate);
|
||||||
|
_s = infile.tellg();
|
||||||
|
infile.seekg(0, std::ios::beg);
|
||||||
|
_mem = malloc(_s);
|
||||||
|
infile.read(reinterpret_cast<char*>(_mem), _s);
|
||||||
|
}
|
||||||
|
#if NV_TENSORRT_MAJOR >= 6
|
||||||
|
void* data() const noexcept { return _mem; }
|
||||||
|
std::size_t size() const noexcept { return _s; }
|
||||||
|
DataType type () const noexcept { return DataType::kFLOAT; } // not used
|
||||||
|
void destroy() noexcept { free(_mem); }
|
||||||
|
#else // NV_TENSORRT_MAJOR < 6
|
||||||
|
void* data() const { return _mem; }
|
||||||
|
std::size_t size() const { return _s; }
|
||||||
|
DataType type () const { return DataType::kFLOAT; } // not used
|
||||||
|
void destroy() { free(_mem); }
|
||||||
|
#endif // NV_TENSORRT_MAJOR
|
||||||
|
private:
|
||||||
|
void *_mem{nullptr};
|
||||||
|
std::size_t _s;
|
||||||
|
};
|
||||||
|
|
||||||
|
class TrtGooglenet
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
TrtGooglenet();
|
||||||
|
// init from engine file
|
||||||
|
void initEngine(std::string filePath, int dataDims[3], int probDims[3]);
|
||||||
|
void forward(float *imgs, float *prob);
|
||||||
|
void destroy();
|
||||||
|
|
||||||
|
private:
|
||||||
|
Logger _gLogger;
|
||||||
|
IHostMemoryFromFile *_gieModelStream{nullptr};
|
||||||
|
IRuntime *_runtime;
|
||||||
|
ICudaEngine *_engine;
|
||||||
|
IExecutionContext *_context;
|
||||||
|
cudaStream_t _stream;
|
||||||
|
void *_gpu_buffers[2];
|
||||||
|
int _blob_sizes[2];
|
||||||
|
int _binding_data;
|
||||||
|
int _binding_prob;
|
||||||
|
|
||||||
|
void _initEngine(std::string filePath);
|
||||||
|
};
|
||||||
|
|
||||||
|
class TrtMtcnnDet
|
||||||
|
{
|
||||||
|
public:
|
||||||
|
TrtMtcnnDet();
|
||||||
|
// init from engine file
|
||||||
|
void initDet1(std::string filePath, int dataDims[3], int prob1Dims[3], int boxesDims[3]);
|
||||||
|
void initDet2(std::string filePath, int dataDims[3], int prob1Dims[3], int boxesDims[3]);
|
||||||
|
void initDet3(std::string filePath, int dataDims[3], int prob1Dims[3], int boxesDims[3], int marksDims[3]);
|
||||||
|
void setBatchSize(int value);
|
||||||
|
int getBatchSize();
|
||||||
|
void forward(float *imgs, float *probs, float *boxes, float *);
|
||||||
|
void destroy();
|
||||||
|
|
||||||
|
private:
|
||||||
|
Logger _gLogger;
|
||||||
|
IHostMemoryFromFile *_gieModelStream{nullptr};
|
||||||
|
IRuntime *_runtime;
|
||||||
|
ICudaEngine *_engine;
|
||||||
|
IExecutionContext *_context;
|
||||||
|
cudaStream_t _stream;
|
||||||
|
void *_gpu_buffers[4];
|
||||||
|
int _blob_sizes[4];
|
||||||
|
int _num_bindings = 0;
|
||||||
|
int _binding_data;
|
||||||
|
int _binding_prob1;
|
||||||
|
int _binding_boxes;
|
||||||
|
int _binding_marks;
|
||||||
|
int _batchsize = 0;
|
||||||
|
|
||||||
|
void _initEngine(std::string filePath, const char *dataName, const char *prob1Name, const char *boxesName, const char *marksName);
|
||||||
|
void _setBlobSizes(int dataDims[3], int prob1Dims[3], int boxesDims[3]);
|
||||||
|
};
|
||||||
|
|
||||||
|
} // namespace trtnet
|
||||||
|
|
||||||
|
#endif // __TRTNET_H__
|
||||||
|
|
@ -0,0 +1,128 @@
|
||||||
|
"""trt_googlenet.py
|
||||||
|
|
||||||
|
This script demonstrates how to do real-time image classification
|
||||||
|
(inferencing) with Cython wrapped TensorRT optimized googlenet engine.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import timeit
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
from utils.camera import add_camera_args, Camera
|
||||||
|
from utils.display import open_window, show_help_text, set_display
|
||||||
|
from pytrt import PyTrtGooglenet
|
||||||
|
|
||||||
|
|
||||||
|
PIXEL_MEANS = np.array([[[104., 117., 123.]]], dtype=np.float32)
|
||||||
|
DEPLOY_ENGINE = 'googlenet/deploy.engine'
|
||||||
|
ENGINE_SHAPE0 = (3, 224, 224)
|
||||||
|
ENGINE_SHAPE1 = (1000, 1, 1)
|
||||||
|
RESIZED_SHAPE = (224, 224)
|
||||||
|
|
||||||
|
WINDOW_NAME = 'TrtGooglenetDemo'
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = ('Capture and display live camera video, while doing '
|
||||||
|
'real-time image classification with TrtGooglenet '
|
||||||
|
'on Jetson Nano')
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser = add_camera_args(parser)
|
||||||
|
parser.add_argument('--crop', dest='crop_center',
|
||||||
|
help='crop center square of image for '
|
||||||
|
'inferencing [False]',
|
||||||
|
action='store_true')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def show_top_preds(img, top_probs, top_labels):
|
||||||
|
"""Show top predicted classes and softmax scores."""
|
||||||
|
x = 10
|
||||||
|
y = 40
|
||||||
|
for prob, label in zip(top_probs, top_labels):
|
||||||
|
pred = '{:.4f} {:20s}'.format(prob, label)
|
||||||
|
#cv2.putText(img, pred, (x+1, y), cv2.FONT_HERSHEY_PLAIN, 1.0,
|
||||||
|
# (32, 32, 32), 4, cv2.LINE_AA)
|
||||||
|
cv2.putText(img, pred, (x, y), cv2.FONT_HERSHEY_PLAIN, 1.0,
|
||||||
|
(0, 0, 240), 1, cv2.LINE_AA)
|
||||||
|
y += 20
|
||||||
|
|
||||||
|
|
||||||
|
def classify(img, net, labels, do_cropping):
|
||||||
|
"""Classify 1 image (crop)."""
|
||||||
|
crop = img
|
||||||
|
if do_cropping:
|
||||||
|
h, w, _ = img.shape
|
||||||
|
if h < w:
|
||||||
|
crop = img[:, ((w-h)//2):((w+h)//2), :]
|
||||||
|
else:
|
||||||
|
crop = img[((h-w)//2):((h+w)//2), :, :]
|
||||||
|
|
||||||
|
# preprocess the image crop
|
||||||
|
crop = cv2.resize(crop, RESIZED_SHAPE)
|
||||||
|
crop = crop.astype(np.float32) - PIXEL_MEANS
|
||||||
|
crop = crop.transpose((2, 0, 1)) # HWC -> CHW
|
||||||
|
|
||||||
|
# inference the (cropped) image
|
||||||
|
tic = timeit.default_timer()
|
||||||
|
out = net.forward(crop[None]) # add 1 dimension to 'crop' as batch
|
||||||
|
toc = timeit.default_timer()
|
||||||
|
print('{:.3f}s'.format(toc-tic))
|
||||||
|
|
||||||
|
# output top 3 predicted scores and class labels
|
||||||
|
out_prob = np.squeeze(out['prob'][0])
|
||||||
|
top_inds = out_prob.argsort()[::-1][:3]
|
||||||
|
return (out_prob[top_inds], labels[top_inds])
|
||||||
|
|
||||||
|
|
||||||
|
def loop_and_classify(cam, net, labels, do_cropping):
|
||||||
|
"""Continuously capture images from camera and do classification."""
|
||||||
|
show_help = True
|
||||||
|
full_scrn = False
|
||||||
|
help_text = '"Esc" to Quit, "H" for Help, "F" to Toggle Fullscreen'
|
||||||
|
while True:
|
||||||
|
if cv2.getWindowProperty(WINDOW_NAME, 0) < 0:
|
||||||
|
break
|
||||||
|
img = cam.read()
|
||||||
|
if img is None:
|
||||||
|
break
|
||||||
|
top_probs, top_labels = classify(img, net, labels, do_cropping)
|
||||||
|
show_top_preds(img, top_probs, top_labels)
|
||||||
|
if show_help:
|
||||||
|
show_help_text(img, help_text)
|
||||||
|
cv2.imshow(WINDOW_NAME, img)
|
||||||
|
key = cv2.waitKey(1)
|
||||||
|
if key == 27: # ESC key: quit program
|
||||||
|
break
|
||||||
|
elif key == ord('H') or key == ord('h'): # Toggle help message
|
||||||
|
show_help = not show_help
|
||||||
|
elif key == ord('F') or key == ord('f'): # Toggle fullscreen
|
||||||
|
full_scrn = not full_scrn
|
||||||
|
set_display(WINDOW_NAME, full_scrn)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
labels = np.loadtxt('googlenet/synset_words.txt', str, delimiter='\t')
|
||||||
|
cam = Camera(args)
|
||||||
|
if not cam.isOpened():
|
||||||
|
raise SystemExit('ERROR: failed to open camera!')
|
||||||
|
|
||||||
|
# initialize the tensorrt googlenet engine
|
||||||
|
net = PyTrtGooglenet(DEPLOY_ENGINE, ENGINE_SHAPE0, ENGINE_SHAPE1)
|
||||||
|
|
||||||
|
open_window(
|
||||||
|
WINDOW_NAME, 'Camera TensorRT GoogLeNet Demo',
|
||||||
|
cam.img_width, cam.img_height)
|
||||||
|
loop_and_classify(cam, net, labels, args.crop_center)
|
||||||
|
|
||||||
|
cam.release()
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,184 @@
|
||||||
|
"""trt_googlenet.py
|
||||||
|
|
||||||
|
This is the 'async' version of trt_googlenet.py implementation.
|
||||||
|
|
||||||
|
Refer to trt_ssd_async.py for description about the design and
|
||||||
|
synchronization between the main and child threads.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import sys
|
||||||
|
import time
|
||||||
|
import argparse
|
||||||
|
import threading
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
from utils.camera import add_camera_args, Camera
|
||||||
|
from utils.display import open_window, set_display, show_fps
|
||||||
|
from pytrt import PyTrtGooglenet
|
||||||
|
|
||||||
|
|
||||||
|
PIXEL_MEANS = np.array([[[104., 117., 123.]]], dtype=np.float32)
|
||||||
|
DEPLOY_ENGINE = 'googlenet/deploy.engine'
|
||||||
|
ENGINE_SHAPE0 = (3, 224, 224)
|
||||||
|
ENGINE_SHAPE1 = (1000, 1, 1)
|
||||||
|
RESIZED_SHAPE = (224, 224)
|
||||||
|
|
||||||
|
WINDOW_NAME = 'TrtGooglenetDemo'
|
||||||
|
MAIN_THREAD_TIMEOUT = 10.0 # 10 seconds
|
||||||
|
|
||||||
|
# 'shared' global variables
|
||||||
|
s_img, s_probs, s_labels = None, None, None
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = ('Capture and display live camera video, while doing '
|
||||||
|
'real-time image classification with TrtGooglenet '
|
||||||
|
'on Jetson Nano')
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser = add_camera_args(parser)
|
||||||
|
parser.add_argument('--crop', dest='crop_center',
|
||||||
|
help='crop center square of image for '
|
||||||
|
'inferencing [False]',
|
||||||
|
action='store_true')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def classify(img, net, labels, do_cropping):
|
||||||
|
"""Classify 1 image (crop)."""
|
||||||
|
crop = img
|
||||||
|
if do_cropping:
|
||||||
|
h, w, _ = img.shape
|
||||||
|
if h < w:
|
||||||
|
crop = img[:, ((w-h)//2):((w+h)//2), :]
|
||||||
|
else:
|
||||||
|
crop = img[((h-w)//2):((h+w)//2), :, :]
|
||||||
|
|
||||||
|
# preprocess the image crop
|
||||||
|
crop = cv2.resize(crop, RESIZED_SHAPE)
|
||||||
|
crop = crop.astype(np.float32) - PIXEL_MEANS
|
||||||
|
crop = crop.transpose((2, 0, 1)) # HWC -> CHW
|
||||||
|
|
||||||
|
# inference the (cropped) image
|
||||||
|
out = net.forward(crop[None]) # add 1 dimension to 'crop' as batch
|
||||||
|
|
||||||
|
# output top 3 predicted scores and class labels
|
||||||
|
out_prob = np.squeeze(out['prob'][0])
|
||||||
|
top_inds = out_prob.argsort()[::-1][:3]
|
||||||
|
return (out_prob[top_inds], labels[top_inds])
|
||||||
|
|
||||||
|
|
||||||
|
class TrtGooglenetThread(threading.Thread):
|
||||||
|
def __init__(self, condition, cam, labels, do_cropping):
|
||||||
|
"""__init__
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
condition: the condition variable used to notify main
|
||||||
|
thread about new frame and detection result
|
||||||
|
cam: the camera object for reading input image frames
|
||||||
|
labels: a numpy array of class labels
|
||||||
|
do_cropping: whether to do center-cropping of input image
|
||||||
|
"""
|
||||||
|
threading.Thread.__init__(self)
|
||||||
|
self.condition = condition
|
||||||
|
self.cam = cam
|
||||||
|
self.labels = labels
|
||||||
|
self.do_cropping = do_cropping
|
||||||
|
self.running = False
|
||||||
|
|
||||||
|
def run(self):
|
||||||
|
"""Run until 'running' flag is set to False by main thread."""
|
||||||
|
global s_img, s_probs, s_labels
|
||||||
|
|
||||||
|
print('TrtGooglenetThread: loading the TRT Googlenet engine...')
|
||||||
|
self.net = PyTrtGooglenet(DEPLOY_ENGINE, ENGINE_SHAPE0, ENGINE_SHAPE1)
|
||||||
|
print('TrtGooglenetThread: start running...')
|
||||||
|
self.running = True
|
||||||
|
while self.running:
|
||||||
|
img = self.cam.read()
|
||||||
|
if img is None:
|
||||||
|
break
|
||||||
|
top_probs, top_labels = classify(
|
||||||
|
img, self.net, self.labels, self.do_cropping)
|
||||||
|
with self.condition:
|
||||||
|
s_img, s_probs, s_labels = img, top_probs, top_labels
|
||||||
|
self.condition.notify()
|
||||||
|
del self.net
|
||||||
|
print('TrtGooglenetThread: stopped...')
|
||||||
|
|
||||||
|
def stop(self):
|
||||||
|
self.running = False
|
||||||
|
self.join()
|
||||||
|
|
||||||
|
|
||||||
|
def show_top_preds(img, top_probs, top_labels):
|
||||||
|
"""Show top predicted classes and softmax scores."""
|
||||||
|
x = 10
|
||||||
|
y = 40
|
||||||
|
for prob, label in zip(top_probs, top_labels):
|
||||||
|
pred = '{:.4f} {:20s}'.format(prob, label)
|
||||||
|
#cv2.putText(img, pred, (x+1, y), cv2.FONT_HERSHEY_PLAIN, 1.0,
|
||||||
|
# (32, 32, 32), 4, cv2.LINE_AA)
|
||||||
|
cv2.putText(img, pred, (x, y), cv2.FONT_HERSHEY_PLAIN, 1.0,
|
||||||
|
(0, 0, 240), 1, cv2.LINE_AA)
|
||||||
|
y += 20
|
||||||
|
|
||||||
|
|
||||||
|
def loop_and_display(condition):
|
||||||
|
"""Continuously capture images from camera and do classification."""
|
||||||
|
global s_img, s_probs, s_labels
|
||||||
|
|
||||||
|
full_scrn = False
|
||||||
|
fps = 0.0
|
||||||
|
tic = time.time()
|
||||||
|
while True:
|
||||||
|
if cv2.getWindowProperty(WINDOW_NAME, 0) < 0:
|
||||||
|
break
|
||||||
|
with condition:
|
||||||
|
if condition.wait(timeout=MAIN_THREAD_TIMEOUT):
|
||||||
|
img, top_probs, top_labels = s_img, s_probs, s_labels
|
||||||
|
else:
|
||||||
|
raise SystemExit('ERROR: timeout waiting for img from child')
|
||||||
|
show_top_preds(img, top_probs, top_labels)
|
||||||
|
img = show_fps(img, fps)
|
||||||
|
cv2.imshow(WINDOW_NAME, img)
|
||||||
|
toc = time.time()
|
||||||
|
curr_fps = 1.0 / (toc - tic)
|
||||||
|
# calculate an exponentially decaying average of fps number
|
||||||
|
fps = curr_fps if fps == 0.0 else (fps*0.95 + curr_fps*0.05)
|
||||||
|
tic = toc
|
||||||
|
key = cv2.waitKey(1)
|
||||||
|
if key == 27: # ESC key: quit program
|
||||||
|
break
|
||||||
|
elif key == ord('H') or key == ord('h'): # Toggle help message
|
||||||
|
show_help = not show_help
|
||||||
|
elif key == ord('F') or key == ord('f'): # Toggle fullscreen
|
||||||
|
full_scrn = not full_scrn
|
||||||
|
set_display(WINDOW_NAME, full_scrn)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
labels = np.loadtxt('googlenet/synset_words.txt', str, delimiter='\t')
|
||||||
|
cam = Camera(args)
|
||||||
|
if not cam.isOpened():
|
||||||
|
raise SystemExit('ERROR: failed to open camera!')
|
||||||
|
|
||||||
|
open_window(
|
||||||
|
WINDOW_NAME, 'Camera TensorRT GoogLeNet Demo',
|
||||||
|
cam.img_width, cam.img_height)
|
||||||
|
condition = threading.Condition()
|
||||||
|
trt_thread = TrtGooglenetThread(condition, cam, labels, args.crop_center)
|
||||||
|
trt_thread.start() # start the child thread
|
||||||
|
loop_and_display(condition)
|
||||||
|
trt_thread.stop() # stop the child thread
|
||||||
|
|
||||||
|
cam.release()
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,170 @@
|
||||||
|
"""trt_modnet.py
|
||||||
|
|
||||||
|
This script demonstrates how to do real-time "image matting" with
|
||||||
|
TensorRT optimized MODNet engine.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
import pycuda.autoinit # This is needed for initializing CUDA driver
|
||||||
|
|
||||||
|
from utils.camera import add_camera_args, Camera
|
||||||
|
from utils.writer import get_video_writer
|
||||||
|
from utils.background import Background
|
||||||
|
from utils.display import open_window, show_fps
|
||||||
|
from utils.display import FpsCalculator, ScreenToggler
|
||||||
|
from utils.modnet import TrtMODNet
|
||||||
|
|
||||||
|
|
||||||
|
WINDOW_NAME = 'TrtMODNetDemo'
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = ('Capture and display live camera video, while doing '
|
||||||
|
'real-time image matting with TensorRT optimized MODNet')
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser = add_camera_args(parser)
|
||||||
|
parser.add_argument(
|
||||||
|
'--background', type=str, default='',
|
||||||
|
help='background image or video file name [None]')
|
||||||
|
parser.add_argument(
|
||||||
|
'--create_video', type=str, default='',
|
||||||
|
help='create output video (either .ts or .mp4) [None]')
|
||||||
|
parser.add_argument(
|
||||||
|
'--demo_mode', action='store_true',
|
||||||
|
help='run the program in a special "demo mode" [False]')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
class BackgroundBlender():
|
||||||
|
"""BackgroundBlender
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
demo_mode: if True, do foreground/background blending in a
|
||||||
|
special "demo mode" which alternates among the
|
||||||
|
original, replaced and black backgrounds.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, demo_mode=False):
|
||||||
|
self.demo_mode = demo_mode
|
||||||
|
self.count = 0
|
||||||
|
|
||||||
|
def blend(self, img, bg, matte):
|
||||||
|
"""Blend foreground and background using the 'matte'.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
img: uint8 np.array of shape (H, W, 3), the foreground image
|
||||||
|
bg: uint8 np.array of shape (H, W, 3), the background image
|
||||||
|
matte: float32 np.array of shape (H, W), values between 0.0 and 1.0
|
||||||
|
"""
|
||||||
|
if self.demo_mode:
|
||||||
|
img, bg, matte = self._mod_for_demo(img, bg, matte)
|
||||||
|
return (img * matte[..., np.newaxis] +
|
||||||
|
bg * (1 - matte[..., np.newaxis])).astype(np.uint8)
|
||||||
|
|
||||||
|
def _mod_for_demo(self, img, bg, matte):
|
||||||
|
"""Modify img, bg and matte for "demo mode"
|
||||||
|
|
||||||
|
# Demo script (based on "count")
|
||||||
|
0~ 59: black background left to right
|
||||||
|
60~119: black background only
|
||||||
|
120~179: replaced background left to right
|
||||||
|
180~239: replaced background
|
||||||
|
240~299: original background left to right
|
||||||
|
300~359: original background
|
||||||
|
"""
|
||||||
|
img_h, img_w, _ = img.shape
|
||||||
|
if self.count < 120:
|
||||||
|
bg = np.zeros(bg.shape, dtype=np.uint8)
|
||||||
|
if self.count < 60:
|
||||||
|
offset = int(img_w * self.count / 59)
|
||||||
|
matte[:, offset:img_w] = 1.0
|
||||||
|
elif self.count < 240:
|
||||||
|
if self.count < 180:
|
||||||
|
offset = int(img_w * (self.count - 120) / 59)
|
||||||
|
bg[:, offset:img_w, :] = 0
|
||||||
|
else:
|
||||||
|
if self.count < 300:
|
||||||
|
offset = int(img_w * (self.count - 240) / 59)
|
||||||
|
matte[:, 0:offset] = 1.0
|
||||||
|
else:
|
||||||
|
matte[:, :] = 1.0
|
||||||
|
self.count = (self.count + 1) % 360
|
||||||
|
return img, bg, matte
|
||||||
|
|
||||||
|
|
||||||
|
class TrtMODNetRunner():
|
||||||
|
"""TrtMODNetRunner
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
modnet: TrtMODNet instance
|
||||||
|
cam: Camera object (for reading foreground images)
|
||||||
|
bggen: background generator (for reading background images)
|
||||||
|
blender: BackgroundBlender object
|
||||||
|
writer: VideoWriter object (for saving output video)
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, modnet, cam, bggen, blender, writer=None):
|
||||||
|
self.modnet = modnet
|
||||||
|
self.cam = cam
|
||||||
|
self.bggen = bggen
|
||||||
|
self.blender = blender
|
||||||
|
self.writer = writer
|
||||||
|
open_window(
|
||||||
|
WINDOW_NAME, 'TensorRT MODNet Demo', cam.img_width, cam.img_height)
|
||||||
|
|
||||||
|
def run(self):
|
||||||
|
"""Get img and bg, infer matte, blend and show img, then repeat."""
|
||||||
|
scrn_tog = ScreenToggler()
|
||||||
|
fps_calc = FpsCalculator()
|
||||||
|
while True:
|
||||||
|
if cv2.getWindowProperty(WINDOW_NAME, 0) < 0: break
|
||||||
|
img, bg = self.cam.read(), self.bggen.read()
|
||||||
|
if img is None: break
|
||||||
|
matte = self.modnet.infer(img)
|
||||||
|
matted_img = self.blender.blend(img, bg, matte)
|
||||||
|
fps = fps_calc.update()
|
||||||
|
matted_img = show_fps(matted_img, fps)
|
||||||
|
if self.writer: self.writer.write(matted_img)
|
||||||
|
cv2.imshow(WINDOW_NAME, matted_img)
|
||||||
|
key = cv2.waitKey(1)
|
||||||
|
if key == ord('F') or key == ord('f'): # Toggle fullscreen
|
||||||
|
scrn_tog.toggle()
|
||||||
|
elif key == 27: # ESC key: quit
|
||||||
|
break
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
|
||||||
|
cam = Camera(args)
|
||||||
|
if not cam.isOpened():
|
||||||
|
raise SystemExit('ERROR: failed to open camera!')
|
||||||
|
|
||||||
|
writer = None
|
||||||
|
if args.create_video:
|
||||||
|
writer = get_video_writer(
|
||||||
|
args.create_video, cam.img_width, cam.img_height)
|
||||||
|
|
||||||
|
modnet = TrtMODNet()
|
||||||
|
bggen = Background(args.background, cam.img_width, cam.img_height)
|
||||||
|
blender = BackgroundBlender(args.demo_mode)
|
||||||
|
|
||||||
|
runner = TrtMODNetRunner(modnet, cam, bggen, blender, writer)
|
||||||
|
runner.run()
|
||||||
|
|
||||||
|
if writer:
|
||||||
|
writer.release()
|
||||||
|
cam.release()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,89 @@
|
||||||
|
"""trt_mtcnn.py
|
||||||
|
|
||||||
|
This script demonstrates how to do real-time face detection with
|
||||||
|
Cython wrapped TensorRT optimized MTCNN engine.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import time
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
from utils.camera import add_camera_args, Camera
|
||||||
|
from utils.display import open_window, set_display, show_fps
|
||||||
|
from utils.mtcnn import TrtMtcnn
|
||||||
|
|
||||||
|
|
||||||
|
WINDOW_NAME = 'TrtMtcnnDemo'
|
||||||
|
BBOX_COLOR = (0, 255, 0) # green
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = ('Capture and display live camera video, while doing '
|
||||||
|
'real-time face detection with TrtMtcnn on Jetson '
|
||||||
|
'Nano')
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser = add_camera_args(parser)
|
||||||
|
parser.add_argument('--minsize', type=int, default=40,
|
||||||
|
help='minsize (in pixels) for detection [40]')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def show_faces(img, boxes, landmarks):
|
||||||
|
"""Draw bounding boxes and face landmarks on image."""
|
||||||
|
for bb, ll in zip(boxes, landmarks):
|
||||||
|
x1, y1, x2, y2 = int(bb[0]), int(bb[1]), int(bb[2]), int(bb[3])
|
||||||
|
cv2.rectangle(img, (x1, y1), (x2, y2), BBOX_COLOR, 2)
|
||||||
|
for j in range(5):
|
||||||
|
cv2.circle(img, (int(ll[j]), int(ll[j+5])), 2, BBOX_COLOR, 2)
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
def loop_and_detect(cam, mtcnn, minsize):
|
||||||
|
"""Continuously capture images from camera and do face detection."""
|
||||||
|
full_scrn = False
|
||||||
|
fps = 0.0
|
||||||
|
tic = time.time()
|
||||||
|
while True:
|
||||||
|
if cv2.getWindowProperty(WINDOW_NAME, 0) < 0:
|
||||||
|
break
|
||||||
|
img = cam.read()
|
||||||
|
if img is not None:
|
||||||
|
dets, landmarks = mtcnn.detect(img, minsize=minsize)
|
||||||
|
print('{} face(s) found'.format(len(dets)))
|
||||||
|
img = show_faces(img, dets, landmarks)
|
||||||
|
img = show_fps(img, fps)
|
||||||
|
cv2.imshow(WINDOW_NAME, img)
|
||||||
|
toc = time.time()
|
||||||
|
curr_fps = 1.0 / (toc - tic)
|
||||||
|
# calculate an exponentially decaying average of fps number
|
||||||
|
fps = curr_fps if fps == 0.0 else (fps*0.95 + curr_fps*0.05)
|
||||||
|
tic = toc
|
||||||
|
key = cv2.waitKey(1)
|
||||||
|
if key == 27: # ESC key: quit program
|
||||||
|
break
|
||||||
|
elif key == ord('F') or key == ord('f'): # Toggle fullscreen
|
||||||
|
full_scrn = not full_scrn
|
||||||
|
set_display(WINDOW_NAME, full_scrn)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
cam = Camera(args)
|
||||||
|
if not cam.isOpened():
|
||||||
|
raise SystemExit('ERROR: failed to open camera!')
|
||||||
|
|
||||||
|
mtcnn = TrtMtcnn()
|
||||||
|
|
||||||
|
open_window(
|
||||||
|
WINDOW_NAME, 'Camera TensorRT MTCNN Demo for Jetson Nano',
|
||||||
|
cam.img_width, cam.img_height)
|
||||||
|
loop_and_detect(cam, mtcnn, args.minsize)
|
||||||
|
|
||||||
|
cam.release()
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,102 @@
|
||||||
|
"""trt_ssd.py
|
||||||
|
|
||||||
|
This script demonstrates how to do real-time object detection with
|
||||||
|
TensorRT optimized Single-Shot Multibox Detector (SSD) engine.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import time
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import pycuda.autoinit # This is needed for initializing CUDA driver
|
||||||
|
|
||||||
|
from utils.ssd_classes import get_cls_dict
|
||||||
|
from utils.ssd import TrtSSD
|
||||||
|
from utils.camera import add_camera_args, Camera
|
||||||
|
from utils.display import open_window, set_display, show_fps
|
||||||
|
from utils.visualization import BBoxVisualization
|
||||||
|
|
||||||
|
|
||||||
|
WINDOW_NAME = 'TrtSsdDemo'
|
||||||
|
INPUT_HW = (300, 300)
|
||||||
|
SUPPORTED_MODELS = [
|
||||||
|
'ssd_mobilenet_v1_coco',
|
||||||
|
'ssd_mobilenet_v1_egohands',
|
||||||
|
'ssd_mobilenet_v2_coco',
|
||||||
|
'ssd_mobilenet_v2_egohands',
|
||||||
|
'ssd_inception_v2_coco',
|
||||||
|
'ssdlite_mobilenet_v2_coco',
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = ('Capture and display live camera video, while doing '
|
||||||
|
'real-time object detection with TensorRT optimized '
|
||||||
|
'SSD model on Jetson Nano')
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser = add_camera_args(parser)
|
||||||
|
parser.add_argument('-m', '--model', type=str,
|
||||||
|
default='ssd_mobilenet_v1_coco',
|
||||||
|
choices=SUPPORTED_MODELS)
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def loop_and_detect(cam, trt_ssd, conf_th, vis):
|
||||||
|
"""Continuously capture images from camera and do object detection.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
cam: the camera instance (video source).
|
||||||
|
trt_ssd: the TRT SSD object detector instance.
|
||||||
|
conf_th: confidence/score threshold for object detection.
|
||||||
|
vis: for visualization.
|
||||||
|
"""
|
||||||
|
full_scrn = False
|
||||||
|
fps = 0.0
|
||||||
|
tic = time.time()
|
||||||
|
while True:
|
||||||
|
if cv2.getWindowProperty(WINDOW_NAME, 0) < 0:
|
||||||
|
break
|
||||||
|
img = cam.read()
|
||||||
|
if img is None:
|
||||||
|
break
|
||||||
|
boxes, confs, clss = trt_ssd.detect(img, conf_th)
|
||||||
|
img = vis.draw_bboxes(img, boxes, confs, clss)
|
||||||
|
img = show_fps(img, fps)
|
||||||
|
cv2.imshow(WINDOW_NAME, img)
|
||||||
|
toc = time.time()
|
||||||
|
curr_fps = 1.0 / (toc - tic)
|
||||||
|
# calculate an exponentially decaying average of fps number
|
||||||
|
fps = curr_fps if fps == 0.0 else (fps*0.95 + curr_fps*0.05)
|
||||||
|
tic = toc
|
||||||
|
key = cv2.waitKey(1)
|
||||||
|
if key == 27: # ESC key: quit program
|
||||||
|
break
|
||||||
|
elif key == ord('F') or key == ord('f'): # Toggle fullscreen
|
||||||
|
full_scrn = not full_scrn
|
||||||
|
set_display(WINDOW_NAME, full_scrn)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
cam = Camera(args)
|
||||||
|
if not cam.isOpened():
|
||||||
|
raise SystemExit('ERROR: failed to open camera!')
|
||||||
|
|
||||||
|
cls_dict = get_cls_dict(args.model.split('_')[-1])
|
||||||
|
trt_ssd = TrtSSD(args.model, INPUT_HW)
|
||||||
|
|
||||||
|
open_window(
|
||||||
|
WINDOW_NAME, 'Camera TensorRT SSD Demo',
|
||||||
|
cam.img_width, cam.img_height)
|
||||||
|
vis = BBoxVisualization(cls_dict)
|
||||||
|
loop_and_detect(cam, trt_ssd, conf_th=0.3, vis=vis)
|
||||||
|
|
||||||
|
cam.release()
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,185 @@
|
||||||
|
"""trt_ssd_async.py
|
||||||
|
|
||||||
|
This is the 'async' version of trt_ssd.py implementation. It creates
|
||||||
|
1 dedicated child thread for fetching camera input and do inferencing
|
||||||
|
with the TensorRT optimized SSD model/engine, while using the main
|
||||||
|
thread for drawing detection results and displaying video. Ideally,
|
||||||
|
the 2 threads work in a pipeline fashion so overall throughput (FPS)
|
||||||
|
would be improved comparing to the non-async version.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import time
|
||||||
|
import argparse
|
||||||
|
import threading
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import pycuda.driver as cuda
|
||||||
|
|
||||||
|
from utils.ssd_classes import get_cls_dict
|
||||||
|
from utils.ssd import TrtSSD
|
||||||
|
from utils.camera import add_camera_args, Camera
|
||||||
|
from utils.display import open_window, set_display, show_fps
|
||||||
|
from utils.visualization import BBoxVisualization
|
||||||
|
|
||||||
|
|
||||||
|
WINDOW_NAME = 'TrtSsdDemoAsync'
|
||||||
|
MAIN_THREAD_TIMEOUT = 20.0 # 20 seconds
|
||||||
|
INPUT_HW = (300, 300)
|
||||||
|
SUPPORTED_MODELS = [
|
||||||
|
'ssd_mobilenet_v1_coco',
|
||||||
|
'ssd_mobilenet_v1_egohands',
|
||||||
|
'ssd_mobilenet_v2_coco',
|
||||||
|
'ssd_mobilenet_v2_egohands',
|
||||||
|
'ssd_inception_v2_coco',
|
||||||
|
'ssdlite_mobilenet_v2_coco',
|
||||||
|
]
|
||||||
|
|
||||||
|
# These global variables are 'shared' between the main and child
|
||||||
|
# threads. The child thread writes new frame and detection result
|
||||||
|
# into these variables, while the main thread reads from them.
|
||||||
|
s_img, s_boxes, s_confs, s_clss = None, None, None, None
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = ('Capture and display live camera video, while doing '
|
||||||
|
'real-time object detection with TensorRT optimized '
|
||||||
|
'SSD model on Jetson Nano')
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser = add_camera_args(parser)
|
||||||
|
parser.add_argument('-m', '--model', type=str,
|
||||||
|
default='ssd_mobilenet_v1_coco',
|
||||||
|
choices=SUPPORTED_MODELS)
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
class TrtThread(threading.Thread):
|
||||||
|
"""TrtThread
|
||||||
|
|
||||||
|
This implements the child thread which continues to read images
|
||||||
|
from cam (input) and to do TRT engine inferencing. The child
|
||||||
|
thread stores the input image and detection results into global
|
||||||
|
variables and uses a condition varaiable to inform main thread.
|
||||||
|
In other words, the TrtThread acts as the producer while the
|
||||||
|
main thread is the consumer.
|
||||||
|
"""
|
||||||
|
def __init__(self, condition, cam, model, conf_th):
|
||||||
|
"""__init__
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
condition: the condition variable used to notify main
|
||||||
|
thread about new frame and detection result
|
||||||
|
cam: the camera object for reading input image frames
|
||||||
|
model: a string, specifying the TRT SSD model
|
||||||
|
conf_th: confidence threshold for detection
|
||||||
|
"""
|
||||||
|
threading.Thread.__init__(self)
|
||||||
|
self.condition = condition
|
||||||
|
self.cam = cam
|
||||||
|
self.model = model
|
||||||
|
self.conf_th = conf_th
|
||||||
|
self.cuda_ctx = None # to be created when run
|
||||||
|
self.trt_ssd = None # to be created when run
|
||||||
|
self.running = False
|
||||||
|
|
||||||
|
def run(self):
|
||||||
|
"""Run until 'running' flag is set to False by main thread.
|
||||||
|
|
||||||
|
NOTE: CUDA context is created here, i.e. inside the thread
|
||||||
|
which calls CUDA kernels. In other words, creating CUDA
|
||||||
|
context in __init__() doesn't work.
|
||||||
|
"""
|
||||||
|
global s_img, s_boxes, s_confs, s_clss
|
||||||
|
|
||||||
|
print('TrtThread: loading the TRT SSD engine...')
|
||||||
|
self.cuda_ctx = cuda.Device(0).make_context() # GPU 0
|
||||||
|
self.trt_ssd = TrtSSD(self.model, INPUT_HW)
|
||||||
|
print('TrtThread: start running...')
|
||||||
|
self.running = True
|
||||||
|
while self.running:
|
||||||
|
img = self.cam.read()
|
||||||
|
if img is None:
|
||||||
|
break
|
||||||
|
boxes, confs, clss = self.trt_ssd.detect(img, self.conf_th)
|
||||||
|
with self.condition:
|
||||||
|
s_img, s_boxes, s_confs, s_clss = img, boxes, confs, clss
|
||||||
|
self.condition.notify()
|
||||||
|
del self.trt_ssd
|
||||||
|
self.cuda_ctx.pop()
|
||||||
|
del self.cuda_ctx
|
||||||
|
print('TrtThread: stopped...')
|
||||||
|
|
||||||
|
def stop(self):
|
||||||
|
self.running = False
|
||||||
|
self.join()
|
||||||
|
|
||||||
|
|
||||||
|
def loop_and_display(condition, vis):
|
||||||
|
"""Take detection results from the child thread and display.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
condition: the condition variable for synchronization with
|
||||||
|
the child thread.
|
||||||
|
vis: for visualization.
|
||||||
|
"""
|
||||||
|
global s_img, s_boxes, s_confs, s_clss
|
||||||
|
|
||||||
|
full_scrn = False
|
||||||
|
fps = 0.0
|
||||||
|
tic = time.time()
|
||||||
|
while True:
|
||||||
|
if cv2.getWindowProperty(WINDOW_NAME, 0) < 0:
|
||||||
|
break
|
||||||
|
with condition:
|
||||||
|
# Wait for the next frame and detection result. When
|
||||||
|
# getting the signal from the child thread, save the
|
||||||
|
# references to the frame and detection result for
|
||||||
|
# display.
|
||||||
|
if condition.wait(timeout=MAIN_THREAD_TIMEOUT):
|
||||||
|
img, boxes, confs, clss = s_img, s_boxes, s_confs, s_clss
|
||||||
|
else:
|
||||||
|
raise SystemExit('ERROR: timeout waiting for img from child')
|
||||||
|
img = vis.draw_bboxes(img, boxes, confs, clss)
|
||||||
|
img = show_fps(img, fps)
|
||||||
|
cv2.imshow(WINDOW_NAME, img)
|
||||||
|
toc = time.time()
|
||||||
|
curr_fps = 1.0 / (toc - tic)
|
||||||
|
# calculate an exponentially decaying average of fps number
|
||||||
|
fps = curr_fps if fps == 0.0 else (fps*0.95 + curr_fps*0.05)
|
||||||
|
tic = toc
|
||||||
|
key = cv2.waitKey(1)
|
||||||
|
if key == 27: # ESC key: quit program
|
||||||
|
break
|
||||||
|
elif key == ord('F') or key == ord('f'): # Toggle fullscreen
|
||||||
|
full_scrn = not full_scrn
|
||||||
|
set_display(WINDOW_NAME, full_scrn)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
cam = Camera(args)
|
||||||
|
if not cam.isOpened():
|
||||||
|
raise SystemExit('ERROR: failed to open camera!')
|
||||||
|
|
||||||
|
cuda.init() # init pycuda driver
|
||||||
|
|
||||||
|
cls_dict = get_cls_dict(args.model.split('_')[-1])
|
||||||
|
|
||||||
|
open_window(
|
||||||
|
WINDOW_NAME, 'Camera TensorRT SSD Demo',
|
||||||
|
cam.img_width, cam.img_height)
|
||||||
|
vis = BBoxVisualization(cls_dict)
|
||||||
|
condition = threading.Condition()
|
||||||
|
trt_thread = TrtThread(condition, cam, args.model, conf_th=0.3)
|
||||||
|
trt_thread.start() # start the child thread
|
||||||
|
loop_and_display(condition, vis)
|
||||||
|
trt_thread.stop() # stop the child thread
|
||||||
|
|
||||||
|
cam.release()
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,111 @@
|
||||||
|
"""trt_yolo.py
|
||||||
|
|
||||||
|
This script demonstrates how to do real-time object detection with
|
||||||
|
TensorRT optimized YOLO engine.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
import time
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import pycuda.autoinit # This is needed for initializing CUDA driver
|
||||||
|
|
||||||
|
from utils.yolo_classes import get_cls_dict
|
||||||
|
from utils.camera import add_camera_args, Camera
|
||||||
|
from utils.display import open_window, set_display, show_fps
|
||||||
|
from utils.visualization import BBoxVisualization
|
||||||
|
from utils.yolo_with_plugins import TrtYOLO
|
||||||
|
|
||||||
|
|
||||||
|
WINDOW_NAME = 'TrtYOLODemo'
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = ('Capture and display live camera video, while doing '
|
||||||
|
'real-time object detection with TensorRT optimized '
|
||||||
|
'YOLO model on Jetson')
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser = add_camera_args(parser)
|
||||||
|
parser.add_argument(
|
||||||
|
'-c', '--category_num', type=int, default=80,
|
||||||
|
help='number of object categories [80]')
|
||||||
|
parser.add_argument(
|
||||||
|
'-t', '--conf_thresh', type=float, default=0.3,
|
||||||
|
help='set the detection confidence threshold')
|
||||||
|
parser.add_argument(
|
||||||
|
'-m', '--model', type=str, required=True,
|
||||||
|
help=('[yolov3-tiny|yolov3|yolov3-spp|yolov4-tiny|yolov4|'
|
||||||
|
'yolov4-csp|yolov4x-mish|yolov4-p5]-[{dimension}], where '
|
||||||
|
'{dimension} could be either a single number (e.g. '
|
||||||
|
'288, 416, 608) or 2 numbers, WxH (e.g. 416x256)'))
|
||||||
|
parser.add_argument(
|
||||||
|
'-l', '--letter_box', action='store_true',
|
||||||
|
help='inference with letterboxed image [False]')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def loop_and_detect(cam, trt_yolo, conf_th, vis):
|
||||||
|
"""Continuously capture images from camera and do object detection.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
cam: the camera instance (video source).
|
||||||
|
trt_yolo: the TRT YOLO object detector instance.
|
||||||
|
conf_th: confidence/score threshold for object detection.
|
||||||
|
vis: for visualization.
|
||||||
|
"""
|
||||||
|
full_scrn = False
|
||||||
|
fps = 0.0
|
||||||
|
tic = time.time()
|
||||||
|
while True:
|
||||||
|
if cv2.getWindowProperty(WINDOW_NAME, 0) < 0:
|
||||||
|
break
|
||||||
|
img = cam.read()
|
||||||
|
if img is None:
|
||||||
|
break
|
||||||
|
boxes, confs, clss = trt_yolo.detect(img, conf_th)
|
||||||
|
img = vis.draw_bboxes(img, boxes, confs, clss)
|
||||||
|
img = show_fps(img, fps)
|
||||||
|
cv2.imshow(WINDOW_NAME, img)
|
||||||
|
toc = time.time()
|
||||||
|
curr_fps = 1.0 / (toc - tic)
|
||||||
|
# calculate an exponentially decaying average of fps number
|
||||||
|
fps = curr_fps if fps == 0.0 else (fps*0.95 + curr_fps*0.05)
|
||||||
|
tic = toc
|
||||||
|
key = cv2.waitKey(1)
|
||||||
|
if key == 27: # ESC key: quit program
|
||||||
|
break
|
||||||
|
elif key == ord('F') or key == ord('f'): # Toggle fullscreen
|
||||||
|
full_scrn = not full_scrn
|
||||||
|
set_display(WINDOW_NAME, full_scrn)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
if args.category_num <= 0:
|
||||||
|
raise SystemExit('ERROR: bad category_num (%d)!' % args.category_num)
|
||||||
|
if not os.path.isfile('yolo/%s.trt' % args.model):
|
||||||
|
raise SystemExit('ERROR: file (yolo/%s.trt) not found!' % args.model)
|
||||||
|
|
||||||
|
cam = Camera(args)
|
||||||
|
if not cam.isOpened():
|
||||||
|
raise SystemExit('ERROR: failed to open camera!')
|
||||||
|
|
||||||
|
cls_dict = get_cls_dict(args.category_num)
|
||||||
|
vis = BBoxVisualization(cls_dict)
|
||||||
|
trt_yolo = TrtYOLO(args.model, args.category_num, args.letter_box)
|
||||||
|
|
||||||
|
open_window(
|
||||||
|
WINDOW_NAME, 'Camera TensorRT YOLO Demo',
|
||||||
|
cam.img_width, cam.img_height)
|
||||||
|
loop_and_detect(cam, trt_yolo, args.conf_thresh, vis=vis)
|
||||||
|
|
||||||
|
cam.release()
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,97 @@
|
||||||
|
"""trt_yolo_cv.py
|
||||||
|
|
||||||
|
This script could be used to make object detection video with
|
||||||
|
TensorRT optimized YOLO engine.
|
||||||
|
|
||||||
|
"cv" means "create video"
|
||||||
|
made by BigJoon (ref. jkjung-avt)
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import pycuda.autoinit # This is needed for initializing CUDA driver
|
||||||
|
|
||||||
|
from utils.yolo_classes import get_cls_dict
|
||||||
|
from utils.visualization import BBoxVisualization
|
||||||
|
from utils.yolo_with_plugins import TrtYOLO
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = ('Run the TensorRT optimized object detecion model on an input '
|
||||||
|
'video and save BBoxed overlaid output as another video.')
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser.add_argument(
|
||||||
|
'-v', '--video', type=str, required=True,
|
||||||
|
help='input video file name')
|
||||||
|
parser.add_argument(
|
||||||
|
'-o', '--output', type=str, required=True,
|
||||||
|
help='output video file name')
|
||||||
|
parser.add_argument(
|
||||||
|
'-c', '--category_num', type=int, default=80,
|
||||||
|
help='number of object categories [80]')
|
||||||
|
parser.add_argument(
|
||||||
|
'-m', '--model', type=str, required=True,
|
||||||
|
help=('[yolov3-tiny|yolov3|yolov3-spp|yolov4-tiny|yolov4|'
|
||||||
|
'yolov4-csp|yolov4x-mish|yolov4-p5]-[{dimension}], where '
|
||||||
|
'{dimension} could be either a single number (e.g. '
|
||||||
|
'288, 416, 608) or 2 numbers, WxH (e.g. 416x256)'))
|
||||||
|
parser.add_argument(
|
||||||
|
'-l', '--letter_box', action='store_true',
|
||||||
|
help='inference with letterboxed image [False]')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def loop_and_detect(cap, trt_yolo, conf_th, vis, writer):
|
||||||
|
"""Continuously capture images from camera and do object detection.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
cap: the camera instance (video source).
|
||||||
|
trt_yolo: the TRT YOLO object detector instance.
|
||||||
|
conf_th: confidence/score threshold for object detection.
|
||||||
|
vis: for visualization.
|
||||||
|
writer: the VideoWriter object for the output video.
|
||||||
|
"""
|
||||||
|
|
||||||
|
while True:
|
||||||
|
ret, frame = cap.read()
|
||||||
|
if frame is None: break
|
||||||
|
boxes, confs, clss = trt_yolo.detect(frame, conf_th)
|
||||||
|
frame = vis.draw_bboxes(frame, boxes, confs, clss)
|
||||||
|
writer.write(frame)
|
||||||
|
print('.', end='', flush=True)
|
||||||
|
|
||||||
|
print('\nDone.')
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
if args.category_num <= 0:
|
||||||
|
raise SystemExit('ERROR: bad category_num (%d)!' % args.category_num)
|
||||||
|
if not os.path.isfile('yolo/%s.trt' % args.model):
|
||||||
|
raise SystemExit('ERROR: file (yolo/%s.trt) not found!' % args.model)
|
||||||
|
|
||||||
|
cap = cv2.VideoCapture(args.video)
|
||||||
|
if not cap.isOpened():
|
||||||
|
raise SystemExit('ERROR: failed to open the input video file!')
|
||||||
|
frame_width, frame_height = int(cap.get(3)), int(cap.get(4))
|
||||||
|
writer = cv2.VideoWriter(
|
||||||
|
args.output,
|
||||||
|
cv2.VideoWriter_fourcc(*'mp4v'), 30, (frame_width, frame_height))
|
||||||
|
|
||||||
|
cls_dict = get_cls_dict(args.category_num)
|
||||||
|
vis = BBoxVisualization(cls_dict)
|
||||||
|
trt_yolo = TrtYOLO(args.model, args.category_num, args.letter_box)
|
||||||
|
|
||||||
|
loop_and_detect(cap, trt_yolo, conf_th=0.3, vis=vis, writer=writer)
|
||||||
|
|
||||||
|
writer.release()
|
||||||
|
cap.release()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,101 @@
|
||||||
|
"""trt_yolo_mjpeg.py
|
||||||
|
|
||||||
|
MJPEG version of trt_yolo.py.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
import time
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import pycuda.autoinit # This is needed for initializing CUDA driver
|
||||||
|
|
||||||
|
from utils.yolo_classes import get_cls_dict
|
||||||
|
from utils.camera import add_camera_args, Camera
|
||||||
|
from utils.display import show_fps
|
||||||
|
from utils.visualization import BBoxVisualization
|
||||||
|
from utils.mjpeg import MjpegServer
|
||||||
|
from utils.yolo_with_plugins import TrtYOLO
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
"""Parse input arguments."""
|
||||||
|
desc = 'MJPEG version of trt_yolo'
|
||||||
|
parser = argparse.ArgumentParser(description=desc)
|
||||||
|
parser = add_camera_args(parser)
|
||||||
|
parser.add_argument(
|
||||||
|
'-c', '--category_num', type=int, default=80,
|
||||||
|
help='number of object categories [80]')
|
||||||
|
parser.add_argument(
|
||||||
|
'-m', '--model', type=str, required=True,
|
||||||
|
help=('[yolov3-tiny|yolov3|yolov3-spp|yolov4-tiny|yolov4|'
|
||||||
|
'yolov4-csp|yolov4x-mish|yolov4-p5]-[{dimension}], where '
|
||||||
|
'{dimension} could be either a single number (e.g. '
|
||||||
|
'288, 416, 608) or 2 numbers, WxH (e.g. 416x256)'))
|
||||||
|
parser.add_argument(
|
||||||
|
'-l', '--letter_box', action='store_true',
|
||||||
|
help='inference with letterboxed image [False]')
|
||||||
|
parser.add_argument(
|
||||||
|
'-p', '--mjpeg_port', type=int, default=8080,
|
||||||
|
help='MJPEG server port [8080]')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
def loop_and_detect(cam, trt_yolo, conf_th, vis, mjpeg_server):
|
||||||
|
"""Continuously capture images from camera and do object detection.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
cam: the camera instance (video source).
|
||||||
|
trt_yolo: the TRT YOLO object detector instance.
|
||||||
|
conf_th: confidence/score threshold for object detection.
|
||||||
|
vis: for visualization.
|
||||||
|
mjpeg_server
|
||||||
|
"""
|
||||||
|
fps = 0.0
|
||||||
|
tic = time.time()
|
||||||
|
while True:
|
||||||
|
img = cam.read()
|
||||||
|
if img is None:
|
||||||
|
break
|
||||||
|
boxes, confs, clss = trt_yolo.detect(img, conf_th)
|
||||||
|
img = vis.draw_bboxes(img, boxes, confs, clss)
|
||||||
|
img = show_fps(img, fps)
|
||||||
|
mjpeg_server.send_img(img)
|
||||||
|
toc = time.time()
|
||||||
|
curr_fps = 1.0 / (toc - tic)
|
||||||
|
# calculate an exponentially decaying average of fps number
|
||||||
|
fps = curr_fps if fps == 0.0 else (fps*0.95 + curr_fps*0.05)
|
||||||
|
tic = toc
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
if args.category_num <= 0:
|
||||||
|
raise SystemExit('ERROR: bad category_num (%d)!' % args.category_num)
|
||||||
|
if not os.path.isfile('yolo/%s.trt' % args.model):
|
||||||
|
raise SystemExit('ERROR: file (yolo/%s.trt) not found!' % args.model)
|
||||||
|
|
||||||
|
cam = Camera(args)
|
||||||
|
if not cam.isOpened():
|
||||||
|
raise SystemExit('ERROR: failed to open camera!')
|
||||||
|
|
||||||
|
cls_dict = get_cls_dict(args.category_num)
|
||||||
|
vis = BBoxVisualization(cls_dict)
|
||||||
|
trt_yolo = TrtYOLO(args.model, args.category_num, args.letter_box)
|
||||||
|
|
||||||
|
mjpeg_server = MjpegServer(port=args.mjpeg_port)
|
||||||
|
print('MJPEG server started...')
|
||||||
|
try:
|
||||||
|
loop_and_detect(cam, trt_yolo, conf_th=0.3, vis=vis,
|
||||||
|
mjpeg_server=mjpeg_server)
|
||||||
|
except Exception as e:
|
||||||
|
print(e)
|
||||||
|
finally:
|
||||||
|
mjpeg_server.shutdown()
|
||||||
|
cam.release()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,65 @@
|
||||||
|
"""background.py
|
||||||
|
|
||||||
|
This code implements the Background class for the TensorRT MODNet
|
||||||
|
demo. The Background class could generate background images from
|
||||||
|
either a still image, a video file or nothing (pure black bg).
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
|
||||||
|
class Background():
|
||||||
|
"""Backgrounf class which supports one of the following sources:
|
||||||
|
|
||||||
|
1. Image (jpg, png, etc.) file, repeating indefinitely
|
||||||
|
2. Video file, looping forever
|
||||||
|
3. None -> black background
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
src: if not spcified, use black background; else, src should be
|
||||||
|
a filename of an image (jpg/png) or video (mp4/ts)
|
||||||
|
width & height: width & height of the output background image
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, src, width, height, demo_mode=False):
|
||||||
|
self.src = src
|
||||||
|
self.width = width
|
||||||
|
self.height = height
|
||||||
|
self.demo_mode = demo_mode
|
||||||
|
if not src: # empty source: black background
|
||||||
|
self.is_video = False
|
||||||
|
self.bg_frame = np.zeros((height, width, 3), dtype=np.uint8)
|
||||||
|
elif not isinstance(src, str):
|
||||||
|
raise ValueError('bad src')
|
||||||
|
elif src.endswith('.jpg') or src.endswith('.png'):
|
||||||
|
self.is_video = False
|
||||||
|
self.bg_frame = cv2.resize(cv2.imread(src), (width, height))
|
||||||
|
assert self.bg_frame is not None and self.bg_frame.ndim == 3
|
||||||
|
elif src.endswith('.mp4') or src.endswith('.ts'):
|
||||||
|
self.is_video = True
|
||||||
|
self.cap = cv2.VideoCapture(src)
|
||||||
|
assert self.cap.isOpened()
|
||||||
|
else:
|
||||||
|
raise ValueError('unknown src')
|
||||||
|
|
||||||
|
def read(self):
|
||||||
|
"""Read a frame from the Background object."""
|
||||||
|
if self.is_video:
|
||||||
|
_, frame = self.cap.read()
|
||||||
|
if frame is None:
|
||||||
|
# assume end of video file has been reached, so loop around
|
||||||
|
self.cap.release()
|
||||||
|
self.cap = cv2.VideoCapture(self.src)
|
||||||
|
_, frame = self.cap.read()
|
||||||
|
return cv2.resize(frame, (self.width, self.height))
|
||||||
|
else:
|
||||||
|
return self.bg_frame.copy()
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
if self.is_video:
|
||||||
|
try:
|
||||||
|
self.cap.release()
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
|
@ -0,0 +1,273 @@
|
||||||
|
"""camera.py
|
||||||
|
|
||||||
|
This code implements the Camera class, which encapsulates code to
|
||||||
|
handle IP CAM, USB webcam or the Jetson onboard camera. In
|
||||||
|
addition, this Camera class is further extended to take a video
|
||||||
|
file or an image file as input.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import threading
|
||||||
|
import subprocess
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
|
||||||
|
# The following flag ise used to control whether to use a GStreamer
|
||||||
|
# pipeline to open USB webcam source. If set to False, we just open
|
||||||
|
# the webcam using cv2.VideoCapture(index) machinery. i.e. relying
|
||||||
|
# on cv2's built-in function to capture images from the webcam.
|
||||||
|
USB_GSTREAMER = True
|
||||||
|
|
||||||
|
|
||||||
|
def add_camera_args(parser):
|
||||||
|
"""Add parser augument for camera options."""
|
||||||
|
parser.add_argument('--image', type=str, default=None,
|
||||||
|
help='image file name, e.g. dog.jpg')
|
||||||
|
parser.add_argument('--video', type=str, default=None,
|
||||||
|
help='video file name, e.g. traffic.mp4')
|
||||||
|
parser.add_argument('--video_looping', action='store_true',
|
||||||
|
help='loop around the video file [False]')
|
||||||
|
parser.add_argument('--rtsp', type=str, default=None,
|
||||||
|
help=('RTSP H.264 stream, e.g. '
|
||||||
|
'rtsp://admin:123456@192.168.1.64:554'))
|
||||||
|
parser.add_argument('--rtsp_latency', type=int, default=200,
|
||||||
|
help='RTSP latency in ms [200]')
|
||||||
|
parser.add_argument('--usb', type=int, default=None,
|
||||||
|
help='USB webcam device id (/dev/video?) [None]')
|
||||||
|
parser.add_argument('--gstr', type=str, default=None,
|
||||||
|
help='GStreamer string [None]')
|
||||||
|
parser.add_argument('--onboard', type=int, default=None,
|
||||||
|
help='Jetson onboard camera [None]')
|
||||||
|
parser.add_argument('--copy_frame', action='store_true',
|
||||||
|
help=('copy video frame internally [False]'))
|
||||||
|
parser.add_argument('--do_resize', action='store_true',
|
||||||
|
help=('resize image/video [False]'))
|
||||||
|
parser.add_argument('--width', type=int, default=640,
|
||||||
|
help='image width [640]')
|
||||||
|
parser.add_argument('--height', type=int, default=480,
|
||||||
|
help='image height [480]')
|
||||||
|
return parser
|
||||||
|
|
||||||
|
|
||||||
|
def open_cam_rtsp(uri, width, height, latency):
|
||||||
|
"""Open an RTSP URI (IP CAM)."""
|
||||||
|
gst_elements = str(subprocess.check_output('gst-inspect-1.0'))
|
||||||
|
if 'omxh264dec' in gst_elements:
|
||||||
|
# Use hardware H.264 decoder on Jetson platforms
|
||||||
|
gst_str = ('rtspsrc location={} latency={} ! '
|
||||||
|
'rtph264depay ! h264parse ! omxh264dec ! '
|
||||||
|
'nvvidconv ! '
|
||||||
|
'video/x-raw, width=(int){}, height=(int){}, '
|
||||||
|
'format=(string)BGRx ! videoconvert ! '
|
||||||
|
'appsink').format(uri, latency, width, height)
|
||||||
|
elif 'avdec_h264' in gst_elements:
|
||||||
|
# Otherwise try to use the software decoder 'avdec_h264'
|
||||||
|
# NOTE: in case resizing images is necessary, try adding
|
||||||
|
# a 'videoscale' into the pipeline
|
||||||
|
gst_str = ('rtspsrc location={} latency={} ! '
|
||||||
|
'rtph264depay ! h264parse ! avdec_h264 ! '
|
||||||
|
'videoconvert ! appsink').format(uri, latency)
|
||||||
|
else:
|
||||||
|
raise RuntimeError('H.264 decoder not found!')
|
||||||
|
return cv2.VideoCapture(gst_str, cv2.CAP_GSTREAMER)
|
||||||
|
|
||||||
|
|
||||||
|
def open_cam_usb(dev, width, height):
|
||||||
|
"""Open a USB webcam."""
|
||||||
|
if USB_GSTREAMER:
|
||||||
|
gst_str = ('v4l2src device=/dev/video{} ! '
|
||||||
|
'video/x-raw, width=(int){}, height=(int){} ! '
|
||||||
|
'videoconvert ! appsink').format(dev, width, height)
|
||||||
|
return cv2.VideoCapture(gst_str, cv2.CAP_GSTREAMER)
|
||||||
|
else:
|
||||||
|
return cv2.VideoCapture(dev)
|
||||||
|
|
||||||
|
|
||||||
|
def open_cam_gstr(gstr, width, height):
|
||||||
|
"""Open camera using a GStreamer string.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
gstr = 'v4l2src device=/dev/video0 ! video/x-raw, width=(int){width}, height=(int){height} ! videoconvert ! appsink'
|
||||||
|
"""
|
||||||
|
gst_str = gstr.format(width=width, height=height)
|
||||||
|
return cv2.VideoCapture(gst_str, cv2.CAP_GSTREAMER)
|
||||||
|
|
||||||
|
|
||||||
|
def open_cam_onboard(width, height):
|
||||||
|
"""Open the Jetson onboard camera."""
|
||||||
|
gst_elements = str(subprocess.check_output('gst-inspect-1.0'))
|
||||||
|
if 'nvcamerasrc' in gst_elements:
|
||||||
|
# On versions of L4T prior to 28.1, you might need to add
|
||||||
|
# 'flip-method=2' into gst_str below.
|
||||||
|
gst_str = ('nvcamerasrc ! '
|
||||||
|
'video/x-raw(memory:NVMM), '
|
||||||
|
'width=(int)2592, height=(int)1458, '
|
||||||
|
'format=(string)I420, framerate=(fraction)30/1 ! '
|
||||||
|
'nvvidconv ! '
|
||||||
|
'video/x-raw, width=(int){}, height=(int){}, '
|
||||||
|
'format=(string)BGRx ! '
|
||||||
|
'videoconvert ! appsink').format(width, height)
|
||||||
|
elif 'nvarguscamerasrc' in gst_elements:
|
||||||
|
gst_str = ('nvarguscamerasrc ! '
|
||||||
|
'video/x-raw(memory:NVMM), '
|
||||||
|
'width=(int)1920, height=(int)1080, '
|
||||||
|
'format=(string)NV12, framerate=(fraction)30/1 ! '
|
||||||
|
'nvvidconv flip-method=2 ! '
|
||||||
|
'video/x-raw, width=(int){}, height=(int){}, '
|
||||||
|
'format=(string)BGRx ! '
|
||||||
|
'videoconvert ! appsink').format(width, height)
|
||||||
|
else:
|
||||||
|
raise RuntimeError('onboard camera source not found!')
|
||||||
|
return cv2.VideoCapture(gst_str, cv2.CAP_GSTREAMER)
|
||||||
|
|
||||||
|
|
||||||
|
def grab_img(cam):
|
||||||
|
"""This 'grab_img' function is designed to be run in the sub-thread.
|
||||||
|
Once started, this thread continues to grab a new image and put it
|
||||||
|
into the global 'img_handle', until 'thread_running' is set to False.
|
||||||
|
"""
|
||||||
|
while cam.thread_running:
|
||||||
|
_, cam.img_handle = cam.cap.read()
|
||||||
|
if cam.img_handle is None:
|
||||||
|
#logging.warning('Camera: cap.read() returns None...')
|
||||||
|
break
|
||||||
|
cam.thread_running = False
|
||||||
|
|
||||||
|
|
||||||
|
class Camera():
|
||||||
|
"""Camera class which supports reading images from theses video sources:
|
||||||
|
|
||||||
|
1. Image (jpg, png, etc.) file, repeating indefinitely
|
||||||
|
2. Video file
|
||||||
|
3. RTSP (IP CAM)
|
||||||
|
4. USB webcam
|
||||||
|
5. Jetson onboard camera
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, args):
|
||||||
|
self.args = args
|
||||||
|
self.is_opened = False
|
||||||
|
self.video_file = ''
|
||||||
|
self.video_looping = args.video_looping
|
||||||
|
self.thread_running = False
|
||||||
|
self.img_handle = None
|
||||||
|
self.copy_frame = args.copy_frame
|
||||||
|
self.do_resize = args.do_resize
|
||||||
|
self.img_width = args.width
|
||||||
|
self.img_height = args.height
|
||||||
|
self.cap = None
|
||||||
|
self.thread = None
|
||||||
|
self._open() # try to open the camera
|
||||||
|
|
||||||
|
def _open(self):
|
||||||
|
"""Open camera based on command line arguments."""
|
||||||
|
if self.cap is not None:
|
||||||
|
raise RuntimeError('camera is already opened!')
|
||||||
|
a = self.args
|
||||||
|
if a.image:
|
||||||
|
logging.info('Camera: using a image file %s' % a.image)
|
||||||
|
self.cap = 'image'
|
||||||
|
self.img_handle = cv2.imread(a.image)
|
||||||
|
if self.img_handle is not None:
|
||||||
|
if self.do_resize:
|
||||||
|
self.img_handle = cv2.resize(
|
||||||
|
self.img_handle, (a.width, a.height))
|
||||||
|
self.is_opened = True
|
||||||
|
self.img_height, self.img_width, _ = self.img_handle.shape
|
||||||
|
elif a.video:
|
||||||
|
logging.info('Camera: using a video file %s' % a.video)
|
||||||
|
self.video_file = a.video
|
||||||
|
self.cap = cv2.VideoCapture(a.video)
|
||||||
|
self._start()
|
||||||
|
elif a.rtsp:
|
||||||
|
logging.info('Camera: using RTSP stream %s' % a.rtsp)
|
||||||
|
self.cap = open_cam_rtsp(a.rtsp, a.width, a.height, a.rtsp_latency)
|
||||||
|
self._start()
|
||||||
|
elif a.usb is not None:
|
||||||
|
logging.info('Camera: using USB webcam /dev/video%d' % a.usb)
|
||||||
|
self.cap = open_cam_usb(a.usb, a.width, a.height)
|
||||||
|
self._start()
|
||||||
|
elif a.gstr is not None:
|
||||||
|
logging.info('Camera: using GStreamer string "%s"' % a.gstr)
|
||||||
|
self.cap = open_cam_gstr(a.gstr, a.width, a.height)
|
||||||
|
self._start()
|
||||||
|
elif a.onboard is not None:
|
||||||
|
logging.info('Camera: using Jetson onboard camera')
|
||||||
|
self.cap = open_cam_onboard(a.width, a.height)
|
||||||
|
self._start()
|
||||||
|
else:
|
||||||
|
raise RuntimeError('no camera type specified!')
|
||||||
|
|
||||||
|
def isOpened(self):
|
||||||
|
return self.is_opened
|
||||||
|
|
||||||
|
def _start(self):
|
||||||
|
if not self.cap.isOpened():
|
||||||
|
logging.warning('Camera: starting while cap is not opened!')
|
||||||
|
return
|
||||||
|
|
||||||
|
# Try to grab the 1st image and determine width and height
|
||||||
|
_, self.img_handle = self.cap.read()
|
||||||
|
if self.img_handle is None:
|
||||||
|
logging.warning('Camera: cap.read() returns no image!')
|
||||||
|
self.is_opened = False
|
||||||
|
return
|
||||||
|
|
||||||
|
self.is_opened = True
|
||||||
|
if self.video_file:
|
||||||
|
if not self.do_resize:
|
||||||
|
self.img_height, self.img_width, _ = self.img_handle.shape
|
||||||
|
else:
|
||||||
|
self.img_height, self.img_width, _ = self.img_handle.shape
|
||||||
|
# start the child thread if not using a video file source
|
||||||
|
# i.e. rtsp, usb or onboard
|
||||||
|
assert not self.thread_running
|
||||||
|
self.thread_running = True
|
||||||
|
self.thread = threading.Thread(target=grab_img, args=(self,))
|
||||||
|
self.thread.start()
|
||||||
|
|
||||||
|
def _stop(self):
|
||||||
|
if self.thread_running:
|
||||||
|
self.thread_running = False
|
||||||
|
#self.thread.join()
|
||||||
|
|
||||||
|
def read(self):
|
||||||
|
"""Read a frame from the camera object.
|
||||||
|
|
||||||
|
Returns None if the camera runs out of image or error.
|
||||||
|
"""
|
||||||
|
if not self.is_opened:
|
||||||
|
return None
|
||||||
|
|
||||||
|
if self.video_file:
|
||||||
|
_, img = self.cap.read()
|
||||||
|
if img is None:
|
||||||
|
logging.info('Camera: reaching end of video file')
|
||||||
|
if self.video_looping:
|
||||||
|
self.cap.release()
|
||||||
|
self.cap = cv2.VideoCapture(self.video_file)
|
||||||
|
_, img = self.cap.read()
|
||||||
|
if img is not None and self.do_resize:
|
||||||
|
img = cv2.resize(img, (self.img_width, self.img_height))
|
||||||
|
return img
|
||||||
|
elif self.cap == 'image':
|
||||||
|
return np.copy(self.img_handle)
|
||||||
|
else:
|
||||||
|
if self.copy_frame:
|
||||||
|
return self.img_handle.copy()
|
||||||
|
else:
|
||||||
|
return self.img_handle
|
||||||
|
|
||||||
|
def release(self):
|
||||||
|
self._stop()
|
||||||
|
try:
|
||||||
|
self.cap.release()
|
||||||
|
except:
|
||||||
|
pass
|
||||||
|
self.is_opened = False
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.release()
|
||||||
|
|
@ -0,0 +1,76 @@
|
||||||
|
"""display.py
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import time
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
|
||||||
|
def open_window(window_name, title, width=None, height=None):
|
||||||
|
"""Open the display window."""
|
||||||
|
cv2.namedWindow(window_name, cv2.WINDOW_NORMAL)
|
||||||
|
cv2.setWindowTitle(window_name, title)
|
||||||
|
if width and height:
|
||||||
|
cv2.resizeWindow(window_name, width, height)
|
||||||
|
|
||||||
|
|
||||||
|
def show_help_text(img, help_text):
|
||||||
|
"""Draw help text on image."""
|
||||||
|
cv2.putText(img, help_text, (11, 20), cv2.FONT_HERSHEY_PLAIN, 1.0,
|
||||||
|
(32, 32, 32), 4, cv2.LINE_AA)
|
||||||
|
cv2.putText(img, help_text, (10, 20), cv2.FONT_HERSHEY_PLAIN, 1.0,
|
||||||
|
(240, 240, 240), 1, cv2.LINE_AA)
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
def show_fps(img, fps):
|
||||||
|
"""Draw fps number at top-left corner of the image."""
|
||||||
|
font = cv2.FONT_HERSHEY_PLAIN
|
||||||
|
line = cv2.LINE_AA
|
||||||
|
fps_text = 'FPS: {:.2f}'.format(fps)
|
||||||
|
cv2.putText(img, fps_text, (11, 20), font, 1.0, (32, 32, 32), 4, line)
|
||||||
|
cv2.putText(img, fps_text, (10, 20), font, 1.0, (240, 240, 240), 1, line)
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
def set_display(window_name, full_scrn):
|
||||||
|
"""Set disply window to either full screen or normal."""
|
||||||
|
if full_scrn:
|
||||||
|
cv2.setWindowProperty(window_name, cv2.WND_PROP_FULLSCREEN,
|
||||||
|
cv2.WINDOW_FULLSCREEN)
|
||||||
|
else:
|
||||||
|
cv2.setWindowProperty(window_name, cv2.WND_PROP_FULLSCREEN,
|
||||||
|
cv2.WINDOW_NORMAL)
|
||||||
|
|
||||||
|
|
||||||
|
class FpsCalculator():
|
||||||
|
"""Helper class for calculating frames-per-second (FPS)."""
|
||||||
|
|
||||||
|
def __init__(self, decay_factor=0.95):
|
||||||
|
self.fps = 0.0
|
||||||
|
self.tic = time.time()
|
||||||
|
self.decay_factor = decay_factor
|
||||||
|
|
||||||
|
def update(self):
|
||||||
|
toc = time.time()
|
||||||
|
curr_fps = 1.0 / (toc - self.tic)
|
||||||
|
self.fps = curr_fps if self.fps == 0.0 else self.fps
|
||||||
|
self.fps = self.fps * self.decay_factor + \
|
||||||
|
curr_fps * (1 - self.decay_factor)
|
||||||
|
self.tic = toc
|
||||||
|
return self.fps
|
||||||
|
|
||||||
|
def reset(self):
|
||||||
|
self.fps = 0.0
|
||||||
|
|
||||||
|
|
||||||
|
class ScreenToggler():
|
||||||
|
"""Helper class for toggling between non-fullscreen and fullscreen."""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
self.full_scrn = False
|
||||||
|
|
||||||
|
def toggle(self):
|
||||||
|
self.full_scrn = not self.full_scrn
|
||||||
|
set_display(WINDOW_NAME, self.full_scrn)
|
||||||
|
|
@ -0,0 +1,107 @@
|
||||||
|
"""mjpeg.py
|
||||||
|
|
||||||
|
This module implements a simple MJPEG server which handles HTTP
|
||||||
|
requests from remote clients.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import time
|
||||||
|
import queue
|
||||||
|
import threading
|
||||||
|
import socket
|
||||||
|
from http.server import BaseHTTPRequestHandler, HTTPServer
|
||||||
|
from socketserver import ThreadingMixIn
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
|
||||||
|
# globals
|
||||||
|
_MJPEG_QUEUE = queue.Queue(maxsize=2)
|
||||||
|
_SLEEP_INTERVAL = 0.1 # update JPG roughly every 0.1 second
|
||||||
|
|
||||||
|
|
||||||
|
class MjpegHandler(BaseHTTPRequestHandler):
|
||||||
|
"""A simple MJPEG handler which publishes images."""
|
||||||
|
|
||||||
|
def _handle_mjpeg(self):
|
||||||
|
global _MJPEG_QUEUE
|
||||||
|
img = _MJPEG_QUEUE.get()
|
||||||
|
|
||||||
|
self.send_response(200)
|
||||||
|
self.send_header(
|
||||||
|
'Content-type',
|
||||||
|
'multipart/x-mixed-replace; boundary=--jpgboundary'
|
||||||
|
)
|
||||||
|
self.end_headers()
|
||||||
|
|
||||||
|
while True:
|
||||||
|
if not _MJPEG_QUEUE.empty():
|
||||||
|
img = _MJPEG_QUEUE.get()
|
||||||
|
ret, jpg = cv2.imencode('.jpg', img)
|
||||||
|
assert jpg is not None
|
||||||
|
self.wfile.write("--jpgboundary".encode("utf-8"))
|
||||||
|
self.send_header('Content-type', 'image/jpeg')
|
||||||
|
self.send_header('Content-length', str(jpg.size))
|
||||||
|
self.end_headers()
|
||||||
|
self.wfile.write(jpg.tostring())
|
||||||
|
time.sleep(_SLEEP_INTERVAL)
|
||||||
|
|
||||||
|
def _handle_error(self):
|
||||||
|
self.send_response(404)
|
||||||
|
self.send_header('Content-type', 'text/html')
|
||||||
|
self.end_headers()
|
||||||
|
self.wfile.write('<html><head></head><body>')
|
||||||
|
self.wfile.write('<h1>{0!s} not found</h1>'.format(self.path))
|
||||||
|
self.wfile.write('</body></html>')
|
||||||
|
|
||||||
|
def do_GET(self):
|
||||||
|
if self.path == '/mjpg' or self.path == '/':
|
||||||
|
self._handle_mjpeg()
|
||||||
|
else:
|
||||||
|
#print('ERROR: ', self.path)
|
||||||
|
self._handle_error()
|
||||||
|
|
||||||
|
def handle(self):
|
||||||
|
try:
|
||||||
|
super().handle()
|
||||||
|
except socket.error:
|
||||||
|
# ignore BrokenPipeError, which is caused by the client
|
||||||
|
# terminating the HTTP connection
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class ThreadedHTTPServer(ThreadingMixIn, HTTPServer):
|
||||||
|
"""Handle HTTP requests in a separate thread."""
|
||||||
|
# not used...
|
||||||
|
|
||||||
|
|
||||||
|
def run_server(server):
|
||||||
|
server.serve_forever() # this exits when server.shutdown() is called
|
||||||
|
server.socket.shutdown(socket.SHUT_RDWR)
|
||||||
|
server.socket.close()
|
||||||
|
|
||||||
|
|
||||||
|
class MjpegServer(object):
|
||||||
|
def __init__(self, init_img=None, ip='', port=8080):
|
||||||
|
# initialize the queue with a dummy image
|
||||||
|
global _MJPEG_QUEUE
|
||||||
|
init_img = init_img if init_img else \
|
||||||
|
np.ones((480, 640, 3), np.uint8) * 255 # all white
|
||||||
|
_MJPEG_QUEUE.put(init_img)
|
||||||
|
# create the HTTP server and run it from the child thread
|
||||||
|
self.server = HTTPServer((ip, port), MjpegHandler)
|
||||||
|
self.run_thread = threading.Thread(
|
||||||
|
target=run_server, args=(self.server,))
|
||||||
|
self.run_thread.start()
|
||||||
|
|
||||||
|
def send_img(self, img):
|
||||||
|
global _MJPEG_QUEUE
|
||||||
|
try:
|
||||||
|
_MJPEG_QUEUE.put(img, block=False)
|
||||||
|
except queue.Full:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def shutdown(self):
|
||||||
|
self.server.shutdown()
|
||||||
|
del self.server
|
||||||
|
|
@ -0,0 +1,164 @@
|
||||||
|
"""modnet.py
|
||||||
|
|
||||||
|
Implementation of TrtMODNet class.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
import tensorrt as trt
|
||||||
|
import pycuda.driver as cuda
|
||||||
|
|
||||||
|
|
||||||
|
# Code in this module is only for TensorRT 7+
|
||||||
|
if trt.__version__[0] < '7':
|
||||||
|
raise SystemExit('TensorRT version < 7')
|
||||||
|
|
||||||
|
|
||||||
|
def _preprocess_modnet(img, input_shape):
|
||||||
|
"""Preprocess an image before TRT MODNet inferencing.
|
||||||
|
|
||||||
|
# Args
|
||||||
|
img: int8 numpy array of shape (img_h, img_w, 3)
|
||||||
|
input_shape: a tuple of (H, W)
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
preprocessed img: float32 numpy array of shape (3, H, W)
|
||||||
|
"""
|
||||||
|
img = cv2.resize(img, (input_shape[1], input_shape[0]), cv2.INTER_AREA)
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
||||||
|
img = img.transpose((2, 0, 1)).astype(np.float32)
|
||||||
|
img = (img - 127.5) / 127.5
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
def _postprocess_modnet(output, output_shape):
|
||||||
|
"""Postprocess TRT MODNet output.
|
||||||
|
|
||||||
|
# Args
|
||||||
|
output: inferenced output by the TensorRT engine
|
||||||
|
output_shape: (H, W), e.g. (480, 640)
|
||||||
|
"""
|
||||||
|
matte = cv2.resize(
|
||||||
|
output, (output_shape[1], output_shape[0]),
|
||||||
|
interpolation=cv2.INTER_AREA)
|
||||||
|
return matte
|
||||||
|
|
||||||
|
|
||||||
|
class HostDeviceMem(object):
|
||||||
|
"""Simple helper data class that's a little nicer to use than a 2-tuple."""
|
||||||
|
def __init__(self, host_mem, device_mem):
|
||||||
|
self.host = host_mem
|
||||||
|
self.device = device_mem
|
||||||
|
|
||||||
|
def __str__(self):
|
||||||
|
return 'Host:\n' + str(self.host) + '\nDevice:\n' + str(self.device)
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return self.__str__()
|
||||||
|
|
||||||
|
|
||||||
|
def allocate_buffers(engine, context):
|
||||||
|
"""Allocates all host/device in/out buffers required for an engine."""
|
||||||
|
assert len(engine) == 2 and engine[0] == 'input' and engine[1] == 'output'
|
||||||
|
dtype = trt.nptype(engine.get_binding_dtype('input'))
|
||||||
|
assert trt.nptype(engine.get_binding_dtype('output')) == dtype
|
||||||
|
bindings = []
|
||||||
|
|
||||||
|
dims_in = context.get_binding_shape(0)
|
||||||
|
assert len(dims_in) == 4 and dims_in[0] == 1 and dims_in[1] == 3
|
||||||
|
hmem_in = cuda.pagelocked_empty(trt.volume(dims_in), dtype)
|
||||||
|
dmem_in = cuda.mem_alloc(hmem_in.nbytes)
|
||||||
|
bindings.append(int(dmem_in))
|
||||||
|
inputs = [HostDeviceMem(hmem_in, dmem_in)]
|
||||||
|
|
||||||
|
dims_out = context.get_binding_shape(1)
|
||||||
|
assert len(dims_out) == 4 and dims_out[0] == 1 and dims_out[1] == 1
|
||||||
|
assert dims_out[2] == dims_in[2] and dims_out[3] == dims_in[3]
|
||||||
|
hmem_out = cuda.pagelocked_empty(trt.volume(dims_out), dtype)
|
||||||
|
dmem_out = cuda.mem_alloc(hmem_out.nbytes)
|
||||||
|
bindings.append(int(dmem_out))
|
||||||
|
outputs = [HostDeviceMem(hmem_out, dmem_out)]
|
||||||
|
|
||||||
|
return bindings, inputs, outputs
|
||||||
|
|
||||||
|
|
||||||
|
def do_inference_v2(context, bindings, inputs, outputs, stream):
|
||||||
|
"""do_inference_v2 (for TensorRT 7.0+)
|
||||||
|
|
||||||
|
This function is generalized for multiple inputs/outputs for full
|
||||||
|
dimension networks. Inputs and outputs are expected to be lists
|
||||||
|
of HostDeviceMem objects.
|
||||||
|
"""
|
||||||
|
# Transfer input data to the GPU.
|
||||||
|
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
|
||||||
|
# Run inference.
|
||||||
|
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
|
||||||
|
# Transfer predictions back from the GPU.
|
||||||
|
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
|
||||||
|
# Synchronize the stream
|
||||||
|
stream.synchronize()
|
||||||
|
# Return only the host outputs.
|
||||||
|
return [out.host for out in outputs]
|
||||||
|
|
||||||
|
|
||||||
|
class TrtMODNet(object):
|
||||||
|
"""TrtMODNet class encapsulates things needed to run TRT MODNet."""
|
||||||
|
|
||||||
|
def __init__(self, cuda_ctx=None):
|
||||||
|
"""Initialize TensorRT plugins, engine and conetxt.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
cuda_ctx: PyCUDA context for inferencing (usually only needed
|
||||||
|
in multi-threaded cases
|
||||||
|
"""
|
||||||
|
self.cuda_ctx = cuda_ctx
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.push()
|
||||||
|
self.trt_logger = trt.Logger(trt.Logger.INFO)
|
||||||
|
self.engine = self._load_engine()
|
||||||
|
assert self.engine.get_binding_dtype('input') == trt.tensorrt.DataType.FLOAT
|
||||||
|
|
||||||
|
try:
|
||||||
|
self.context = self.engine.create_execution_context()
|
||||||
|
self.output_shape = self.context.get_binding_shape(1) # (1, 1, 480, 640)
|
||||||
|
self.stream = cuda.Stream()
|
||||||
|
self.bindings, self.inputs, self.outputs = allocate_buffers(
|
||||||
|
self.engine, self.context)
|
||||||
|
except Exception as e:
|
||||||
|
raise RuntimeError('fail to allocate CUDA resources') from e
|
||||||
|
finally:
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.pop()
|
||||||
|
dims = self.context.get_binding_shape(0) # 'input'
|
||||||
|
self.input_shape = (dims[2], dims[3])
|
||||||
|
|
||||||
|
def _load_engine(self):
|
||||||
|
if not trt.init_libnvinfer_plugins(self.trt_logger, ''):
|
||||||
|
raise RuntimeError('fail to init built-in plugins')
|
||||||
|
engine_path = 'modnet/modnet.engine'
|
||||||
|
with open(engine_path, 'rb') as f, trt.Runtime(self.trt_logger) as runtime:
|
||||||
|
return runtime.deserialize_cuda_engine(f.read())
|
||||||
|
|
||||||
|
def infer(self, img):
|
||||||
|
"""Infer an image.
|
||||||
|
|
||||||
|
The output is a matte (matting mask), which is a grayscale image
|
||||||
|
with either 0 or 255 pixels.
|
||||||
|
"""
|
||||||
|
img_resized = _preprocess_modnet(img, self.input_shape)
|
||||||
|
|
||||||
|
self.inputs[0].host = np.ascontiguousarray(img_resized)
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.push()
|
||||||
|
trt_outputs = do_inference_v2(
|
||||||
|
context=self.context,
|
||||||
|
bindings=self.bindings,
|
||||||
|
inputs=self.inputs,
|
||||||
|
outputs=self.outputs,
|
||||||
|
stream=self.stream)
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.pop()
|
||||||
|
|
||||||
|
output = trt_outputs[0].reshape(self.output_shape[-2:])
|
||||||
|
return _postprocess_modnet(output, img.shape[:2])
|
||||||
|
|
@ -0,0 +1,480 @@
|
||||||
|
"""mtcnn_trt.py
|
||||||
|
"""
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
import pytrt
|
||||||
|
|
||||||
|
|
||||||
|
PIXEL_MEAN = 127.5
|
||||||
|
PIXEL_SCALE = 0.0078125
|
||||||
|
|
||||||
|
|
||||||
|
def convert_to_1x1(boxes):
|
||||||
|
"""Convert detection boxes to 1:1 sizes
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
boxes: numpy array, shape (n,5), dtype=float32
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
boxes_1x1
|
||||||
|
"""
|
||||||
|
boxes_1x1 = boxes.copy()
|
||||||
|
hh = boxes[:, 3] - boxes[:, 1] + 1.
|
||||||
|
ww = boxes[:, 2] - boxes[:, 0] + 1.
|
||||||
|
mm = np.maximum(hh, ww)
|
||||||
|
boxes_1x1[:, 0] = boxes[:, 0] + ww * 0.5 - mm * 0.5
|
||||||
|
boxes_1x1[:, 1] = boxes[:, 1] + hh * 0.5 - mm * 0.5
|
||||||
|
boxes_1x1[:, 2] = boxes_1x1[:, 0] + mm - 1.
|
||||||
|
boxes_1x1[:, 3] = boxes_1x1[:, 1] + mm - 1.
|
||||||
|
boxes_1x1[:, 0:4] = np.fix(boxes_1x1[:, 0:4])
|
||||||
|
return boxes_1x1
|
||||||
|
|
||||||
|
|
||||||
|
def crop_img_with_padding(img, box, padding=0):
|
||||||
|
"""Crop a box from image, with out-of-boundary pixels padded
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
img: img as a numpy array, shape (H, W, 3)
|
||||||
|
box: numpy array, shape (5,) or (4,)
|
||||||
|
padding: integer value for padded pixels
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
cropped_im: cropped image as a numpy array, shape (H, W, 3)
|
||||||
|
"""
|
||||||
|
img_h, img_w, _ = img.shape
|
||||||
|
if box.shape[0] == 5:
|
||||||
|
cx1, cy1, cx2, cy2, _ = box.astype(int)
|
||||||
|
elif box.shape[0] == 4:
|
||||||
|
cx1, cy1, cx2, cy2 = box.astype(int)
|
||||||
|
else:
|
||||||
|
raise ValueError
|
||||||
|
cw = cx2 - cx1 + 1
|
||||||
|
ch = cy2 - cy1 + 1
|
||||||
|
cropped_im = np.zeros((ch, cw, 3), dtype=np.uint8) + padding
|
||||||
|
ex1 = max(0, -cx1) # ex/ey's are the destination coordinates
|
||||||
|
ey1 = max(0, -cy1)
|
||||||
|
ex2 = min(cw, img_w - cx1)
|
||||||
|
ey2 = min(ch, img_h - cy1)
|
||||||
|
fx1 = max(cx1, 0) # fx/fy's are the source coordinates
|
||||||
|
fy1 = max(cy1, 0)
|
||||||
|
fx2 = min(cx2+1, img_w)
|
||||||
|
fy2 = min(cy2+1, img_h)
|
||||||
|
cropped_im[ey1:ey2, ex1:ex2, :] = img[fy1:fy2, fx1:fx2, :]
|
||||||
|
return cropped_im
|
||||||
|
|
||||||
|
|
||||||
|
def nms(boxes, threshold, type='Union'):
|
||||||
|
"""Non-Maximum Supression
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
boxes: numpy array [:, 0:5] of [x1, y1, x2, y2, score]'s
|
||||||
|
threshold: confidence/score threshold, e.g. 0.5
|
||||||
|
type: 'Union' or 'Min'
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
A list of indices indicating the result of NMS
|
||||||
|
"""
|
||||||
|
if boxes.shape[0] == 0:
|
||||||
|
return []
|
||||||
|
xx1, yy1, xx2, yy2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
|
||||||
|
areas = np.multiply(xx2-xx1+1, yy2-yy1+1)
|
||||||
|
sorted_idx = boxes[:, 4].argsort()
|
||||||
|
|
||||||
|
pick = []
|
||||||
|
while len(sorted_idx) > 0:
|
||||||
|
# In each loop, pick the last box (highest score) and remove
|
||||||
|
# all other boxes with IoU over threshold
|
||||||
|
tx1 = np.maximum(xx1[sorted_idx[-1]], xx1[sorted_idx[0:-1]])
|
||||||
|
ty1 = np.maximum(yy1[sorted_idx[-1]], yy1[sorted_idx[0:-1]])
|
||||||
|
tx2 = np.minimum(xx2[sorted_idx[-1]], xx2[sorted_idx[0:-1]])
|
||||||
|
ty2 = np.minimum(yy2[sorted_idx[-1]], yy2[sorted_idx[0:-1]])
|
||||||
|
tw = np.maximum(0.0, tx2 - tx1 + 1)
|
||||||
|
th = np.maximum(0.0, ty2 - ty1 + 1)
|
||||||
|
inter = tw * th
|
||||||
|
if type == 'Min':
|
||||||
|
iou = inter / \
|
||||||
|
np.minimum(areas[sorted_idx[-1]], areas[sorted_idx[0:-1]])
|
||||||
|
else:
|
||||||
|
iou = inter / \
|
||||||
|
(areas[sorted_idx[-1]] + areas[sorted_idx[0:-1]] - inter)
|
||||||
|
pick.append(sorted_idx[-1])
|
||||||
|
sorted_idx = sorted_idx[np.where(iou <= threshold)[0]]
|
||||||
|
return pick
|
||||||
|
|
||||||
|
|
||||||
|
def generate_pnet_bboxes(conf, reg, scale, t):
|
||||||
|
"""
|
||||||
|
# Arguments
|
||||||
|
conf: softmax score (face or not) of each grid
|
||||||
|
reg: regression values of x1, y1, x2, y2 coordinates.
|
||||||
|
The values are normalized to grid width (12) and
|
||||||
|
height (12).
|
||||||
|
scale: scale-down factor with respect to original image
|
||||||
|
t: confidence threshold
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
A numpy array of bounding box coordinates and the
|
||||||
|
cooresponding scores: [[x1, y1, x2, y2, score], ...]
|
||||||
|
|
||||||
|
# Notes
|
||||||
|
Top left corner coordinates of each grid is (x*2, y*2),
|
||||||
|
or (x*2/scale, y*2/scale) in the original image.
|
||||||
|
Bottom right corner coordinates is (x*2+12-1, y*2+12-1),
|
||||||
|
or ((x*2+12-1)/scale, (y*2+12-1)/scale) in the original
|
||||||
|
image.
|
||||||
|
"""
|
||||||
|
conf = conf.T # swap H and W dimensions
|
||||||
|
dx1 = reg[0, :, :].T
|
||||||
|
dy1 = reg[1, :, :].T
|
||||||
|
dx2 = reg[2, :, :].T
|
||||||
|
dy2 = reg[3, :, :].T
|
||||||
|
(x, y) = np.where(conf >= t)
|
||||||
|
if len(x) == 0:
|
||||||
|
return np.zeros((0, 5), np.float32)
|
||||||
|
|
||||||
|
score = np.array(conf[x, y]).reshape(-1, 1) # Nx1
|
||||||
|
reg = np.array([dx1[x, y], dy1[x, y],
|
||||||
|
dx2[x, y], dy2[x, y]]).T * 12. # Nx4
|
||||||
|
topleft = np.array([x, y], dtype=np.float32).T * 2. # Nx2
|
||||||
|
bottomright = topleft + np.array([11., 11.], dtype=np.float32) # Nx2
|
||||||
|
boxes = (np.concatenate((topleft, bottomright), axis=1) + reg) / scale
|
||||||
|
boxes = np.concatenate((boxes, score), axis=1) # Nx5
|
||||||
|
# filter bboxes which are too small
|
||||||
|
#boxes = boxes[boxes[:, 2]-boxes[:, 0] >= 12., :]
|
||||||
|
#boxes = boxes[boxes[:, 3]-boxes[:, 1] >= 12., :]
|
||||||
|
return boxes
|
||||||
|
|
||||||
|
|
||||||
|
def generate_rnet_bboxes(conf, reg, pboxes, t):
|
||||||
|
"""
|
||||||
|
# Arguments
|
||||||
|
conf: softmax score (face or not) of each box
|
||||||
|
reg: regression values of x1, y1, x2, y2 coordinates.
|
||||||
|
The values are normalized to box width and height.
|
||||||
|
pboxes: input boxes to RNet
|
||||||
|
t: confidence threshold
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
boxes: a numpy array of box coordinates and cooresponding
|
||||||
|
scores: [[x1, y1, x2, y2, score], ...]
|
||||||
|
"""
|
||||||
|
boxes = pboxes.copy() # make a copy
|
||||||
|
assert boxes.shape[0] == conf.shape[0]
|
||||||
|
boxes[:, 4] = conf # update 'score' of all boxes
|
||||||
|
boxes = boxes[conf >= t, :]
|
||||||
|
reg = reg[conf >= t, :]
|
||||||
|
ww = (boxes[:, 2]-boxes[:, 0]+1).reshape(-1, 1) # x2 - x1 + 1
|
||||||
|
hh = (boxes[:, 3]-boxes[:, 1]+1).reshape(-1, 1) # y2 - y1 + 1
|
||||||
|
boxes[:, 0:4] += np.concatenate((ww, hh, ww, hh), axis=1) * reg
|
||||||
|
return boxes
|
||||||
|
|
||||||
|
|
||||||
|
def generate_onet_outputs(conf, reg_boxes, reg_marks, rboxes, t):
|
||||||
|
"""
|
||||||
|
# Arguments
|
||||||
|
conf: softmax score (face or not) of each box
|
||||||
|
reg_boxes: regression values of x1, y1, x2, y2
|
||||||
|
The values are normalized to box width and height.
|
||||||
|
reg_marks: regression values of the 5 facial landmark points
|
||||||
|
rboxes: input boxes to ONet (already converted to 2x1)
|
||||||
|
t: confidence threshold
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
boxes: a numpy array of box coordinates and cooresponding
|
||||||
|
scores: [[x1, y1, x2, y2,... , score], ...]
|
||||||
|
landmarks: a numpy array of facial landmark coordinates:
|
||||||
|
[[x1, x2, ..., x5, y1, y2, ..., y5], ...]
|
||||||
|
"""
|
||||||
|
boxes = rboxes.copy() # make a copy
|
||||||
|
assert boxes.shape[0] == conf.shape[0]
|
||||||
|
boxes[:, 4] = conf
|
||||||
|
boxes = boxes[conf >= t, :]
|
||||||
|
reg_boxes = reg_boxes[conf >= t, :]
|
||||||
|
reg_marks = reg_marks[conf >= t, :]
|
||||||
|
xx = boxes[:, 0].reshape(-1, 1)
|
||||||
|
yy = boxes[:, 1].reshape(-1, 1)
|
||||||
|
ww = (boxes[:, 2]-boxes[:, 0]).reshape(-1, 1)
|
||||||
|
hh = (boxes[:, 3]-boxes[:, 1]).reshape(-1, 1)
|
||||||
|
marks = np.concatenate((xx, xx, xx, xx, xx, yy, yy, yy, yy, yy), axis=1)
|
||||||
|
marks += np.concatenate((ww, ww, ww, ww, ww, hh, hh, hh, hh, hh), axis=1) * reg_marks
|
||||||
|
ww = ww + 1
|
||||||
|
hh = hh + 1
|
||||||
|
boxes[:, 0:4] += np.concatenate((ww, hh, ww, hh), axis=1) * reg_boxes
|
||||||
|
return boxes, marks
|
||||||
|
|
||||||
|
|
||||||
|
def clip_dets(dets, img_w, img_h):
|
||||||
|
"""Round and clip detection (x1, y1, ...) values.
|
||||||
|
|
||||||
|
Note we exclude the last value of 'dets' in computation since
|
||||||
|
it is 'conf'.
|
||||||
|
"""
|
||||||
|
dets[:, 0:-1] = np.fix(dets[:, 0:-1])
|
||||||
|
evens = np.arange(0, dets.shape[1]-1, 2)
|
||||||
|
odds = np.arange(1, dets.shape[1]-1, 2)
|
||||||
|
dets[:, evens] = np.clip(dets[:, evens], 0., float(img_w-1))
|
||||||
|
dets[:, odds] = np.clip(dets[:, odds], 0., float(img_h-1))
|
||||||
|
return dets
|
||||||
|
|
||||||
|
|
||||||
|
class TrtPNet(object):
|
||||||
|
"""TrtPNet
|
||||||
|
|
||||||
|
Refer to mtcnn/det1_relu.prototxt for calculation of input/output
|
||||||
|
dimmensions of TrtPNet, as well as input H offsets (for all scales).
|
||||||
|
The output H offsets are merely input offsets divided by stride (2).
|
||||||
|
"""
|
||||||
|
input_h_offsets = (0, 216, 370, 478, 556, 610, 648, 676, 696)
|
||||||
|
output_h_offsets = (0, 108, 185, 239, 278, 305, 324, 338, 348)
|
||||||
|
max_n_scales = 9
|
||||||
|
|
||||||
|
def __init__(self, engine):
|
||||||
|
"""__init__
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
engine: path to the TensorRT engine file
|
||||||
|
"""
|
||||||
|
self.trtnet = pytrt.PyTrtMtcnn(engine,
|
||||||
|
(3, 710, 384),
|
||||||
|
(2, 350, 187),
|
||||||
|
(4, 350, 187))
|
||||||
|
self.trtnet.set_batchsize(1)
|
||||||
|
|
||||||
|
def detect(self, img, minsize=40, factor=0.709, threshold=0.7):
|
||||||
|
"""Detect faces using PNet
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
img: input image as a RGB numpy array
|
||||||
|
threshold: confidence threshold
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
A numpy array of bounding box coordinates and the
|
||||||
|
cooresponding scores: [[x1, y1, x2, y2, score], ...]
|
||||||
|
"""
|
||||||
|
if minsize < 40:
|
||||||
|
raise ValueError("TrtPNet is currently designed with "
|
||||||
|
"'minsize' >= 40")
|
||||||
|
if factor > 0.709:
|
||||||
|
raise ValueError("TrtPNet is currently designed with "
|
||||||
|
"'factor' <= 0.709")
|
||||||
|
m = 12.0 / minsize
|
||||||
|
img_h, img_w, _ = img.shape
|
||||||
|
minl = min(img_h, img_w) * m
|
||||||
|
|
||||||
|
# create scale pyramid
|
||||||
|
scales = []
|
||||||
|
while minl >= 12:
|
||||||
|
scales.append(m)
|
||||||
|
m *= factor
|
||||||
|
minl *= factor
|
||||||
|
if len(scales) > self.max_n_scales: # probably won't happen...
|
||||||
|
raise ValueError('Too many scales, try increasing minsize '
|
||||||
|
'or decreasing factor.')
|
||||||
|
|
||||||
|
total_boxes = np.zeros((0, 5), dtype=np.float32)
|
||||||
|
img = (img.astype(np.float32) - PIXEL_MEAN) * PIXEL_SCALE
|
||||||
|
|
||||||
|
# stack all scales of the input image vertically into 1 big
|
||||||
|
# image, and only do inferencing once
|
||||||
|
im_data = np.zeros((1, 3, 710, 384), dtype=np.float32)
|
||||||
|
for i, scale in enumerate(scales):
|
||||||
|
h_offset = self.input_h_offsets[i]
|
||||||
|
h = int(img_h * scale)
|
||||||
|
w = int(img_w * scale)
|
||||||
|
im_data[0, :, h_offset:(h_offset+h), :w] = \
|
||||||
|
cv2.resize(img, (w, h)).transpose((2, 0, 1))
|
||||||
|
|
||||||
|
out = self.trtnet.forward(im_data)
|
||||||
|
|
||||||
|
# extract outputs of each scale from the big output blob
|
||||||
|
for i, scale in enumerate(scales):
|
||||||
|
h_offset = self.output_h_offsets[i]
|
||||||
|
h = (int(img_h * scale) - 12) // 2 + 1
|
||||||
|
w = (int(img_w * scale) - 12) // 2 + 1
|
||||||
|
pp = out['prob1'][0, 1, h_offset:(h_offset+h), :w]
|
||||||
|
cc = out['boxes'][0, :, h_offset:(h_offset+h), :w]
|
||||||
|
boxes = generate_pnet_bboxes(pp, cc, scale, threshold)
|
||||||
|
if boxes.shape[0] > 0:
|
||||||
|
pick = nms(boxes, 0.5, 'Union')
|
||||||
|
if len(pick) > 0:
|
||||||
|
boxes = boxes[pick, :]
|
||||||
|
if boxes.shape[0] > 0:
|
||||||
|
total_boxes = np.concatenate((total_boxes, boxes), axis=0)
|
||||||
|
|
||||||
|
if total_boxes.shape[0] == 0:
|
||||||
|
return total_boxes
|
||||||
|
pick = nms(total_boxes, 0.7, 'Union')
|
||||||
|
dets = clip_dets(total_boxes[pick, :], img_w, img_h)
|
||||||
|
return dets
|
||||||
|
|
||||||
|
def destroy(self):
|
||||||
|
self.trtnet.destroy()
|
||||||
|
self.trtnet = None
|
||||||
|
|
||||||
|
|
||||||
|
class TrtRNet(object):
|
||||||
|
"""TrtRNet
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
engine: path to the TensorRT engine (det2) file
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, engine):
|
||||||
|
self.trtnet = pytrt.PyTrtMtcnn(engine,
|
||||||
|
(3, 24, 24),
|
||||||
|
(2, 1, 1),
|
||||||
|
(4, 1, 1))
|
||||||
|
|
||||||
|
def detect(self, img, boxes, max_batch=256, threshold=0.6):
|
||||||
|
"""Detect faces using RNet
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
img: input image as a RGB numpy array
|
||||||
|
boxes: detection results by PNet, a numpy array [:, 0:5]
|
||||||
|
of [x1, y1, x2, y2, score]'s
|
||||||
|
max_batch: only process these many top boxes from PNet
|
||||||
|
threshold: confidence threshold
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
A numpy array of bounding box coordinates and the
|
||||||
|
cooresponding scores: [[x1, y1, x2, y2, score], ...]
|
||||||
|
"""
|
||||||
|
if max_batch > 256:
|
||||||
|
raise ValueError('Bad max_batch: %d' % max_batch)
|
||||||
|
boxes = boxes[:max_batch] # assuming boxes are sorted by score
|
||||||
|
if boxes.shape[0] == 0:
|
||||||
|
return boxes
|
||||||
|
img_h, img_w, _ = img.shape
|
||||||
|
boxes = convert_to_1x1(boxes)
|
||||||
|
crops = np.zeros((boxes.shape[0], 24, 24, 3), dtype=np.uint8)
|
||||||
|
for i, det in enumerate(boxes):
|
||||||
|
cropped_im = crop_img_with_padding(img, det)
|
||||||
|
# NOTE: H and W dimensions need to be transposed for RNet!
|
||||||
|
crops[i, ...] = cv2.transpose(cv2.resize(cropped_im, (24, 24)))
|
||||||
|
crops = crops.transpose((0, 3, 1, 2)) # NHWC -> NCHW
|
||||||
|
crops = (crops.astype(np.float32) - PIXEL_MEAN) * PIXEL_SCALE
|
||||||
|
|
||||||
|
self.trtnet.set_batchsize(crops.shape[0])
|
||||||
|
out = self.trtnet.forward(crops)
|
||||||
|
|
||||||
|
pp = out['prob1'][:, 1, 0, 0]
|
||||||
|
cc = out['boxes'][:, :, 0, 0]
|
||||||
|
boxes = generate_rnet_bboxes(pp, cc, boxes, threshold)
|
||||||
|
if boxes.shape[0] == 0:
|
||||||
|
return boxes
|
||||||
|
pick = nms(boxes, 0.7, 'Union')
|
||||||
|
dets = clip_dets(boxes[pick, :], img_w, img_h)
|
||||||
|
return dets
|
||||||
|
|
||||||
|
def destroy(self):
|
||||||
|
self.trtnet.destroy()
|
||||||
|
self.trtnet = None
|
||||||
|
|
||||||
|
|
||||||
|
class TrtONet(object):
|
||||||
|
"""TrtONet
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
engine: path to the TensorRT engine (det3) file
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, engine):
|
||||||
|
self.trtnet = pytrt.PyTrtMtcnn(engine,
|
||||||
|
(3, 48, 48),
|
||||||
|
(2, 1, 1),
|
||||||
|
(4, 1, 1),
|
||||||
|
(10, 1, 1))
|
||||||
|
|
||||||
|
def detect(self, img, boxes, max_batch=64, threshold=0.7):
|
||||||
|
"""Detect faces using ONet
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
img: input image as a RGB numpy array
|
||||||
|
boxes: detection results by RNet, a numpy array [:, 0:5]
|
||||||
|
of [x1, y1, x2, y2, score]'s
|
||||||
|
max_batch: only process these many top boxes from RNet
|
||||||
|
threshold: confidence threshold
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
dets: boxes and conf scores
|
||||||
|
landmarks
|
||||||
|
"""
|
||||||
|
if max_batch > 64:
|
||||||
|
raise ValueError('Bad max_batch: %d' % max_batch)
|
||||||
|
if boxes.shape[0] == 0:
|
||||||
|
return (np.zeros((0, 5), dtype=np.float32),
|
||||||
|
np.zeros((0, 10), dtype=np.float32))
|
||||||
|
boxes = boxes[:max_batch] # assuming boxes are sorted by score
|
||||||
|
img_h, img_w, _ = img.shape
|
||||||
|
boxes = convert_to_1x1(boxes)
|
||||||
|
crops = np.zeros((boxes.shape[0], 48, 48, 3), dtype=np.uint8)
|
||||||
|
for i, det in enumerate(boxes):
|
||||||
|
cropped_im = crop_img_with_padding(img, det)
|
||||||
|
# NOTE: H and W dimensions need to be transposed for RNet!
|
||||||
|
crops[i, ...] = cv2.transpose(cv2.resize(cropped_im, (48, 48)))
|
||||||
|
crops = crops.transpose((0, 3, 1, 2)) # NHWC -> NCHW
|
||||||
|
crops = (crops.astype(np.float32) - PIXEL_MEAN) * PIXEL_SCALE
|
||||||
|
|
||||||
|
self.trtnet.set_batchsize(crops.shape[0])
|
||||||
|
out = self.trtnet.forward(crops)
|
||||||
|
|
||||||
|
pp = out['prob1'][:, 1, 0, 0]
|
||||||
|
cc = out['boxes'][:, :, 0, 0]
|
||||||
|
mm = out['landmarks'][:, :, 0, 0]
|
||||||
|
boxes, landmarks = generate_onet_outputs(pp, cc, mm, boxes, threshold)
|
||||||
|
pick = nms(boxes, 0.7, 'Min')
|
||||||
|
return (clip_dets(boxes[pick, :], img_w, img_h),
|
||||||
|
np.fix(landmarks[pick, :]))
|
||||||
|
|
||||||
|
def destroy(self):
|
||||||
|
self.trtnet.destroy()
|
||||||
|
self.trtnet = None
|
||||||
|
|
||||||
|
|
||||||
|
class TrtMtcnn(object):
|
||||||
|
"""TrtMtcnn"""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
self.pnet = TrtPNet('mtcnn/det1.engine')
|
||||||
|
self.rnet = TrtRNet('mtcnn/det2.engine')
|
||||||
|
self.onet = TrtONet('mtcnn/det3.engine')
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.onet.destroy()
|
||||||
|
self.rnet.destroy()
|
||||||
|
self.pnet.destroy()
|
||||||
|
|
||||||
|
def _detect_1280x720(self, img, minsize):
|
||||||
|
"""_detec_1280x720()
|
||||||
|
|
||||||
|
Assuming 'img' has been resized to less than 1280x720.
|
||||||
|
"""
|
||||||
|
# MTCNN model was trained with 'MATLAB' image so its channel
|
||||||
|
# order is RGB instead of BGR.
|
||||||
|
img = img[:, :, ::-1] # BGR -> RGB
|
||||||
|
dets = self.pnet.detect(img, minsize=minsize)
|
||||||
|
dets = self.rnet.detect(img, dets)
|
||||||
|
dets, landmarks = self.onet.detect(img, dets)
|
||||||
|
return dets, landmarks
|
||||||
|
|
||||||
|
def detect(self, img, minsize=40):
|
||||||
|
"""detect()
|
||||||
|
|
||||||
|
This function handles rescaling of the input image if it's
|
||||||
|
larger than 1280x720.
|
||||||
|
"""
|
||||||
|
if img is None:
|
||||||
|
raise ValueError
|
||||||
|
img_h, img_w, _ = img.shape
|
||||||
|
scale = min(720. / img_h, 1280. / img_w)
|
||||||
|
if scale < 1.0:
|
||||||
|
new_h = int(np.ceil(img_h * scale))
|
||||||
|
new_w = int(np.ceil(img_w * scale))
|
||||||
|
img = cv2.resize(img, (new_w, new_h))
|
||||||
|
minsize = max(int(np.ceil(minsize * scale)), 40)
|
||||||
|
dets, landmarks = self._detect_1280x720(img, minsize)
|
||||||
|
if scale < 1.0:
|
||||||
|
dets[:, :-1] = np.fix(dets[:, :-1] / scale)
|
||||||
|
landmarks = np.fix(landmarks / scale)
|
||||||
|
return dets, landmarks
|
||||||
|
|
@ -0,0 +1,125 @@
|
||||||
|
"""ssd.py
|
||||||
|
|
||||||
|
This module implements the TrtSSD class.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import ctypes
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
import tensorrt as trt
|
||||||
|
import pycuda.driver as cuda
|
||||||
|
|
||||||
|
|
||||||
|
def _preprocess_trt(img, shape=(300, 300)):
|
||||||
|
"""Preprocess an image before TRT SSD inferencing."""
|
||||||
|
img = cv2.resize(img, shape)
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
||||||
|
img = img.transpose((2, 0, 1)).astype(np.float32)
|
||||||
|
img *= (2.0/255.0)
|
||||||
|
img -= 1.0
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
def _postprocess_trt(img, output, conf_th, output_layout=7):
|
||||||
|
"""Postprocess TRT SSD output."""
|
||||||
|
img_h, img_w, _ = img.shape
|
||||||
|
boxes, confs, clss = [], [], []
|
||||||
|
for prefix in range(0, len(output), output_layout):
|
||||||
|
#index = int(output[prefix+0])
|
||||||
|
conf = float(output[prefix+2])
|
||||||
|
if conf < conf_th:
|
||||||
|
continue
|
||||||
|
x1 = int(output[prefix+3] * img_w)
|
||||||
|
y1 = int(output[prefix+4] * img_h)
|
||||||
|
x2 = int(output[prefix+5] * img_w)
|
||||||
|
y2 = int(output[prefix+6] * img_h)
|
||||||
|
cls = int(output[prefix+1])
|
||||||
|
boxes.append((x1, y1, x2, y2))
|
||||||
|
confs.append(conf)
|
||||||
|
clss.append(cls)
|
||||||
|
return boxes, confs, clss
|
||||||
|
|
||||||
|
|
||||||
|
class TrtSSD(object):
|
||||||
|
"""TrtSSD class encapsulates things needed to run TRT SSD."""
|
||||||
|
|
||||||
|
def _load_plugins(self):
|
||||||
|
if trt.__version__[0] < '7':
|
||||||
|
ctypes.CDLL("ssd/libflattenconcat.so")
|
||||||
|
trt.init_libnvinfer_plugins(self.trt_logger, '')
|
||||||
|
|
||||||
|
def _load_engine(self):
|
||||||
|
TRTbin = 'ssd/TRT_%s.bin' % self.model
|
||||||
|
with open(TRTbin, 'rb') as f, trt.Runtime(self.trt_logger) as runtime:
|
||||||
|
return runtime.deserialize_cuda_engine(f.read())
|
||||||
|
|
||||||
|
def _allocate_buffers(self):
|
||||||
|
host_inputs, host_outputs, cuda_inputs, cuda_outputs, bindings = \
|
||||||
|
[], [], [], [], []
|
||||||
|
for binding in self.engine:
|
||||||
|
size = trt.volume(self.engine.get_binding_shape(binding)) * \
|
||||||
|
self.engine.max_batch_size
|
||||||
|
host_mem = cuda.pagelocked_empty(size, np.float32)
|
||||||
|
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
|
||||||
|
bindings.append(int(cuda_mem))
|
||||||
|
if self.engine.binding_is_input(binding):
|
||||||
|
host_inputs.append(host_mem)
|
||||||
|
cuda_inputs.append(cuda_mem)
|
||||||
|
else:
|
||||||
|
host_outputs.append(host_mem)
|
||||||
|
cuda_outputs.append(cuda_mem)
|
||||||
|
return host_inputs, host_outputs, cuda_inputs, cuda_outputs, bindings
|
||||||
|
|
||||||
|
def __init__(self, model, input_shape, cuda_ctx=None):
|
||||||
|
"""Initialize TensorRT plugins, engine and conetxt."""
|
||||||
|
self.model = model
|
||||||
|
self.input_shape = input_shape
|
||||||
|
self.cuda_ctx = cuda_ctx
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.push()
|
||||||
|
|
||||||
|
self.trt_logger = trt.Logger(trt.Logger.INFO)
|
||||||
|
self._load_plugins()
|
||||||
|
self.engine = self._load_engine()
|
||||||
|
|
||||||
|
try:
|
||||||
|
self.context = self.engine.create_execution_context()
|
||||||
|
self.stream = cuda.Stream()
|
||||||
|
self.host_inputs, self.host_outputs, self.cuda_inputs, self.cuda_outputs, self.bindings = self._allocate_buffers()
|
||||||
|
except Exception as e:
|
||||||
|
raise RuntimeError('fail to allocate CUDA resources') from e
|
||||||
|
finally:
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.pop()
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
"""Free CUDA memories and context."""
|
||||||
|
del self.cuda_outputs
|
||||||
|
del self.cuda_inputs
|
||||||
|
del self.stream
|
||||||
|
|
||||||
|
def detect(self, img, conf_th=0.3):
|
||||||
|
"""Detect objects in the input image."""
|
||||||
|
img_resized = _preprocess_trt(img, self.input_shape)
|
||||||
|
np.copyto(self.host_inputs[0], img_resized.ravel())
|
||||||
|
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.push()
|
||||||
|
cuda.memcpy_htod_async(
|
||||||
|
self.cuda_inputs[0], self.host_inputs[0], self.stream)
|
||||||
|
self.context.execute_async(
|
||||||
|
batch_size=1,
|
||||||
|
bindings=self.bindings,
|
||||||
|
stream_handle=self.stream.handle)
|
||||||
|
cuda.memcpy_dtoh_async(
|
||||||
|
self.host_outputs[1], self.cuda_outputs[1], self.stream)
|
||||||
|
cuda.memcpy_dtoh_async(
|
||||||
|
self.host_outputs[0], self.cuda_outputs[0], self.stream)
|
||||||
|
self.stream.synchronize()
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.pop()
|
||||||
|
|
||||||
|
output = self.host_outputs[0]
|
||||||
|
return _postprocess_trt(img, output, conf_th)
|
||||||
|
|
@ -0,0 +1,115 @@
|
||||||
|
"""ssd_classes.py
|
||||||
|
|
||||||
|
This file was modified from:
|
||||||
|
http://github.com/AastaNV/TRT_object_detection/blob/master/coco.py
|
||||||
|
"""
|
||||||
|
|
||||||
|
COCO_CLASSES_LIST = [
|
||||||
|
'background', # was 'unlabeled'
|
||||||
|
'person',
|
||||||
|
'bicycle',
|
||||||
|
'car',
|
||||||
|
'motorcycle',
|
||||||
|
'airplane',
|
||||||
|
'bus',
|
||||||
|
'train',
|
||||||
|
'truck',
|
||||||
|
'boat',
|
||||||
|
'traffic light',
|
||||||
|
'fire hydrant',
|
||||||
|
'street sign',
|
||||||
|
'stop sign',
|
||||||
|
'parking meter',
|
||||||
|
'bench',
|
||||||
|
'bird',
|
||||||
|
'cat',
|
||||||
|
'dog',
|
||||||
|
'horse',
|
||||||
|
'sheep',
|
||||||
|
'cow',
|
||||||
|
'elephant',
|
||||||
|
'bear',
|
||||||
|
'zebra',
|
||||||
|
'giraffe',
|
||||||
|
'hat',
|
||||||
|
'backpack',
|
||||||
|
'umbrella',
|
||||||
|
'shoe',
|
||||||
|
'eye glasses',
|
||||||
|
'handbag',
|
||||||
|
'tie',
|
||||||
|
'suitcase',
|
||||||
|
'frisbee',
|
||||||
|
'skis',
|
||||||
|
'snowboard',
|
||||||
|
'sports ball',
|
||||||
|
'kite',
|
||||||
|
'baseball bat',
|
||||||
|
'baseball glove',
|
||||||
|
'skateboard',
|
||||||
|
'surfboard',
|
||||||
|
'tennis racket',
|
||||||
|
'bottle',
|
||||||
|
'plate',
|
||||||
|
'wine glass',
|
||||||
|
'cup',
|
||||||
|
'fork',
|
||||||
|
'knife',
|
||||||
|
'spoon',
|
||||||
|
'bowl',
|
||||||
|
'banana',
|
||||||
|
'apple',
|
||||||
|
'sandwich',
|
||||||
|
'orange',
|
||||||
|
'broccoli',
|
||||||
|
'carrot',
|
||||||
|
'hot dog',
|
||||||
|
'pizza',
|
||||||
|
'donut',
|
||||||
|
'cake',
|
||||||
|
'chair',
|
||||||
|
'couch',
|
||||||
|
'potted plant',
|
||||||
|
'bed',
|
||||||
|
'mirror',
|
||||||
|
'dining table',
|
||||||
|
'window',
|
||||||
|
'desk',
|
||||||
|
'toilet',
|
||||||
|
'door',
|
||||||
|
'tv',
|
||||||
|
'laptop',
|
||||||
|
'mouse',
|
||||||
|
'remote',
|
||||||
|
'keyboard',
|
||||||
|
'cell phone',
|
||||||
|
'microwave',
|
||||||
|
'oven',
|
||||||
|
'toaster',
|
||||||
|
'sink',
|
||||||
|
'refrigerator',
|
||||||
|
'blender',
|
||||||
|
'book',
|
||||||
|
'clock',
|
||||||
|
'vase',
|
||||||
|
'scissors',
|
||||||
|
'teddy bear',
|
||||||
|
'hair drier',
|
||||||
|
'toothbrush',
|
||||||
|
]
|
||||||
|
|
||||||
|
EGOHANDS_CLASSES_LIST = [
|
||||||
|
'background',
|
||||||
|
'hand',
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def get_cls_dict(model):
|
||||||
|
"""Get the class ID to name translation dictionary."""
|
||||||
|
if model == 'coco':
|
||||||
|
cls_list = COCO_CLASSES_LIST
|
||||||
|
elif model == 'egohands':
|
||||||
|
cls_list = EGOHANDS_CLASSES_LIST
|
||||||
|
else:
|
||||||
|
raise ValueError('Bad model name')
|
||||||
|
return {i: n for i, n in enumerate(cls_list)}
|
||||||
|
|
@ -0,0 +1,59 @@
|
||||||
|
"""ssd_tf.py
|
||||||
|
|
||||||
|
This module implements the TfSSD class.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
import tensorflow as tf
|
||||||
|
|
||||||
|
|
||||||
|
def _postprocess_tf(img, boxes, scores, classes, conf_th):
|
||||||
|
"""Postprocess TensorFlow SSD output."""
|
||||||
|
h, w, _ = img.shape
|
||||||
|
out_boxes = boxes[0] * np.array([h, w, h, w])
|
||||||
|
out_boxes = out_boxes.astype(np.int32)
|
||||||
|
out_boxes = out_boxes[:, [1, 0, 3, 2]] # swap x's and y's
|
||||||
|
out_confs = scores[0]
|
||||||
|
out_clss = classes[0].astype(np.int32)
|
||||||
|
|
||||||
|
# only return bboxes with confidence score above threshold
|
||||||
|
mask = np.where(out_confs >= conf_th)
|
||||||
|
return out_boxes[mask], out_confs[mask], out_clss[mask]
|
||||||
|
|
||||||
|
|
||||||
|
class TfSSD(object):
|
||||||
|
"""TfSSD class encapsulates things needed to run TensorFlow SSD."""
|
||||||
|
|
||||||
|
def __init__(self, model, input_shape):
|
||||||
|
self.model = model
|
||||||
|
self.input_shape = input_shape
|
||||||
|
|
||||||
|
# load detection graph
|
||||||
|
ssd_graph = tf.Graph()
|
||||||
|
with ssd_graph.as_default():
|
||||||
|
graph_def = tf.GraphDef()
|
||||||
|
with tf.gfile.GFile('ssd/%s.pb' % model, 'rb') as fid:
|
||||||
|
serialized_graph = fid.read()
|
||||||
|
graph_def.ParseFromString(serialized_graph)
|
||||||
|
tf.import_graph_def(graph_def, name='')
|
||||||
|
|
||||||
|
# define input/output tensors
|
||||||
|
self.image_tensor = ssd_graph.get_tensor_by_name('image_tensor:0')
|
||||||
|
self.det_boxes = ssd_graph.get_tensor_by_name('detection_boxes:0')
|
||||||
|
self.det_scores = ssd_graph.get_tensor_by_name('detection_scores:0')
|
||||||
|
self.det_classes = ssd_graph.get_tensor_by_name('detection_classes:0')
|
||||||
|
|
||||||
|
# create the session for inferencing
|
||||||
|
self.sess = tf.Session(graph=ssd_graph)
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.sess.close()
|
||||||
|
|
||||||
|
def detect(self, img, conf_th):
|
||||||
|
img_resized = _preprocess_tf(img, self.input_shape)
|
||||||
|
boxes, scores, classes = self.sess.run(
|
||||||
|
[self.det_boxes, self.det_scores, self.det_classes],
|
||||||
|
feed_dict={self.image_tensor: np.expand_dims(img_resized, 0)})
|
||||||
|
return _postprocess_tf(img, boxes, scores, classes, conf_th)
|
||||||
|
|
@ -0,0 +1,102 @@
|
||||||
|
"""visualization.py
|
||||||
|
|
||||||
|
The BBoxVisualization class implements drawing of nice looking
|
||||||
|
bounding boxes based on object detection results.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
|
||||||
|
# Constants
|
||||||
|
ALPHA = 0.5
|
||||||
|
FONT = cv2.FONT_HERSHEY_PLAIN
|
||||||
|
TEXT_SCALE = 1.0
|
||||||
|
TEXT_THICKNESS = 1
|
||||||
|
BLACK = (0, 0, 0)
|
||||||
|
WHITE = (255, 255, 255)
|
||||||
|
|
||||||
|
|
||||||
|
def gen_colors(num_colors):
|
||||||
|
"""Generate different colors.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
num_colors: total number of colors/classes.
|
||||||
|
|
||||||
|
# Output
|
||||||
|
bgrs: a list of (B, G, R) tuples which correspond to each of
|
||||||
|
the colors/classes.
|
||||||
|
"""
|
||||||
|
import random
|
||||||
|
import colorsys
|
||||||
|
|
||||||
|
hsvs = [[float(x) / num_colors, 1., 0.7] for x in range(num_colors)]
|
||||||
|
random.seed(1234)
|
||||||
|
random.shuffle(hsvs)
|
||||||
|
rgbs = list(map(lambda x: list(colorsys.hsv_to_rgb(*x)), hsvs))
|
||||||
|
bgrs = [(int(rgb[2] * 255), int(rgb[1] * 255), int(rgb[0] * 255))
|
||||||
|
for rgb in rgbs]
|
||||||
|
return bgrs
|
||||||
|
|
||||||
|
|
||||||
|
def draw_boxed_text(img, text, topleft, color):
|
||||||
|
"""Draw a transluent boxed text in white, overlayed on top of a
|
||||||
|
colored patch surrounded by a black border. FONT, TEXT_SCALE,
|
||||||
|
TEXT_THICKNESS and ALPHA values are constants (fixed) as defined
|
||||||
|
on top.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
img: the input image as a numpy array.
|
||||||
|
text: the text to be drawn.
|
||||||
|
topleft: XY coordinate of the topleft corner of the boxed text.
|
||||||
|
color: color of the patch, i.e. background of the text.
|
||||||
|
|
||||||
|
# Output
|
||||||
|
img: note the original image is modified inplace.
|
||||||
|
"""
|
||||||
|
assert img.dtype == np.uint8
|
||||||
|
img_h, img_w, _ = img.shape
|
||||||
|
if topleft[0] >= img_w or topleft[1] >= img_h:
|
||||||
|
return img
|
||||||
|
margin = 3
|
||||||
|
size = cv2.getTextSize(text, FONT, TEXT_SCALE, TEXT_THICKNESS)
|
||||||
|
w = size[0][0] + margin * 2
|
||||||
|
h = size[0][1] + margin * 2
|
||||||
|
# the patch is used to draw boxed text
|
||||||
|
patch = np.zeros((h, w, 3), dtype=np.uint8)
|
||||||
|
patch[...] = color
|
||||||
|
cv2.putText(patch, text, (margin+1, h-margin-2), FONT, TEXT_SCALE,
|
||||||
|
WHITE, thickness=TEXT_THICKNESS, lineType=cv2.LINE_8)
|
||||||
|
cv2.rectangle(patch, (0, 0), (w-1, h-1), BLACK, thickness=1)
|
||||||
|
w = min(w, img_w - topleft[0]) # clip overlay at image boundary
|
||||||
|
h = min(h, img_h - topleft[1])
|
||||||
|
# Overlay the boxed text onto region of interest (roi) in img
|
||||||
|
roi = img[topleft[1]:topleft[1]+h, topleft[0]:topleft[0]+w, :]
|
||||||
|
cv2.addWeighted(patch[0:h, 0:w, :], ALPHA, roi, 1 - ALPHA, 0, roi)
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
class BBoxVisualization():
|
||||||
|
"""BBoxVisualization class implements nice drawing of boudning boxes.
|
||||||
|
|
||||||
|
# Arguments
|
||||||
|
cls_dict: a dictionary used to translate class id to its name.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, cls_dict):
|
||||||
|
self.cls_dict = cls_dict
|
||||||
|
self.colors = gen_colors(len(cls_dict))
|
||||||
|
|
||||||
|
def draw_bboxes(self, img, boxes, confs, clss):
|
||||||
|
"""Draw detected bounding boxes on the original image."""
|
||||||
|
for bb, cf, cl in zip(boxes, confs, clss):
|
||||||
|
cl = int(cl)
|
||||||
|
x_min, y_min, x_max, y_max = bb[0], bb[1], bb[2], bb[3]
|
||||||
|
color = self.colors[cl]
|
||||||
|
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), color, 2)
|
||||||
|
txt_loc = (max(x_min+2, 0), max(y_min+2, 0))
|
||||||
|
cls_name = self.cls_dict.get(cl, 'CLS{}'.format(cl))
|
||||||
|
txt = '{} {:.2f}'.format(cls_name, cf)
|
||||||
|
img = draw_boxed_text(img, txt, txt_loc, color)
|
||||||
|
return img
|
||||||
|
|
@ -0,0 +1,30 @@
|
||||||
|
"""writer.py
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
import subprocess
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
|
||||||
|
def get_video_writer(name, width, height, fps=30):
|
||||||
|
"""Get a VideoWriter object for saving output video.
|
||||||
|
|
||||||
|
This function tries to use Jetson's hardware H.264 encoder (omxh264enc)
|
||||||
|
if available, in which case the output video would be a MPEG-2 TS file.
|
||||||
|
Otherwise, it uses cv2's built-in encoding mechanism and saves a MP4
|
||||||
|
file.
|
||||||
|
"""
|
||||||
|
gst_elements = str(subprocess.check_output('gst-inspect-1.0'))
|
||||||
|
if 'omxh264dec' in gst_elements:
|
||||||
|
filename = name + '.ts' # Transport Stream
|
||||||
|
gst_str = ('appsrc ! videoconvert ! omxh264enc ! mpegtsmux ! '
|
||||||
|
'filesink location=%s') % filename
|
||||||
|
return cv2.VideoWriter(
|
||||||
|
gst_str, cv2.CAP_GSTREAMER, 0, fps, (width, height))
|
||||||
|
else:
|
||||||
|
filename = name + '.mp4' # MP4
|
||||||
|
return cv2.VideoWriter(
|
||||||
|
filename, cv2.VideoWriter_fourcc(*'mp4v'), fps, (width, height))
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -0,0 +1,104 @@
|
||||||
|
"""yolo_classes.py
|
||||||
|
|
||||||
|
NOTE: Number of YOLO COCO output classes differs from SSD COCO models.
|
||||||
|
"""
|
||||||
|
|
||||||
|
COCO_CLASSES_LIST = [
|
||||||
|
'person',
|
||||||
|
'bicycle',
|
||||||
|
'car',
|
||||||
|
'motorbike',
|
||||||
|
'aeroplane',
|
||||||
|
'bus',
|
||||||
|
'train',
|
||||||
|
'truck',
|
||||||
|
'boat',
|
||||||
|
'traffic light',
|
||||||
|
'fire hydrant',
|
||||||
|
'stop sign',
|
||||||
|
'parking meter',
|
||||||
|
'bench',
|
||||||
|
'bird',
|
||||||
|
'cat',
|
||||||
|
'dog',
|
||||||
|
'horse',
|
||||||
|
'sheep',
|
||||||
|
'cow',
|
||||||
|
'elephant',
|
||||||
|
'bear',
|
||||||
|
'zebra',
|
||||||
|
'giraffe',
|
||||||
|
'backpack',
|
||||||
|
'umbrella',
|
||||||
|
'handbag',
|
||||||
|
'tie',
|
||||||
|
'suitcase',
|
||||||
|
'frisbee',
|
||||||
|
'skis',
|
||||||
|
'snowboard',
|
||||||
|
'sports ball',
|
||||||
|
'kite',
|
||||||
|
'baseball bat',
|
||||||
|
'baseball glove',
|
||||||
|
'skateboard',
|
||||||
|
'surfboard',
|
||||||
|
'tennis racket',
|
||||||
|
'bottle',
|
||||||
|
'wine glass',
|
||||||
|
'cup',
|
||||||
|
'fork',
|
||||||
|
'knife',
|
||||||
|
'spoon',
|
||||||
|
'bowl',
|
||||||
|
'banana',
|
||||||
|
'apple',
|
||||||
|
'sandwich',
|
||||||
|
'orange',
|
||||||
|
'broccoli',
|
||||||
|
'carrot',
|
||||||
|
'hot dog',
|
||||||
|
'pizza',
|
||||||
|
'donut',
|
||||||
|
'cake',
|
||||||
|
'chair',
|
||||||
|
'sofa',
|
||||||
|
'pottedplant',
|
||||||
|
'bed',
|
||||||
|
'diningtable',
|
||||||
|
'toilet',
|
||||||
|
'tvmonitor',
|
||||||
|
'laptop',
|
||||||
|
'mouse',
|
||||||
|
'remote',
|
||||||
|
'keyboard',
|
||||||
|
'cell phone',
|
||||||
|
'microwave',
|
||||||
|
'oven',
|
||||||
|
'toaster',
|
||||||
|
'sink',
|
||||||
|
'refrigerator',
|
||||||
|
'book',
|
||||||
|
'clock',
|
||||||
|
'vase',
|
||||||
|
'scissors',
|
||||||
|
'teddy bear',
|
||||||
|
'hair drier',
|
||||||
|
'toothbrush',
|
||||||
|
]
|
||||||
|
|
||||||
|
# For translating YOLO class ids (0~79) to SSD class ids (0~90)
|
||||||
|
yolo_cls_to_ssd = [
|
||||||
|
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20,
|
||||||
|
21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
|
||||||
|
41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58,
|
||||||
|
59, 60, 61, 62, 63, 64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79,
|
||||||
|
80, 81, 82, 84, 85, 86, 87, 88, 89, 90,
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def get_cls_dict(category_num):
|
||||||
|
"""Get the class ID to name translation dictionary."""
|
||||||
|
if category_num == 80:
|
||||||
|
return {i: n for i, n in enumerate(COCO_CLASSES_LIST)}
|
||||||
|
else:
|
||||||
|
return {i: 'CLS%d' % i for i in range(category_num)}
|
||||||
|
|
@ -0,0 +1,338 @@
|
||||||
|
"""yolo_with_plugins.py
|
||||||
|
|
||||||
|
Implementation of TrtYOLO class with the yolo_layer plugins.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
from __future__ import print_function
|
||||||
|
|
||||||
|
import ctypes
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
import tensorrt as trt
|
||||||
|
import pycuda.driver as cuda
|
||||||
|
|
||||||
|
|
||||||
|
try:
|
||||||
|
ctypes.cdll.LoadLibrary('./plugins/libyolo_layer.so')
|
||||||
|
except OSError as e:
|
||||||
|
raise SystemExit('ERROR: failed to load ./plugins/libyolo_layer.so. '
|
||||||
|
'Did you forget to do a "make" in the "./plugins/" '
|
||||||
|
'subdirectory?') from e
|
||||||
|
|
||||||
|
|
||||||
|
def _preprocess_yolo(img, input_shape, letter_box=False):
|
||||||
|
"""Preprocess an image before TRT YOLO inferencing.
|
||||||
|
|
||||||
|
# Args
|
||||||
|
img: int8 numpy array of shape (img_h, img_w, 3)
|
||||||
|
input_shape: a tuple of (H, W)
|
||||||
|
letter_box: boolean, specifies whether to keep aspect ratio and
|
||||||
|
create a "letterboxed" image for inference
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
preprocessed img: float32 numpy array of shape (3, H, W)
|
||||||
|
"""
|
||||||
|
if letter_box:
|
||||||
|
img_h, img_w, _ = img.shape
|
||||||
|
new_h, new_w = input_shape[0], input_shape[1]
|
||||||
|
offset_h, offset_w = 0, 0
|
||||||
|
if (new_w / img_w) <= (new_h / img_h):
|
||||||
|
new_h = int(img_h * new_w / img_w)
|
||||||
|
offset_h = (input_shape[0] - new_h) // 2
|
||||||
|
else:
|
||||||
|
new_w = int(img_w * new_h / img_h)
|
||||||
|
offset_w = (input_shape[1] - new_w) // 2
|
||||||
|
resized = cv2.resize(img, (new_w, new_h))
|
||||||
|
img = np.full((input_shape[0], input_shape[1], 3), 127, dtype=np.uint8)
|
||||||
|
img[offset_h:(offset_h + new_h), offset_w:(offset_w + new_w), :] = resized
|
||||||
|
else:
|
||||||
|
img = cv2.resize(img, (input_shape[1], input_shape[0]))
|
||||||
|
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
||||||
|
img = img.transpose((2, 0, 1)).astype(np.float32)
|
||||||
|
img /= 255.0
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
def _nms_boxes(detections, nms_threshold):
|
||||||
|
"""Apply the Non-Maximum Suppression (NMS) algorithm on the bounding
|
||||||
|
boxes with their confidence scores and return an array with the
|
||||||
|
indexes of the bounding boxes we want to keep.
|
||||||
|
|
||||||
|
# Args
|
||||||
|
detections: Nx7 numpy arrays of
|
||||||
|
[[x, y, w, h, box_confidence, class_id, class_prob],
|
||||||
|
......]
|
||||||
|
"""
|
||||||
|
x_coord = detections[:, 0]
|
||||||
|
y_coord = detections[:, 1]
|
||||||
|
width = detections[:, 2]
|
||||||
|
height = detections[:, 3]
|
||||||
|
box_confidences = detections[:, 4] * detections[:, 6]
|
||||||
|
|
||||||
|
areas = width * height
|
||||||
|
ordered = box_confidences.argsort()[::-1]
|
||||||
|
|
||||||
|
keep = list()
|
||||||
|
while ordered.size > 0:
|
||||||
|
# Index of the current element:
|
||||||
|
i = ordered[0]
|
||||||
|
keep.append(i)
|
||||||
|
xx1 = np.maximum(x_coord[i], x_coord[ordered[1:]])
|
||||||
|
yy1 = np.maximum(y_coord[i], y_coord[ordered[1:]])
|
||||||
|
xx2 = np.minimum(x_coord[i] + width[i], x_coord[ordered[1:]] + width[ordered[1:]])
|
||||||
|
yy2 = np.minimum(y_coord[i] + height[i], y_coord[ordered[1:]] + height[ordered[1:]])
|
||||||
|
|
||||||
|
width1 = np.maximum(0.0, xx2 - xx1 + 1)
|
||||||
|
height1 = np.maximum(0.0, yy2 - yy1 + 1)
|
||||||
|
intersection = width1 * height1
|
||||||
|
union = (areas[i] + areas[ordered[1:]] - intersection)
|
||||||
|
iou = intersection / union
|
||||||
|
indexes = np.where(iou <= nms_threshold)[0]
|
||||||
|
ordered = ordered[indexes + 1]
|
||||||
|
|
||||||
|
keep = np.array(keep)
|
||||||
|
return keep
|
||||||
|
|
||||||
|
|
||||||
|
def _postprocess_yolo(trt_outputs, img_w, img_h, conf_th, nms_threshold,
|
||||||
|
input_shape, letter_box=False):
|
||||||
|
"""Postprocess TensorRT outputs.
|
||||||
|
|
||||||
|
# Args
|
||||||
|
trt_outputs: a list of 2 or 3 tensors, where each tensor
|
||||||
|
contains a multiple of 7 float32 numbers in
|
||||||
|
the order of [x, y, w, h, box_confidence, class_id, class_prob]
|
||||||
|
conf_th: confidence threshold
|
||||||
|
letter_box: boolean, referring to _preprocess_yolo()
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
boxes, scores, classes (after NMS)
|
||||||
|
"""
|
||||||
|
# filter low-conf detections and concatenate results of all yolo layers
|
||||||
|
detections = []
|
||||||
|
for o in trt_outputs:
|
||||||
|
dets = o.reshape((-1, 7))
|
||||||
|
dets = dets[dets[:, 4] * dets[:, 6] >= conf_th]
|
||||||
|
detections.append(dets)
|
||||||
|
detections = np.concatenate(detections, axis=0)
|
||||||
|
|
||||||
|
if len(detections) == 0:
|
||||||
|
boxes = np.zeros((0, 4), dtype=np.int)
|
||||||
|
scores = np.zeros((0,), dtype=np.float32)
|
||||||
|
classes = np.zeros((0,), dtype=np.float32)
|
||||||
|
else:
|
||||||
|
box_scores = detections[:, 4] * detections[:, 6]
|
||||||
|
|
||||||
|
# scale x, y, w, h from [0, 1] to pixel values
|
||||||
|
old_h, old_w = img_h, img_w
|
||||||
|
offset_h, offset_w = 0, 0
|
||||||
|
if letter_box:
|
||||||
|
if (img_w / input_shape[1]) >= (img_h / input_shape[0]):
|
||||||
|
old_h = int(input_shape[0] * img_w / input_shape[1])
|
||||||
|
offset_h = (old_h - img_h) // 2
|
||||||
|
else:
|
||||||
|
old_w = int(input_shape[1] * img_h / input_shape[0])
|
||||||
|
offset_w = (old_w - img_w) // 2
|
||||||
|
detections[:, 0:4] *= np.array(
|
||||||
|
[old_w, old_h, old_w, old_h], dtype=np.float32)
|
||||||
|
|
||||||
|
# NMS
|
||||||
|
nms_detections = np.zeros((0, 7), dtype=detections.dtype)
|
||||||
|
for class_id in set(detections[:, 5]):
|
||||||
|
idxs = np.where(detections[:, 5] == class_id)
|
||||||
|
cls_detections = detections[idxs]
|
||||||
|
keep = _nms_boxes(cls_detections, nms_threshold)
|
||||||
|
nms_detections = np.concatenate(
|
||||||
|
[nms_detections, cls_detections[keep]], axis=0)
|
||||||
|
|
||||||
|
xx = nms_detections[:, 0].reshape(-1, 1)
|
||||||
|
yy = nms_detections[:, 1].reshape(-1, 1)
|
||||||
|
if letter_box:
|
||||||
|
xx = xx - offset_w
|
||||||
|
yy = yy - offset_h
|
||||||
|
ww = nms_detections[:, 2].reshape(-1, 1)
|
||||||
|
hh = nms_detections[:, 3].reshape(-1, 1)
|
||||||
|
boxes = np.concatenate([xx, yy, xx+ww, yy+hh], axis=1) + 0.5
|
||||||
|
boxes = boxes.astype(np.int)
|
||||||
|
scores = nms_detections[:, 4] * nms_detections[:, 6]
|
||||||
|
classes = nms_detections[:, 5]
|
||||||
|
return boxes, scores, classes
|
||||||
|
|
||||||
|
|
||||||
|
class HostDeviceMem(object):
|
||||||
|
"""Simple helper data class that's a little nicer to use than a 2-tuple."""
|
||||||
|
def __init__(self, host_mem, device_mem):
|
||||||
|
self.host = host_mem
|
||||||
|
self.device = device_mem
|
||||||
|
|
||||||
|
def __str__(self):
|
||||||
|
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return self.__str__()
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
del self.device
|
||||||
|
del self.host
|
||||||
|
|
||||||
|
|
||||||
|
def get_input_shape(engine):
|
||||||
|
"""Get input shape of the TensorRT YOLO engine."""
|
||||||
|
binding = engine[0]
|
||||||
|
assert engine.binding_is_input(binding)
|
||||||
|
binding_dims = engine.get_binding_shape(binding)
|
||||||
|
if len(binding_dims) == 4:
|
||||||
|
return tuple(binding_dims[2:])
|
||||||
|
elif len(binding_dims) == 3:
|
||||||
|
return tuple(binding_dims[1:])
|
||||||
|
else:
|
||||||
|
raise ValueError('bad dims of binding %s: %s' % (binding, str(binding_dims)))
|
||||||
|
|
||||||
|
|
||||||
|
def allocate_buffers(engine):
|
||||||
|
"""Allocates all host/device in/out buffers required for an engine."""
|
||||||
|
inputs = []
|
||||||
|
outputs = []
|
||||||
|
bindings = []
|
||||||
|
output_idx = 0
|
||||||
|
stream = cuda.Stream()
|
||||||
|
for binding in engine:
|
||||||
|
binding_dims = engine.get_binding_shape(binding)
|
||||||
|
if len(binding_dims) == 4:
|
||||||
|
# explicit batch case (TensorRT 7+)
|
||||||
|
size = trt.volume(binding_dims)
|
||||||
|
elif len(binding_dims) == 3:
|
||||||
|
# implicit batch case (TensorRT 6 or older)
|
||||||
|
size = trt.volume(binding_dims) * engine.max_batch_size
|
||||||
|
else:
|
||||||
|
raise ValueError('bad dims of binding %s: %s' % (binding, str(binding_dims)))
|
||||||
|
dtype = trt.nptype(engine.get_binding_dtype(binding))
|
||||||
|
# Allocate host and device buffers
|
||||||
|
host_mem = cuda.pagelocked_empty(size, dtype)
|
||||||
|
device_mem = cuda.mem_alloc(host_mem.nbytes)
|
||||||
|
# Append the device buffer to device bindings.
|
||||||
|
bindings.append(int(device_mem))
|
||||||
|
# Append to the appropriate list.
|
||||||
|
if engine.binding_is_input(binding):
|
||||||
|
inputs.append(HostDeviceMem(host_mem, device_mem))
|
||||||
|
else:
|
||||||
|
# each grid has 3 anchors, each anchor generates a detection
|
||||||
|
# output of 7 float32 values
|
||||||
|
assert size % 7 == 0
|
||||||
|
outputs.append(HostDeviceMem(host_mem, device_mem))
|
||||||
|
output_idx += 1
|
||||||
|
assert len(inputs) == 1
|
||||||
|
assert len(outputs) == 1
|
||||||
|
return inputs, outputs, bindings, stream
|
||||||
|
|
||||||
|
|
||||||
|
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
|
||||||
|
"""do_inference (for TensorRT 6.x or lower)
|
||||||
|
|
||||||
|
This function is generalized for multiple inputs/outputs.
|
||||||
|
Inputs and outputs are expected to be lists of HostDeviceMem objects.
|
||||||
|
"""
|
||||||
|
# Transfer input data to the GPU.
|
||||||
|
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
|
||||||
|
# Run inference.
|
||||||
|
context.execute_async(batch_size=batch_size,
|
||||||
|
bindings=bindings,
|
||||||
|
stream_handle=stream.handle)
|
||||||
|
# Transfer predictions back from the GPU.
|
||||||
|
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
|
||||||
|
# Synchronize the stream
|
||||||
|
stream.synchronize()
|
||||||
|
# Return only the host outputs.
|
||||||
|
return [out.host for out in outputs]
|
||||||
|
|
||||||
|
|
||||||
|
def do_inference_v2(context, bindings, inputs, outputs, stream):
|
||||||
|
"""do_inference_v2 (for TensorRT 7.0+)
|
||||||
|
|
||||||
|
This function is generalized for multiple inputs/outputs for full
|
||||||
|
dimension networks.
|
||||||
|
Inputs and outputs are expected to be lists of HostDeviceMem objects.
|
||||||
|
"""
|
||||||
|
# Transfer input data to the GPU.
|
||||||
|
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
|
||||||
|
# Run inference.
|
||||||
|
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
|
||||||
|
# Transfer predictions back from the GPU.
|
||||||
|
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
|
||||||
|
# Synchronize the stream
|
||||||
|
stream.synchronize()
|
||||||
|
# Return only the host outputs.
|
||||||
|
return [out.host for out in outputs]
|
||||||
|
|
||||||
|
|
||||||
|
class TrtYOLO(object):
|
||||||
|
"""TrtYOLO class encapsulates things needed to run TRT YOLO."""
|
||||||
|
|
||||||
|
def _load_engine(self):
|
||||||
|
TRTbin = 'yolo/%s.trt' % self.model
|
||||||
|
with open(TRTbin, 'rb') as f, trt.Runtime(self.trt_logger) as runtime:
|
||||||
|
return runtime.deserialize_cuda_engine(f.read())
|
||||||
|
|
||||||
|
def __init__(self, model, category_num=80, letter_box=False, cuda_ctx=None):
|
||||||
|
"""Initialize TensorRT plugins, engine and conetxt."""
|
||||||
|
self.model = model
|
||||||
|
self.category_num = category_num
|
||||||
|
self.letter_box = letter_box
|
||||||
|
self.cuda_ctx = cuda_ctx
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.push()
|
||||||
|
|
||||||
|
self.inference_fn = do_inference if trt.__version__[0] < '7' \
|
||||||
|
else do_inference_v2
|
||||||
|
self.trt_logger = trt.Logger(trt.Logger.INFO)
|
||||||
|
self.engine = self._load_engine()
|
||||||
|
|
||||||
|
self.input_shape = get_input_shape(self.engine)
|
||||||
|
|
||||||
|
try:
|
||||||
|
self.context = self.engine.create_execution_context()
|
||||||
|
self.inputs, self.outputs, self.bindings, self.stream = \
|
||||||
|
allocate_buffers(self.engine)
|
||||||
|
except Exception as e:
|
||||||
|
raise RuntimeError('fail to allocate CUDA resources') from e
|
||||||
|
finally:
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.pop()
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
"""Free CUDA memories."""
|
||||||
|
del self.outputs
|
||||||
|
del self.inputs
|
||||||
|
del self.stream
|
||||||
|
|
||||||
|
def detect(self, img, conf_th=0.3, letter_box=None):
|
||||||
|
"""Detect objects in the input image."""
|
||||||
|
letter_box = self.letter_box if letter_box is None else letter_box
|
||||||
|
img_resized = _preprocess_yolo(img, self.input_shape, letter_box)
|
||||||
|
|
||||||
|
# Set host input to the image. The do_inference() function
|
||||||
|
# will copy the input to the GPU before executing.
|
||||||
|
self.inputs[0].host = np.ascontiguousarray(img_resized)
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.push()
|
||||||
|
trt_outputs = self.inference_fn(
|
||||||
|
context=self.context,
|
||||||
|
bindings=self.bindings,
|
||||||
|
inputs=self.inputs,
|
||||||
|
outputs=self.outputs,
|
||||||
|
stream=self.stream)
|
||||||
|
if self.cuda_ctx:
|
||||||
|
self.cuda_ctx.pop()
|
||||||
|
|
||||||
|
boxes, scores, classes = _postprocess_yolo(
|
||||||
|
trt_outputs, img.shape[1], img.shape[0], conf_th,
|
||||||
|
nms_threshold=0.5, input_shape=self.input_shape,
|
||||||
|
letter_box=letter_box)
|
||||||
|
|
||||||
|
# clip x1, y1, x2, y2 within original image
|
||||||
|
boxes[:, [0, 2]] = np.clip(boxes[:, [0, 2]], 0, img.shape[1]-1)
|
||||||
|
boxes[:, [1, 3]] = np.clip(boxes[:, [1, 3]], 0, img.shape[0]-1)
|
||||||
|
return boxes, scores, classes
|
||||||
|
|
@ -0,0 +1,43 @@
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
# I use this script to build DLA0 and DLA1 TensorRT engines for various
|
||||||
|
# yolov3 and yolov4 models.
|
||||||
|
|
||||||
|
set -e
|
||||||
|
|
||||||
|
models="yolov3-tiny-416 yolov3-608 yolov3-spp-608 yolov4-tiny-416 yolov4-608"
|
||||||
|
|
||||||
|
# make sure all needed files are present
|
||||||
|
for m in ${models}; do
|
||||||
|
if [[ ! -f ${m}.cfg ]]; then
|
||||||
|
echo "ERROR: cannot find the file ${m}.cfg"
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
if [[ ! -f ${m}.onnx ]]; then
|
||||||
|
echo "ERROR: cannot find the file ${m}.onnx"
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
|
||||||
|
# create symbolic links to cfg and onnx files
|
||||||
|
for m in ${models}; do
|
||||||
|
m_head=${m%-*}
|
||||||
|
m_tail=${m##*-}
|
||||||
|
ln -sf ${m}.cfg ${m_head}-dla0-${m_tail}.cfg
|
||||||
|
ln -sf ${m}.onnx ${m_head}-dla0-${m_tail}.onnx
|
||||||
|
ln -sf ${m}.cfg ${m_head}-dla1-${m_tail}.cfg
|
||||||
|
ln -sf ${m}.onnx ${m_head}-dla1-${m_tail}.onnx
|
||||||
|
done
|
||||||
|
|
||||||
|
# build TensorRT engines
|
||||||
|
for m in ${models}; do
|
||||||
|
m_head=${m%-*}
|
||||||
|
m_tail=${m##*-}
|
||||||
|
echo ; echo === ${m_head}-dla0-${m_tail} === ; echo
|
||||||
|
python3 onnx_to_tensorrt.py --int8 --dla_core 0 -m ${m_head}-dla0-${m_tail}
|
||||||
|
echo ; echo === ${m_head}-dla1-${m_tail} === ; echo
|
||||||
|
python3 onnx_to_tensorrt.py --int8 --dla_core 1 -m ${m_head}-dla1-${m_tail}
|
||||||
|
done
|
||||||
|
|
||||||
|
echo
|
||||||
|
echo "Done."
|
||||||
|
|
@ -0,0 +1,39 @@
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
# I use this script to build INT8 TensorRT engines for various yolov3 and
|
||||||
|
# yolov4 models.
|
||||||
|
|
||||||
|
set -e
|
||||||
|
|
||||||
|
models="yolov3-tiny-416 yolov3-608 yolov3-spp-608 yolov4-tiny-416 yolov4-608"
|
||||||
|
|
||||||
|
# make sure all needed files are present
|
||||||
|
for m in ${models}; do
|
||||||
|
if [[ ! -f ${m}.cfg ]]; then
|
||||||
|
echo "ERROR: cannot find the file ${m}.cfg"
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
if [[ ! -f ${m}.onnx ]]; then
|
||||||
|
echo "ERROR: cannot find the file ${m}.onnx"
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
|
||||||
|
# create symbolic links to cfg and onnx files
|
||||||
|
for m in ${models}; do
|
||||||
|
m_head=${m%-*}
|
||||||
|
m_tail=${m##*-}
|
||||||
|
ln -sf ${m}.cfg ${m_head}-int8-${m_tail}.cfg
|
||||||
|
ln -sf ${m}.onnx ${m_head}-int8-${m_tail}.onnx
|
||||||
|
done
|
||||||
|
|
||||||
|
# build TensorRT engines
|
||||||
|
for m in ${models}; do
|
||||||
|
m_head=${m%-*}
|
||||||
|
m_tail=${m##*-}
|
||||||
|
echo ; echo === ${m_head}-int8-${m_tail} === ; echo
|
||||||
|
python3 onnx_to_tensorrt.py --int8 -m ${m_head}-int8-${m_tail}
|
||||||
|
done
|
||||||
|
|
||||||
|
echo
|
||||||
|
echo "Done."
|
||||||
|
|
@ -0,0 +1,251 @@
|
||||||
|
TRT-7103-EntropyCalibration2
|
||||||
|
000_net: 3c010a14
|
||||||
|
001_convolutional: 3caf6955
|
||||||
|
001_convolutional_bn: 3e068c22
|
||||||
|
001_convolutional_lrelu: 3d9f315c
|
||||||
|
002_convolutional: 3e9e5cba
|
||||||
|
002_convolutional_bn: 3dac3fc1
|
||||||
|
002_convolutional_lrelu: 3d23ae07
|
||||||
|
003_convolutional: 3e07e38b
|
||||||
|
003_convolutional_bn: 3df2b08f
|
||||||
|
003_convolutional_lrelu: 3d625e33
|
||||||
|
004_convolutional: 3db20ea3
|
||||||
|
004_convolutional_bn: 3dd5690a
|
||||||
|
004_convolutional_lrelu: 3d908773
|
||||||
|
005_shortcut: 3db8db93
|
||||||
|
006_convolutional: 3e96d31a
|
||||||
|
006_convolutional_bn: 3dd71b8e
|
||||||
|
006_convolutional_lrelu: 3d6b0087
|
||||||
|
007_convolutional: 3d80ca3f
|
||||||
|
007_convolutional_bn: 3d9a59ab
|
||||||
|
007_convolutional_lrelu: 3d0be6c5
|
||||||
|
008_convolutional: 3dd0c902
|
||||||
|
008_convolutional_bn: 3d41ad06
|
||||||
|
008_convolutional_lrelu: 3d09817f
|
||||||
|
009_shortcut: 3d6a5051
|
||||||
|
010_convolutional: 3df61395
|
||||||
|
010_convolutional_bn: 3dda058a
|
||||||
|
010_convolutional_lrelu: 3d2f1d07
|
||||||
|
011_convolutional: 3d60e65a
|
||||||
|
011_convolutional_bn: 3db28825
|
||||||
|
011_convolutional_lrelu: 3d55a1c7
|
||||||
|
012_shortcut: 3d92eb36
|
||||||
|
013_convolutional: 3e76215d
|
||||||
|
013_convolutional_bn: 3dadb84b
|
||||||
|
013_convolutional_lrelu: 3d19feb3
|
||||||
|
014_convolutional: 3d2e642b
|
||||||
|
014_convolutional_bn: 3d903514
|
||||||
|
014_convolutional_lrelu: 3d0c08a6
|
||||||
|
015_convolutional: 3ceab745
|
||||||
|
015_convolutional_bn: 3d3364e6
|
||||||
|
015_convolutional_lrelu: 3c9ec4fa
|
||||||
|
016_shortcut: 3d2244f8
|
||||||
|
017_convolutional: 3d7674cc
|
||||||
|
017_convolutional_bn: 3d9297cd
|
||||||
|
017_convolutional_lrelu: 3d158097
|
||||||
|
018_convolutional: 3d381760
|
||||||
|
018_convolutional_bn: 3d3836c7
|
||||||
|
018_convolutional_lrelu: 3cb3ed07
|
||||||
|
019_shortcut: 3d27aee4
|
||||||
|
020_convolutional: 3d5d677c
|
||||||
|
020_convolutional_bn: 3d88b4f1
|
||||||
|
020_convolutional_lrelu: 3d01ae43
|
||||||
|
021_convolutional: 3d1eb2b4
|
||||||
|
021_convolutional_bn: 3d5ff557
|
||||||
|
021_convolutional_lrelu: 3cad4ba3
|
||||||
|
022_shortcut: 3d438d1a
|
||||||
|
023_convolutional: 3d48a468
|
||||||
|
023_convolutional_bn: 3d786211
|
||||||
|
023_convolutional_lrelu: 3d17a3aa
|
||||||
|
024_convolutional: 3d19821e
|
||||||
|
024_convolutional_bn: 3d500fe5
|
||||||
|
024_convolutional_lrelu: 3c95a26c
|
||||||
|
025_shortcut: 3d5db913
|
||||||
|
026_convolutional: 3d734ce0
|
||||||
|
026_convolutional_bn: 3d9288af
|
||||||
|
026_convolutional_lrelu: 3cfaa739
|
||||||
|
027_convolutional: 3d050035
|
||||||
|
027_convolutional_bn: 3d5e24d9
|
||||||
|
027_convolutional_lrelu: 3cf1386d
|
||||||
|
028_shortcut: 3d87ba8a
|
||||||
|
029_convolutional: 3d91eb8f
|
||||||
|
029_convolutional_bn: 3d88c4c3
|
||||||
|
029_convolutional_lrelu: 3cf97d18
|
||||||
|
030_convolutional: 3cbfe7a9
|
||||||
|
030_convolutional_bn: 3d753009
|
||||||
|
030_convolutional_lrelu: 3ce76734
|
||||||
|
031_shortcut: 3da2b67a
|
||||||
|
032_convolutional: 3d8ae662
|
||||||
|
032_convolutional_bn: 3d6dc036
|
||||||
|
032_convolutional_lrelu: 3cf030df
|
||||||
|
033_convolutional: 3cc7b805
|
||||||
|
033_convolutional_bn: 3d9e9c78
|
||||||
|
033_convolutional_lrelu: 3d0141eb
|
||||||
|
034_shortcut: 3dadb1bd
|
||||||
|
035_convolutional: 3dc80287
|
||||||
|
035_convolutional_bn: 3d83ea9e
|
||||||
|
035_convolutional_lrelu: 3d16f697
|
||||||
|
036_convolutional: 3cca9a74
|
||||||
|
036_convolutional_bn: 3da5ba97
|
||||||
|
036_convolutional_lrelu: 3d13634a
|
||||||
|
037_shortcut: 3d9f6d7c
|
||||||
|
038_convolutional: 3e48a0d1
|
||||||
|
038_convolutional_bn: 3da31bad
|
||||||
|
038_convolutional_lrelu: 3cf4e5a9
|
||||||
|
039_convolutional: 3cb6eb19
|
||||||
|
039_convolutional_bn: 3d7bc781
|
||||||
|
039_convolutional_lrelu: 3d167ab9
|
||||||
|
040_convolutional: 3d37a246
|
||||||
|
040_convolutional_bn: 3d16fcfe
|
||||||
|
040_convolutional_lrelu: 3c188e32
|
||||||
|
041_shortcut: 3d094bd6
|
||||||
|
042_convolutional: 3cde602e
|
||||||
|
042_convolutional_bn: 3d74dd3e
|
||||||
|
042_convolutional_lrelu: 3d2fe82e
|
||||||
|
043_convolutional: 3d23234a
|
||||||
|
043_convolutional_bn: 3d2168ad
|
||||||
|
043_convolutional_lrelu: 3c9973ed
|
||||||
|
044_shortcut: 3d0d99ee
|
||||||
|
045_convolutional: 3d187446
|
||||||
|
045_convolutional_bn: 3d92f11d
|
||||||
|
045_convolutional_lrelu: 3cec68f7
|
||||||
|
046_convolutional: 3ccca87d
|
||||||
|
046_convolutional_bn: 3d1ac05f
|
||||||
|
046_convolutional_lrelu: 3ca53f46
|
||||||
|
047_shortcut: 3d2deb7e
|
||||||
|
048_convolutional: 3d123aea
|
||||||
|
048_convolutional_bn: 3d7b73ce
|
||||||
|
048_convolutional_lrelu: 3cdd621a
|
||||||
|
049_convolutional: 3cb7eec5
|
||||||
|
049_convolutional_bn: 3d285180
|
||||||
|
049_convolutional_lrelu: 3c9f1060
|
||||||
|
050_shortcut: 3d4183f2
|
||||||
|
051_convolutional: 3d169fa6
|
||||||
|
051_convolutional_bn: 3d6c5487
|
||||||
|
051_convolutional_lrelu: 3cdc27f5
|
||||||
|
052_convolutional: 3cafb7f1
|
||||||
|
052_convolutional_bn: 3d676b6d
|
||||||
|
052_convolutional_lrelu: 3cc669bf
|
||||||
|
053_shortcut: 3d58553c
|
||||||
|
054_convolutional: 3d4431ff
|
||||||
|
054_convolutional_bn: 3d77211d
|
||||||
|
054_convolutional_lrelu: 3cb60dd9
|
||||||
|
055_convolutional: 3ccbdd32
|
||||||
|
055_convolutional_bn: 3d9dacae
|
||||||
|
055_convolutional_lrelu: 3cd91763
|
||||||
|
056_shortcut: 3d6109ac
|
||||||
|
057_convolutional: 3d52dd55
|
||||||
|
057_convolutional_bn: 3d6c94d2
|
||||||
|
057_convolutional_lrelu: 3cee7561
|
||||||
|
058_convolutional: 3cb64c42
|
||||||
|
058_convolutional_bn: 3d6277d4
|
||||||
|
058_convolutional_lrelu: 3cf0c943
|
||||||
|
059_shortcut: 3d7f0354
|
||||||
|
060_convolutional: 3d92ea8a
|
||||||
|
060_convolutional_bn: 3d72094c
|
||||||
|
060_convolutional_lrelu: 3cac1c4d
|
||||||
|
061_convolutional: 3cabc7bb
|
||||||
|
061_convolutional_bn: 3dbdaf93
|
||||||
|
061_convolutional_lrelu: 3d0fe91c
|
||||||
|
062_shortcut: 3d676bdc
|
||||||
|
063_convolutional: 3e17162f
|
||||||
|
063_convolutional_bn: 3da49ac5
|
||||||
|
063_convolutional_lrelu: 3cd12d71
|
||||||
|
064_convolutional: 3ccb7e4a
|
||||||
|
064_convolutional_bn: 3d9f890e
|
||||||
|
064_convolutional_lrelu: 3cd6b1e3
|
||||||
|
065_convolutional: 3d51c337
|
||||||
|
065_convolutional_bn: 3d54a422
|
||||||
|
065_convolutional_lrelu: 3cad4d05
|
||||||
|
066_shortcut: 3cbd0480
|
||||||
|
067_convolutional: 3d25bf62
|
||||||
|
067_convolutional_bn: 3db19b82
|
||||||
|
067_convolutional_lrelu: 3cadce78
|
||||||
|
068_convolutional: 3cd4fc22
|
||||||
|
068_convolutional_bn: 3d3a8d52
|
||||||
|
068_convolutional_lrelu: 3c958a32
|
||||||
|
069_shortcut: 3cf85d2e
|
||||||
|
070_convolutional: 3d20476b
|
||||||
|
070_convolutional_bn: 3da8df54
|
||||||
|
070_convolutional_lrelu: 3caa0643
|
||||||
|
071_convolutional: 3ce7af07
|
||||||
|
071_convolutional_bn: 3d62d3c4
|
||||||
|
071_convolutional_lrelu: 3c933e24
|
||||||
|
072_shortcut: 3d2010ef
|
||||||
|
073_convolutional: 3d96e66c
|
||||||
|
073_convolutional_bn: 3dce8bc7
|
||||||
|
073_convolutional_lrelu: 3c9a4f55
|
||||||
|
074_convolutional: 3cbad12f
|
||||||
|
074_convolutional_bn: 3ddf4782
|
||||||
|
074_convolutional_lrelu: 3cf96e12
|
||||||
|
075_shortcut: 3d574761
|
||||||
|
076_convolutional: 3d73897b
|
||||||
|
076_convolutional_bn: 3d8ce858
|
||||||
|
076_convolutional_lrelu: 3d09d4cc
|
||||||
|
077_convolutional: 3d6a1055
|
||||||
|
077_convolutional_bn: 3d80fb64
|
||||||
|
077_convolutional_lrelu: 3d064bfc
|
||||||
|
078_convolutional: 3d836b76
|
||||||
|
078_convolutional_bn: 3d7cddf5
|
||||||
|
078_convolutional_lrelu: 3cd7e74a
|
||||||
|
079_convolutional: 3d33fd20
|
||||||
|
079_convolutional_bn: 3d4d6a5b
|
||||||
|
079_convolutional_lrelu: 3cffb82b
|
||||||
|
080_convolutional: 3d48acf5
|
||||||
|
080_convolutional_bn: 3d5990ea
|
||||||
|
080_convolutional_lrelu: 3ca7b18d
|
||||||
|
081_convolutional: 3d293608
|
||||||
|
081_convolutional_bn: 3d8243ac
|
||||||
|
081_convolutional_lrelu: 3d2a41ed
|
||||||
|
082_convolutional: 3e600ce3
|
||||||
|
085_convolutional: 3d15d9b4
|
||||||
|
085_convolutional_bn: 3d9d4e34
|
||||||
|
085_convolutional_lrelu: 3d0d6c79
|
||||||
|
086_upsample: 3d676bdc
|
||||||
|
087_route: 3d676bdc
|
||||||
|
088_convolutional: 3de3e9c6
|
||||||
|
088_convolutional_bn: 3d8bbec1
|
||||||
|
088_convolutional_lrelu: 3ce2f1fc
|
||||||
|
089_convolutional: 3d97111d
|
||||||
|
089_convolutional_bn: 3d7d6e5b
|
||||||
|
089_convolutional_lrelu: 3cbd02b2
|
||||||
|
090_convolutional: 3d5b221f
|
||||||
|
090_convolutional_bn: 3d5a38be
|
||||||
|
090_convolutional_lrelu: 3c9c1ce1
|
||||||
|
091_convolutional: 3d60f3f0
|
||||||
|
091_convolutional_bn: 3d739f0a
|
||||||
|
091_convolutional_lrelu: 3cbcc688
|
||||||
|
092_convolutional: 3d6e15cb
|
||||||
|
092_convolutional_bn: 3d858930
|
||||||
|
092_convolutional_lrelu: 3ca557a8
|
||||||
|
093_convolutional: 3d23daec
|
||||||
|
093_convolutional_bn: 3d8df75f
|
||||||
|
093_convolutional_lrelu: 3d2cdaed
|
||||||
|
094_convolutional: 3e532129
|
||||||
|
097_convolutional: 3d162469
|
||||||
|
097_convolutional_bn: 3da84cb3
|
||||||
|
097_convolutional_lrelu: 3d5f6229
|
||||||
|
098_upsample: 3d9f6d7c
|
||||||
|
099_route: 3d9f6d7c
|
||||||
|
100_convolutional: 3dfac67e
|
||||||
|
100_convolutional_bn: 3d866014
|
||||||
|
100_convolutional_lrelu: 3d0dce7d
|
||||||
|
101_convolutional: 3daa6cbe
|
||||||
|
101_convolutional_bn: 3d78cb1a
|
||||||
|
101_convolutional_lrelu: 3d0899ae
|
||||||
|
102_convolutional: 3d52238b
|
||||||
|
102_convolutional_bn: 3d81353d
|
||||||
|
102_convolutional_lrelu: 3cd2c022
|
||||||
|
103_convolutional: 3dba7093
|
||||||
|
103_convolutional_bn: 3d5f9b69
|
||||||
|
103_convolutional_lrelu: 3cdd97b4
|
||||||
|
104_convolutional: 3d7c40c4
|
||||||
|
104_convolutional_bn: 3d84edc8
|
||||||
|
104_convolutional_lrelu: 3d03fc1f
|
||||||
|
105_convolutional: 3dc5494f
|
||||||
|
105_convolutional_bn: 3da84277
|
||||||
|
105_convolutional_lrelu: 3d4c3fb5
|
||||||
|
106_convolutional: 3e82ccc7
|
||||||
|
(Unnamed Layer* 246) [PluginV2IOExt]_output_0: 3efa5428
|
||||||
|
(Unnamed Layer* 247) [PluginV2IOExt]_output_0: 3ee20e1c
|
||||||
|
(Unnamed Layer* 248) [PluginV2IOExt]_output_0: 3eea2ede
|
||||||
|
|
@ -0,0 +1,258 @@
|
||||||
|
TRT-7103-EntropyCalibration2
|
||||||
|
000_net: 3c010a14
|
||||||
|
001_convolutional: 3cc1e6c2
|
||||||
|
001_convolutional_bn: 3e3dae13
|
||||||
|
001_convolutional_lrelu: 3ddcdcb3
|
||||||
|
002_convolutional: 3ea885a3
|
||||||
|
002_convolutional_bn: 3d877b95
|
||||||
|
002_convolutional_lrelu: 3d487bb9
|
||||||
|
003_convolutional: 3e079126
|
||||||
|
003_convolutional_bn: 3e07c5a9
|
||||||
|
003_convolutional_lrelu: 3d8a81fc
|
||||||
|
004_convolutional: 3e0897f9
|
||||||
|
004_convolutional_bn: 3df6b69d
|
||||||
|
004_convolutional_lrelu: 3d74ba9f
|
||||||
|
005_shortcut: 3db98c07
|
||||||
|
006_convolutional: 3ea9ffa3
|
||||||
|
006_convolutional_bn: 3e049b0f
|
||||||
|
006_convolutional_lrelu: 3d6afafa
|
||||||
|
007_convolutional: 3da8e7ab
|
||||||
|
007_convolutional_bn: 3dac3f22
|
||||||
|
007_convolutional_lrelu: 3d1aad80
|
||||||
|
008_convolutional: 3d02ad5d
|
||||||
|
008_convolutional_bn: 3d3d3011
|
||||||
|
008_convolutional_lrelu: 3ce0b983
|
||||||
|
009_shortcut: 3d65222f
|
||||||
|
010_convolutional: 3e0361c9
|
||||||
|
010_convolutional_bn: 3e02d26d
|
||||||
|
010_convolutional_lrelu: 3d2d7316
|
||||||
|
011_convolutional: 3d627308
|
||||||
|
011_convolutional_bn: 3daebf2f
|
||||||
|
011_convolutional_lrelu: 3d14a813
|
||||||
|
012_shortcut: 3dacd17b
|
||||||
|
013_convolutional: 3e7e41a4
|
||||||
|
013_convolutional_bn: 3d934c2e
|
||||||
|
013_convolutional_lrelu: 3d1b9c4b
|
||||||
|
014_convolutional: 3d328d13
|
||||||
|
014_convolutional_bn: 3d9693da
|
||||||
|
014_convolutional_lrelu: 3d013a50
|
||||||
|
015_convolutional: 3d145f8c
|
||||||
|
015_convolutional_bn: 3d33f221
|
||||||
|
015_convolutional_lrelu: 3c77ff83
|
||||||
|
016_shortcut: 3d223726
|
||||||
|
017_convolutional: 3d79e1d7
|
||||||
|
017_convolutional_bn: 3d910272
|
||||||
|
017_convolutional_lrelu: 3d1818d7
|
||||||
|
018_convolutional: 3d2430e9
|
||||||
|
018_convolutional_bn: 3d179c24
|
||||||
|
018_convolutional_lrelu: 3cb59c76
|
||||||
|
019_shortcut: 3d3fad4e
|
||||||
|
020_convolutional: 3d6aa953
|
||||||
|
020_convolutional_bn: 3d971117
|
||||||
|
020_convolutional_lrelu: 3d0a4a66
|
||||||
|
021_convolutional: 3cf79e4a
|
||||||
|
021_convolutional_bn: 3d51252f
|
||||||
|
021_convolutional_lrelu: 3cb389a7
|
||||||
|
022_shortcut: 3d52790c
|
||||||
|
023_convolutional: 3d488983
|
||||||
|
023_convolutional_bn: 3d816e4c
|
||||||
|
023_convolutional_lrelu: 3d1cd21d
|
||||||
|
024_convolutional: 3d12341b
|
||||||
|
024_convolutional_bn: 3d3ce6f1
|
||||||
|
024_convolutional_lrelu: 3cbdf46e
|
||||||
|
025_shortcut: 3d65ade1
|
||||||
|
026_convolutional: 3d60a84b
|
||||||
|
026_convolutional_bn: 3d93a69c
|
||||||
|
026_convolutional_lrelu: 3d013552
|
||||||
|
027_convolutional: 3cee3507
|
||||||
|
027_convolutional_bn: 3d7180b6
|
||||||
|
027_convolutional_lrelu: 3cef1b2b
|
||||||
|
028_shortcut: 3d89433f
|
||||||
|
029_convolutional: 3d906be3
|
||||||
|
029_convolutional_bn: 3d8c0d4e
|
||||||
|
029_convolutional_lrelu: 3d0547d6
|
||||||
|
030_convolutional: 3cd3c986
|
||||||
|
030_convolutional_bn: 3dce28f8
|
||||||
|
030_convolutional_lrelu: 3d105248
|
||||||
|
031_shortcut: 3d980526
|
||||||
|
032_convolutional: 3d92a4fe
|
||||||
|
032_convolutional_bn: 3d75e748
|
||||||
|
032_convolutional_lrelu: 3cf0bf5e
|
||||||
|
033_convolutional: 3ce85e4c
|
||||||
|
033_convolutional_bn: 3d9fce65
|
||||||
|
033_convolutional_lrelu: 3d07d676
|
||||||
|
034_shortcut: 3da13385
|
||||||
|
035_convolutional: 3dbe8edc
|
||||||
|
035_convolutional_bn: 3d88b896
|
||||||
|
035_convolutional_lrelu: 3ce5aeae
|
||||||
|
036_convolutional: 3cbb48d8
|
||||||
|
036_convolutional_bn: 3da707a0
|
||||||
|
036_convolutional_lrelu: 3d23e7ce
|
||||||
|
037_shortcut: 3d935901
|
||||||
|
038_convolutional: 3e42c771
|
||||||
|
038_convolutional_bn: 3d9cc657
|
||||||
|
038_convolutional_lrelu: 3d052b4a
|
||||||
|
039_convolutional: 3ca36e5c
|
||||||
|
039_convolutional_bn: 3d798f57
|
||||||
|
039_convolutional_lrelu: 3d1a9a24
|
||||||
|
040_convolutional: 3d43e821
|
||||||
|
040_convolutional_bn: 3cf02fb2
|
||||||
|
040_convolutional_lrelu: 3c130957
|
||||||
|
041_shortcut: 3d037bf1
|
||||||
|
042_convolutional: 3cdc8f82
|
||||||
|
042_convolutional_bn: 3d86b281
|
||||||
|
042_convolutional_lrelu: 3d0c3612
|
||||||
|
043_convolutional: 3d110022
|
||||||
|
043_convolutional_bn: 3d2e627a
|
||||||
|
043_convolutional_lrelu: 3c9ca38c
|
||||||
|
044_shortcut: 3d06771f
|
||||||
|
045_convolutional: 3d06694e
|
||||||
|
045_convolutional_bn: 3d642037
|
||||||
|
045_convolutional_lrelu: 3cf20a07
|
||||||
|
046_convolutional: 3ca9f1fa
|
||||||
|
046_convolutional_bn: 3d417080
|
||||||
|
046_convolutional_lrelu: 3c920518
|
||||||
|
047_shortcut: 3d28afee
|
||||||
|
048_convolutional: 3d102eac
|
||||||
|
048_convolutional_bn: 3d685214
|
||||||
|
048_convolutional_lrelu: 3cdff0c6
|
||||||
|
049_convolutional: 3cb63557
|
||||||
|
049_convolutional_bn: 3d442ca2
|
||||||
|
049_convolutional_lrelu: 3ca82011
|
||||||
|
050_shortcut: 3d3162ce
|
||||||
|
051_convolutional: 3d175f15
|
||||||
|
051_convolutional_bn: 3d6b2831
|
||||||
|
051_convolutional_lrelu: 3cc9fd32
|
||||||
|
052_convolutional: 3cb834a6
|
||||||
|
052_convolutional_bn: 3d62567a
|
||||||
|
052_convolutional_lrelu: 3cca7ca7
|
||||||
|
053_shortcut: 3d61f317
|
||||||
|
054_convolutional: 3d3a818c
|
||||||
|
054_convolutional_bn: 3d8014b4
|
||||||
|
054_convolutional_lrelu: 3cb7e663
|
||||||
|
055_convolutional: 3cc295f2
|
||||||
|
055_convolutional_bn: 3d9f39c8
|
||||||
|
055_convolutional_lrelu: 3d058ab9
|
||||||
|
056_shortcut: 3d68d058
|
||||||
|
057_convolutional: 3d3ddc75
|
||||||
|
057_convolutional_bn: 3d6badad
|
||||||
|
057_convolutional_lrelu: 3cddc998
|
||||||
|
058_convolutional: 3c94d95a
|
||||||
|
058_convolutional_bn: 3d81d762
|
||||||
|
058_convolutional_lrelu: 3cfc320c
|
||||||
|
059_shortcut: 3d8b8048
|
||||||
|
060_convolutional: 3d8ae0c9
|
||||||
|
060_convolutional_bn: 3d62b696
|
||||||
|
060_convolutional_lrelu: 3ca0c33d
|
||||||
|
061_convolutional: 3c94812c
|
||||||
|
061_convolutional_bn: 3dbea4bb
|
||||||
|
061_convolutional_lrelu: 3cfeac50
|
||||||
|
062_shortcut: 3d4cad06
|
||||||
|
063_convolutional: 3e0b3199
|
||||||
|
063_convolutional_bn: 3d989a57
|
||||||
|
063_convolutional_lrelu: 3cf7c7b9
|
||||||
|
064_convolutional: 3ca153d8
|
||||||
|
064_convolutional_bn: 3d8c72d2
|
||||||
|
064_convolutional_lrelu: 3d091f48
|
||||||
|
065_convolutional: 3d367976
|
||||||
|
065_convolutional_bn: 3d5db8ab
|
||||||
|
065_convolutional_lrelu: 3c86a0a0
|
||||||
|
066_shortcut: 3cf710fb
|
||||||
|
067_convolutional: 3cca075e
|
||||||
|
067_convolutional_bn: 3d92712b
|
||||||
|
067_convolutional_lrelu: 3c96748b
|
||||||
|
068_convolutional: 3cb833f7
|
||||||
|
068_convolutional_bn: 3d4560cc
|
||||||
|
068_convolutional_lrelu: 3cab9b60
|
||||||
|
069_shortcut: 3cf987de
|
||||||
|
070_convolutional: 3cc1e53d
|
||||||
|
070_convolutional_bn: 3d695425
|
||||||
|
070_convolutional_lrelu: 3ccf51cd
|
||||||
|
071_convolutional: 3cc4349b
|
||||||
|
071_convolutional_bn: 3d49aaa2
|
||||||
|
071_convolutional_lrelu: 3cdc95d3
|
||||||
|
072_shortcut: 3d108112
|
||||||
|
073_convolutional: 3d15383b
|
||||||
|
073_convolutional_bn: 3d8b945b
|
||||||
|
073_convolutional_lrelu: 3c9fa1ee
|
||||||
|
074_convolutional: 3cb27484
|
||||||
|
074_convolutional_bn: 3d95f919
|
||||||
|
074_convolutional_lrelu: 3d0fa80c
|
||||||
|
075_shortcut: 3d4f6671
|
||||||
|
076_convolutional: 3d55c415
|
||||||
|
076_convolutional_bn: 3d90c0ab
|
||||||
|
076_convolutional_lrelu: 3d1481a8
|
||||||
|
077_convolutional: 3dafcaa8
|
||||||
|
077_convolutional_bn: 3d9a1eee
|
||||||
|
077_convolutional_lrelu: 3d0acd89
|
||||||
|
078_convolutional: 3e204e75
|
||||||
|
078_convolutional_bn: 3da289aa
|
||||||
|
078_convolutional_lrelu: 3d143dc3
|
||||||
|
079_maxpool: 3d143dc3
|
||||||
|
081_maxpool: 3d143dc3
|
||||||
|
083_maxpool: 3d143dc3
|
||||||
|
084_route: 3d143dc3
|
||||||
|
085_convolutional: 3d843c75
|
||||||
|
085_convolutional_bn: 3d9a33a2
|
||||||
|
085_convolutional_lrelu: 3d04fc19
|
||||||
|
086_convolutional: 3d7e805b
|
||||||
|
086_convolutional_bn: 3d7404de
|
||||||
|
086_convolutional_lrelu: 3d034c6e
|
||||||
|
087_convolutional: 3d436436
|
||||||
|
087_convolutional_bn: 3d54aef3
|
||||||
|
087_convolutional_lrelu: 3d015c07
|
||||||
|
088_convolutional: 3d7ed7d7
|
||||||
|
088_convolutional_bn: 3d8b5c9d
|
||||||
|
088_convolutional_lrelu: 3d1e87df
|
||||||
|
089_convolutional: 3e5e639a
|
||||||
|
092_convolutional: 3d4060ca
|
||||||
|
092_convolutional_bn: 3d8f5a9e
|
||||||
|
092_convolutional_lrelu: 3d2d5cac
|
||||||
|
093_upsample: 3d4cad06
|
||||||
|
094_route: 3d4cad06
|
||||||
|
095_convolutional: 3dcc68f9
|
||||||
|
095_convolutional_bn: 3d8521b9
|
||||||
|
095_convolutional_lrelu: 3d289238
|
||||||
|
096_convolutional: 3da93126
|
||||||
|
096_convolutional_bn: 3d87f05f
|
||||||
|
096_convolutional_lrelu: 3d182fbf
|
||||||
|
097_convolutional: 3d44121b
|
||||||
|
097_convolutional_bn: 3d839409
|
||||||
|
097_convolutional_lrelu: 3cdb454d
|
||||||
|
098_convolutional: 3d85bd57
|
||||||
|
098_convolutional_bn: 3d7da065
|
||||||
|
098_convolutional_lrelu: 3d04eaf6
|
||||||
|
099_convolutional: 3d5ccbb9
|
||||||
|
099_convolutional_bn: 3d773490
|
||||||
|
099_convolutional_lrelu: 3cd708ff
|
||||||
|
100_convolutional: 3d6feaea
|
||||||
|
100_convolutional_bn: 3d882839
|
||||||
|
100_convolutional_lrelu: 3d2e3ea8
|
||||||
|
101_convolutional: 3e45b03a
|
||||||
|
104_convolutional: 3d2f9c83
|
||||||
|
104_convolutional_bn: 3dba946d
|
||||||
|
104_convolutional_lrelu: 3d69e03b
|
||||||
|
105_upsample: 3d935901
|
||||||
|
106_route: 3d935901
|
||||||
|
107_convolutional: 3e161afe
|
||||||
|
107_convolutional_bn: 3d84f142
|
||||||
|
107_convolutional_lrelu: 3d0e35d7
|
||||||
|
108_convolutional: 3dc362e6
|
||||||
|
108_convolutional_bn: 3d7555e5
|
||||||
|
108_convolutional_lrelu: 3d00c803
|
||||||
|
109_convolutional: 3d4f4d7f
|
||||||
|
109_convolutional_bn: 3d86c3ff
|
||||||
|
109_convolutional_lrelu: 3d194172
|
||||||
|
110_convolutional: 3db35943
|
||||||
|
110_convolutional_bn: 3d7b99e9
|
||||||
|
110_convolutional_lrelu: 3d077a43
|
||||||
|
111_convolutional: 3dbfbfd5
|
||||||
|
111_convolutional_bn: 3d8f0c83
|
||||||
|
111_convolutional_lrelu: 3d180439
|
||||||
|
112_convolutional: 3de396c9
|
||||||
|
112_convolutional_bn: 3d9cc189
|
||||||
|
112_convolutional_lrelu: 3d471581
|
||||||
|
113_convolutional: 3e5c717d
|
||||||
|
(Unnamed Layer* 253) [PluginV2IOExt]_output_0: 3ef23e7d
|
||||||
|
(Unnamed Layer* 254) [PluginV2IOExt]_output_0: 3ee20891
|
||||||
|
(Unnamed Layer* 255) [PluginV2IOExt]_output_0: 3de21d3a
|
||||||
|
|
@ -0,0 +1,47 @@
|
||||||
|
TRT-7103-EntropyCalibration2
|
||||||
|
000_net: 3c010a14
|
||||||
|
001_convolutional: 3d77cc4d
|
||||||
|
001_convolutional_bn: 3eb97554
|
||||||
|
001_convolutional_lrelu: 3e3cfaf6
|
||||||
|
002_maxpool: 3e3cfaf6
|
||||||
|
003_convolutional: 3fd20362
|
||||||
|
003_convolutional_bn: 3f05ab3e
|
||||||
|
003_convolutional_lrelu: 3dba5110
|
||||||
|
004_maxpool: 3dba5110
|
||||||
|
005_convolutional: 3f0ff935
|
||||||
|
005_convolutional_bn: 3e98332b
|
||||||
|
005_convolutional_lrelu: 3dc89fbc
|
||||||
|
006_maxpool: 3dc89fbc
|
||||||
|
007_convolutional: 3f13aa2f
|
||||||
|
007_convolutional_bn: 3e6a8bc5
|
||||||
|
007_convolutional_lrelu: 3daf3f0b
|
||||||
|
008_maxpool: 3daf3f0b
|
||||||
|
009_convolutional: 3e9a71e8
|
||||||
|
009_convolutional_bn: 3e277a8e
|
||||||
|
009_convolutional_lrelu: 3d8e5618
|
||||||
|
010_maxpool: 3d8b6f69
|
||||||
|
011_convolutional: 3e32c610
|
||||||
|
011_convolutional_bn: 3e0d719f
|
||||||
|
011_convolutional_lrelu: 3d3e0683
|
||||||
|
012_maxpool: 3d3e0683
|
||||||
|
013_convolutional: 3dc55cef
|
||||||
|
013_convolutional_bn: 3ec090b7
|
||||||
|
013_convolutional_lrelu: 3e1a4216
|
||||||
|
014_convolutional: 3e5f4d5c
|
||||||
|
014_convolutional_bn: 3d86be13
|
||||||
|
014_convolutional_lrelu: 3cff8f32
|
||||||
|
015_convolutional: 3d7e0dfb
|
||||||
|
015_convolutional_bn: 3dc57801
|
||||||
|
015_convolutional_lrelu: 3d5eb027
|
||||||
|
016_convolutional: 3e535004
|
||||||
|
019_convolutional: 3d28d5ce
|
||||||
|
019_convolutional_bn: 3dad20cf
|
||||||
|
019_convolutional_lrelu: 3d6086c9
|
||||||
|
020_upsample: 3d8e5618
|
||||||
|
021_route: 3d8e5618
|
||||||
|
022_convolutional: 3e3be517
|
||||||
|
022_convolutional_bn: 3db901c1
|
||||||
|
022_convolutional_lrelu: 3d58aa42
|
||||||
|
023_convolutional: 3e46f24e
|
||||||
|
(Unnamed Layer* 43) [PluginV2IOExt]_output_0: 3efa468d
|
||||||
|
(Unnamed Layer* 44) [PluginV2IOExt]_output_0: 3ee1f1e4
|
||||||
|
|
@ -0,0 +1,511 @@
|
||||||
|
TRT-7103-EntropyCalibration2
|
||||||
|
000_net: 3c010a14
|
||||||
|
001_convolutional: 3da6aff8
|
||||||
|
001_convolutional_bn: 3ea6a387
|
||||||
|
001_convolutional_softplus: 3e296d45
|
||||||
|
001_convolutional_tanh: 3c010a14
|
||||||
|
001_convolutional_mish: 3e17fbd6
|
||||||
|
002_convolutional: 3fb53648
|
||||||
|
002_convolutional_bn: 3e9383f9
|
||||||
|
002_convolutional_softplus: 3e2640de
|
||||||
|
002_convolutional_tanh: 3c010a14
|
||||||
|
002_convolutional_mish: 3e8d7fc8
|
||||||
|
003_convolutional: 3f1d0b4c
|
||||||
|
003_convolutional_bn: 3e569c6c
|
||||||
|
003_convolutional_softplus: 3de204c4
|
||||||
|
003_convolutional_tanh: 3c010a14
|
||||||
|
003_convolutional_mish: 3d8f6f42
|
||||||
|
005_convolutional: 3f12c8ba
|
||||||
|
005_convolutional_bn: 3e0d00c7
|
||||||
|
005_convolutional_softplus: 3dba9b4b
|
||||||
|
005_convolutional_tanh: 3c010a14
|
||||||
|
005_convolutional_mish: 3dab1388
|
||||||
|
006_convolutional: 3e938548
|
||||||
|
006_convolutional_bn: 3e6d6234
|
||||||
|
006_convolutional_softplus: 3e3874f1
|
||||||
|
006_convolutional_tanh: 3c010a14
|
||||||
|
006_convolutional_mish: 3dddcb43
|
||||||
|
007_convolutional: 3f2a4aa7
|
||||||
|
007_convolutional_bn: 3e5384a9
|
||||||
|
007_convolutional_softplus: 3df5c8f6
|
||||||
|
007_convolutional_tanh: 3c010a14
|
||||||
|
007_convolutional_mish: 3dda4c4a
|
||||||
|
008_shortcut: 3e528e26
|
||||||
|
009_convolutional: 3f01ddd0
|
||||||
|
009_convolutional_bn: 3e58618d
|
||||||
|
009_convolutional_softplus: 3de09ee4
|
||||||
|
009_convolutional_tanh: 3c010a14
|
||||||
|
009_convolutional_mish: 3d8f6f42
|
||||||
|
010_route: 3d8f6f42
|
||||||
|
011_convolutional: 3eef7ec3
|
||||||
|
011_convolutional_bn: 3e3cc2f2
|
||||||
|
011_convolutional_softplus: 3ddecbd2
|
||||||
|
011_convolutional_tanh: 3c010a14
|
||||||
|
011_convolutional_mish: 3da723ff
|
||||||
|
012_convolutional: 3f8e6c14
|
||||||
|
012_convolutional_bn: 3e175ef7
|
||||||
|
012_convolutional_softplus: 3db368a7
|
||||||
|
012_convolutional_tanh: 3c010a14
|
||||||
|
012_convolutional_mish: 3da47a3e
|
||||||
|
013_convolutional: 3ec71022
|
||||||
|
013_convolutional_bn: 3df7f8cd
|
||||||
|
013_convolutional_softplus: 3db10627
|
||||||
|
013_convolutional_tanh: 3c010a14
|
||||||
|
013_convolutional_mish: 3da03ba8
|
||||||
|
015_convolutional: 3ea96d61
|
||||||
|
015_convolutional_bn: 3d9d8cdd
|
||||||
|
015_convolutional_softplus: 3d8abb2d
|
||||||
|
015_convolutional_tanh: 3c021427
|
||||||
|
015_convolutional_mish: 3d804d31
|
||||||
|
016_convolutional: 3e318b56
|
||||||
|
016_convolutional_bn: 3da302a3
|
||||||
|
016_convolutional_softplus: 3d902621
|
||||||
|
016_convolutional_tanh: 3c01f3e7
|
||||||
|
016_convolutional_mish: 3d9e63bb
|
||||||
|
017_convolutional: 3e863e49
|
||||||
|
017_convolutional_bn: 3dbdb322
|
||||||
|
017_convolutional_softplus: 3d9893cf
|
||||||
|
017_convolutional_tanh: 3c021427
|
||||||
|
017_convolutional_mish: 3d392afd
|
||||||
|
018_shortcut: 3dd31aa3
|
||||||
|
019_convolutional: 3e4cac42
|
||||||
|
019_convolutional_bn: 3d9b0161
|
||||||
|
019_convolutional_softplus: 3d5f678f
|
||||||
|
019_convolutional_tanh: 3c061c33
|
||||||
|
019_convolutional_mish: 3d55644e
|
||||||
|
020_convolutional: 3e8c293c
|
||||||
|
020_convolutional_bn: 3e1c4b6a
|
||||||
|
020_convolutional_softplus: 3da6a2dd
|
||||||
|
020_convolutional_tanh: 3c010a14
|
||||||
|
020_convolutional_mish: 3da6a2dd
|
||||||
|
021_shortcut: 3e1adb45
|
||||||
|
022_convolutional: 3ed98343
|
||||||
|
022_convolutional_bn: 3e0a40cc
|
||||||
|
022_convolutional_softplus: 3db71b3f
|
||||||
|
022_convolutional_tanh: 3c010a14
|
||||||
|
022_convolutional_mish: 3da03ba8
|
||||||
|
023_route: 3da03ba8
|
||||||
|
024_convolutional: 3ee448cf
|
||||||
|
024_convolutional_bn: 3e1e7ef8
|
||||||
|
024_convolutional_softplus: 3d7bb1f9
|
||||||
|
024_convolutional_tanh: 3c010a14
|
||||||
|
024_convolutional_mish: 3d8607b8
|
||||||
|
025_convolutional: 3f08c3e7
|
||||||
|
025_convolutional_bn: 3df97e0e
|
||||||
|
025_convolutional_softplus: 3d97ba96
|
||||||
|
025_convolutional_tanh: 3c010a14
|
||||||
|
025_convolutional_mish: 3d38c530
|
||||||
|
026_convolutional: 3e8d62f0
|
||||||
|
026_convolutional_bn: 3dedaad6
|
||||||
|
026_convolutional_softplus: 3d93e66e
|
||||||
|
026_convolutional_tanh: 3c021427
|
||||||
|
026_convolutional_mish: 3d83b0d4
|
||||||
|
028_convolutional: 3e8973a3
|
||||||
|
028_convolutional_bn: 3dba83a4
|
||||||
|
028_convolutional_softplus: 3d994c28
|
||||||
|
028_convolutional_tanh: 3c010a14
|
||||||
|
028_convolutional_mish: 3d8240d3
|
||||||
|
029_convolutional: 3e21d9ce
|
||||||
|
029_convolutional_bn: 3dbe8121
|
||||||
|
029_convolutional_softplus: 3d717a22
|
||||||
|
029_convolutional_tanh: 3c010a14
|
||||||
|
029_convolutional_mish: 3d1141b8
|
||||||
|
030_convolutional: 3e9586c8
|
||||||
|
030_convolutional_bn: 3daf7179
|
||||||
|
030_convolutional_softplus: 3d4e4250
|
||||||
|
030_convolutional_tanh: 3c021427
|
||||||
|
030_convolutional_mish: 3d235725
|
||||||
|
031_shortcut: 3db5fe0f
|
||||||
|
032_convolutional: 3e4179ab
|
||||||
|
032_convolutional_bn: 3dc46552
|
||||||
|
032_convolutional_softplus: 3d78390e
|
||||||
|
032_convolutional_tanh: 3c01121e
|
||||||
|
032_convolutional_mish: 3d24ec37
|
||||||
|
033_convolutional: 3e43846b
|
||||||
|
033_convolutional_bn: 3dd3beb8
|
||||||
|
033_convolutional_softplus: 3d5bfe3f
|
||||||
|
033_convolutional_tanh: 3c03162a
|
||||||
|
033_convolutional_mish: 3d107ef6
|
||||||
|
034_shortcut: 3dbe8cd4
|
||||||
|
035_convolutional: 3e706786
|
||||||
|
035_convolutional_bn: 3e08b8e1
|
||||||
|
035_convolutional_softplus: 3d690deb
|
||||||
|
035_convolutional_tanh: 3c02141c
|
||||||
|
035_convolutional_mish: 3d24584c
|
||||||
|
036_convolutional: 3e30ec80
|
||||||
|
036_convolutional_bn: 3dc29a0a
|
||||||
|
036_convolutional_softplus: 3d5ee2b8
|
||||||
|
036_convolutional_tanh: 3c02141f
|
||||||
|
036_convolutional_mish: 3cd5180c
|
||||||
|
037_shortcut: 3dfa1fdd
|
||||||
|
038_convolutional: 3ea10c50
|
||||||
|
038_convolutional_bn: 3e12447d
|
||||||
|
038_convolutional_softplus: 3d5a0570
|
||||||
|
038_convolutional_tanh: 3c011223
|
||||||
|
038_convolutional_mish: 3d02a407
|
||||||
|
039_convolutional: 3e5baa4a
|
||||||
|
039_convolutional_bn: 3e065b91
|
||||||
|
039_convolutional_softplus: 3dcd6135
|
||||||
|
039_convolutional_tanh: 3c010a14
|
||||||
|
039_convolutional_mish: 3d15f581
|
||||||
|
040_shortcut: 3e26c262
|
||||||
|
041_convolutional: 3e8d42dc
|
||||||
|
041_convolutional_bn: 3ddb7633
|
||||||
|
041_convolutional_softplus: 3d4a02f0
|
||||||
|
041_convolutional_tanh: 3c0111e6
|
||||||
|
041_convolutional_mish: 3d119983
|
||||||
|
042_convolutional: 3dffd3ad
|
||||||
|
042_convolutional_bn: 3db72fe8
|
||||||
|
042_convolutional_softplus: 3d7bc282
|
||||||
|
042_convolutional_tanh: 3c021427
|
||||||
|
042_convolutional_mish: 3d38f535
|
||||||
|
043_shortcut: 3e253907
|
||||||
|
044_convolutional: 3ea7c803
|
||||||
|
044_convolutional_bn: 3dd24023
|
||||||
|
044_convolutional_softplus: 3d2ee27e
|
||||||
|
044_convolutional_tanh: 3c011209
|
||||||
|
044_convolutional_mish: 3cc691eb
|
||||||
|
045_convolutional: 3df677c6
|
||||||
|
045_convolutional_bn: 3df0ab1f
|
||||||
|
045_convolutional_softplus: 3d8ab5cf
|
||||||
|
045_convolutional_tanh: 3c010a14
|
||||||
|
045_convolutional_mish: 3d21fa8d
|
||||||
|
046_shortcut: 3e2b4214
|
||||||
|
047_convolutional: 3e9bf0c3
|
||||||
|
047_convolutional_bn: 3dc24ce9
|
||||||
|
047_convolutional_softplus: 3d48ddaf
|
||||||
|
047_convolutional_tanh: 3c011222
|
||||||
|
047_convolutional_mish: 3cec277c
|
||||||
|
048_convolutional: 3e067637
|
||||||
|
048_convolutional_bn: 3e175474
|
||||||
|
048_convolutional_softplus: 3db71eb1
|
||||||
|
048_convolutional_tanh: 3c010a14
|
||||||
|
048_convolutional_mish: 3da7e136
|
||||||
|
049_shortcut: 3e5afcbe
|
||||||
|
050_convolutional: 3ed4a1e6
|
||||||
|
050_convolutional_bn: 3dea922f
|
||||||
|
050_convolutional_softplus: 3d29bb2b
|
||||||
|
050_convolutional_tanh: 3c010a14
|
||||||
|
050_convolutional_mish: 3d0e1420
|
||||||
|
051_convolutional: 3e0be5b5
|
||||||
|
051_convolutional_bn: 3e187487
|
||||||
|
051_convolutional_softplus: 3dba801d
|
||||||
|
051_convolutional_tanh: 3c010a14
|
||||||
|
051_convolutional_mish: 3daafa9d
|
||||||
|
052_shortcut: 3e786f2a
|
||||||
|
053_convolutional: 3f251892
|
||||||
|
053_convolutional_bn: 3df5ec06
|
||||||
|
053_convolutional_softplus: 3dad6084
|
||||||
|
053_convolutional_tanh: 3c010a14
|
||||||
|
053_convolutional_mish: 3d83b0d4
|
||||||
|
054_route: 3d83b0d4
|
||||||
|
055_convolutional: 3e97dd13
|
||||||
|
055_convolutional_bn: 3e1ea207
|
||||||
|
055_convolutional_softplus: 3d4dc4f2
|
||||||
|
055_convolutional_tanh: 3c010a14
|
||||||
|
055_convolutional_mish: 3d39f7e7
|
||||||
|
056_convolutional: 3eb1fce8
|
||||||
|
056_convolutional_bn: 3dd683d4
|
||||||
|
056_convolutional_softplus: 3d8c3215
|
||||||
|
056_convolutional_tanh: 3c010a14
|
||||||
|
056_convolutional_mish: 3d0e6272
|
||||||
|
057_convolutional: 3e1c7a19
|
||||||
|
057_convolutional_bn: 3db82deb
|
||||||
|
057_convolutional_softplus: 3d7d9903
|
||||||
|
057_convolutional_tanh: 3c010a14
|
||||||
|
057_convolutional_mish: 3d160c32
|
||||||
|
059_convolutional: 3e506407
|
||||||
|
059_convolutional_bn: 3d9f9d99
|
||||||
|
059_convolutional_softplus: 3d7c9682
|
||||||
|
059_convolutional_tanh: 3c021411
|
||||||
|
059_convolutional_mish: 3d3af590
|
||||||
|
060_convolutional: 3db81469
|
||||||
|
060_convolutional_bn: 3db931a1
|
||||||
|
060_convolutional_softplus: 3d93914f
|
||||||
|
060_convolutional_tanh: 3c021427
|
||||||
|
060_convolutional_mish: 3d017403
|
||||||
|
061_convolutional: 3ebd1ec2
|
||||||
|
061_convolutional_bn: 3da85604
|
||||||
|
061_convolutional_softplus: 3d5dbe02
|
||||||
|
061_convolutional_tanh: 3c03161e
|
||||||
|
061_convolutional_mish: 3d226600
|
||||||
|
062_shortcut: 3d8e58d4
|
||||||
|
063_convolutional: 3dad8279
|
||||||
|
063_convolutional_bn: 3da76549
|
||||||
|
063_convolutional_softplus: 3d512597
|
||||||
|
063_convolutional_tanh: 3c011223
|
||||||
|
063_convolutional_mish: 3d25a0b9
|
||||||
|
064_convolutional: 3e175192
|
||||||
|
064_convolutional_bn: 3db03377
|
||||||
|
064_convolutional_softplus: 3d35ed9a
|
||||||
|
064_convolutional_tanh: 3c01114d
|
||||||
|
064_convolutional_mish: 3caf9999
|
||||||
|
065_shortcut: 3d7f109e
|
||||||
|
066_convolutional: 3e01908b
|
||||||
|
066_convolutional_bn: 3dc251b0
|
||||||
|
066_convolutional_softplus: 3d552ea7
|
||||||
|
066_convolutional_tanh: 3c0111fe
|
||||||
|
066_convolutional_mish: 3d11918e
|
||||||
|
067_convolutional: 3de36fdb
|
||||||
|
067_convolutional_bn: 3dab86db
|
||||||
|
067_convolutional_softplus: 3d347d29
|
||||||
|
067_convolutional_tanh: 3c011138
|
||||||
|
067_convolutional_mish: 3d02bdc7
|
||||||
|
068_shortcut: 3db379aa
|
||||||
|
069_convolutional: 3e06e991
|
||||||
|
069_convolutional_bn: 3e031644
|
||||||
|
069_convolutional_softplus: 3d3123db
|
||||||
|
069_convolutional_tanh: 3c011204
|
||||||
|
069_convolutional_mish: 3cc4695a
|
||||||
|
070_convolutional: 3e082370
|
||||||
|
070_convolutional_bn: 3df795f0
|
||||||
|
070_convolutional_softplus: 3d74e50b
|
||||||
|
070_convolutional_tanh: 3c031628
|
||||||
|
070_convolutional_mish: 3d5dc953
|
||||||
|
071_shortcut: 3dc06bd4
|
||||||
|
072_convolutional: 3e0f9dde
|
||||||
|
072_convolutional_bn: 3db1944b
|
||||||
|
072_convolutional_softplus: 3d4aaf62
|
||||||
|
072_convolutional_tanh: 3c0111dc
|
||||||
|
072_convolutional_mish: 3d0fd5ed
|
||||||
|
073_convolutional: 3dc66a6a
|
||||||
|
073_convolutional_bn: 3dccd1c3
|
||||||
|
073_convolutional_softplus: 3d834750
|
||||||
|
073_convolutional_tanh: 3c0213fc
|
||||||
|
073_convolutional_mish: 3d0fe4cb
|
||||||
|
074_shortcut: 3dcfbd61
|
||||||
|
075_convolutional: 3e15e4c1
|
||||||
|
075_convolutional_bn: 3db3383a
|
||||||
|
075_convolutional_softplus: 3d2b90b3
|
||||||
|
075_convolutional_tanh: 3c02113a
|
||||||
|
075_convolutional_mish: 3ceb5f10
|
||||||
|
076_convolutional: 3db6ba74
|
||||||
|
076_convolutional_bn: 3dd2e09e
|
||||||
|
076_convolutional_softplus: 3d741c69
|
||||||
|
076_convolutional_tanh: 3c010a14
|
||||||
|
076_convolutional_mish: 3d58cf6e
|
||||||
|
077_shortcut: 3dff3205
|
||||||
|
078_convolutional: 3e424805
|
||||||
|
078_convolutional_bn: 3db97a3c
|
||||||
|
078_convolutional_softplus: 3d2c6de4
|
||||||
|
078_convolutional_tanh: 3c010fa6
|
||||||
|
078_convolutional_mish: 3d0332bf
|
||||||
|
079_convolutional: 3dc29c00
|
||||||
|
079_convolutional_bn: 3debf2e9
|
||||||
|
079_convolutional_softplus: 3d707c08
|
||||||
|
079_convolutional_tanh: 3c010a14
|
||||||
|
079_convolutional_mish: 3d0e49e1
|
||||||
|
080_shortcut: 3e1abc32
|
||||||
|
081_convolutional: 3e6626a4
|
||||||
|
081_convolutional_bn: 3db644c5
|
||||||
|
081_convolutional_softplus: 3d1d1ed9
|
||||||
|
081_convolutional_tanh: 3c011197
|
||||||
|
081_convolutional_mish: 3cafa27f
|
||||||
|
082_convolutional: 3daec08c
|
||||||
|
082_convolutional_bn: 3e09a51a
|
||||||
|
082_convolutional_softplus: 3d915698
|
||||||
|
082_convolutional_tanh: 3c010a14
|
||||||
|
082_convolutional_mish: 3d8782a8
|
||||||
|
083_shortcut: 3e382b5d
|
||||||
|
084_convolutional: 3ec83556
|
||||||
|
084_convolutional_bn: 3dcdf03d
|
||||||
|
084_convolutional_softplus: 3d827ec2
|
||||||
|
084_convolutional_tanh: 3c021426
|
||||||
|
084_convolutional_mish: 3d160c32
|
||||||
|
085_route: 3d160c32
|
||||||
|
086_convolutional: 3e459e81
|
||||||
|
086_convolutional_bn: 3e135046
|
||||||
|
086_convolutional_softplus: 3d4a0725
|
||||||
|
086_convolutional_tanh: 3c010a14
|
||||||
|
086_convolutional_mish: 3d3b1017
|
||||||
|
087_convolutional: 3e598534
|
||||||
|
087_convolutional_bn: 3db52443
|
||||||
|
087_convolutional_softplus: 3d205b0d
|
||||||
|
087_convolutional_tanh: 3c010a14
|
||||||
|
087_convolutional_mish: 3d0e39a0
|
||||||
|
088_convolutional: 3da5c757
|
||||||
|
088_convolutional_bn: 3e0a0194
|
||||||
|
088_convolutional_softplus: 3d05a7db
|
||||||
|
088_convolutional_tanh: 3c010a14
|
||||||
|
088_convolutional_mish: 3d24e64e
|
||||||
|
090_convolutional: 3d8d17c5
|
||||||
|
090_convolutional_bn: 3da38f3a
|
||||||
|
090_convolutional_softplus: 3d4f2686
|
||||||
|
090_convolutional_tanh: 3c011223
|
||||||
|
090_convolutional_mish: 3cc704b3
|
||||||
|
091_convolutional: 3d28f40b
|
||||||
|
091_convolutional_bn: 3db158be
|
||||||
|
091_convolutional_softplus: 3d318655
|
||||||
|
091_convolutional_tanh: 3c010a14
|
||||||
|
091_convolutional_mish: 3d1fbc8b
|
||||||
|
092_convolutional: 3ea03076
|
||||||
|
092_convolutional_bn: 3dd7e12b
|
||||||
|
092_convolutional_softplus: 3d22360e
|
||||||
|
092_convolutional_tanh: 3c010f4a
|
||||||
|
092_convolutional_mish: 3cc77029
|
||||||
|
093_shortcut: 3d0712ee
|
||||||
|
094_convolutional: 3d67e7c1
|
||||||
|
094_convolutional_bn: 3ddd0718
|
||||||
|
094_convolutional_softplus: 3d2e4ee2
|
||||||
|
094_convolutional_tanh: 3c010a14
|
||||||
|
094_convolutional_mish: 3ced2ad6
|
||||||
|
095_convolutional: 3db228a1
|
||||||
|
095_convolutional_bn: 3e00baba
|
||||||
|
095_convolutional_softplus: 3d145200
|
||||||
|
095_convolutional_tanh: 3c0111d3
|
||||||
|
095_convolutional_mish: 3cb729c8
|
||||||
|
096_shortcut: 3d2e3725
|
||||||
|
097_convolutional: 3d94712a
|
||||||
|
097_convolutional_bn: 3dc951ef
|
||||||
|
097_convolutional_softplus: 3d34fad3
|
||||||
|
097_convolutional_tanh: 3c01121e
|
||||||
|
097_convolutional_mish: 3ca623ee
|
||||||
|
098_convolutional: 3dc946d4
|
||||||
|
098_convolutional_bn: 3e08652f
|
||||||
|
098_convolutional_softplus: 3d51ba2d
|
||||||
|
098_convolutional_tanh: 3c0315fb
|
||||||
|
098_convolutional_mish: 3cc6364b
|
||||||
|
099_shortcut: 3d65c687
|
||||||
|
100_convolutional: 3d9368a5
|
||||||
|
100_convolutional_bn: 3d9fe445
|
||||||
|
100_convolutional_softplus: 3d067d20
|
||||||
|
100_convolutional_tanh: 3c011126
|
||||||
|
100_convolutional_mish: 3cd85a6d
|
||||||
|
101_convolutional: 3dbe050e
|
||||||
|
101_convolutional_bn: 3dc5c1cc
|
||||||
|
101_convolutional_softplus: 3d7c1e4d
|
||||||
|
101_convolutional_tanh: 3c031629
|
||||||
|
101_convolutional_mish: 3d12d5fd
|
||||||
|
102_shortcut: 3d835161
|
||||||
|
103_convolutional: 3e1a388d
|
||||||
|
103_convolutional_bn: 3dcff4e9
|
||||||
|
103_convolutional_softplus: 3cef7e61
|
||||||
|
103_convolutional_tanh: 3c0111ac
|
||||||
|
103_convolutional_mish: 3d24e64e
|
||||||
|
104_route: 3d24e64e
|
||||||
|
105_convolutional: 3d378b5b
|
||||||
|
105_convolutional_bn: 3dde51b2
|
||||||
|
105_convolutional_softplus: 3d4f5d5c
|
||||||
|
105_convolutional_tanh: 3c021427
|
||||||
|
105_convolutional_mish: 3d11e14d
|
||||||
|
106_convolutional: 3dd1ccd1
|
||||||
|
106_convolutional_bn: 3db4909b
|
||||||
|
106_convolutional_lrelu: 3d3e9554
|
||||||
|
107_convolutional: 3e6bbcf6
|
||||||
|
107_convolutional_bn: 3d62fae8
|
||||||
|
107_convolutional_lrelu: 3d098c08
|
||||||
|
108_convolutional: 3e57167e
|
||||||
|
108_convolutional_bn: 3d69182f
|
||||||
|
108_convolutional_lrelu: 3d6315b8
|
||||||
|
109_maxpool: 3d6315b8
|
||||||
|
111_maxpool: 3d6315b8
|
||||||
|
113_maxpool: 3d6315b8
|
||||||
|
114_route: 3d6315b8
|
||||||
|
115_convolutional: 3e975b6c
|
||||||
|
115_convolutional_bn: 3e3ffa3e
|
||||||
|
115_convolutional_lrelu: 3d478d26
|
||||||
|
116_convolutional: 3e96cfcf
|
||||||
|
116_convolutional_bn: 3e1f5386
|
||||||
|
116_convolutional_lrelu: 3d2c2404
|
||||||
|
117_convolutional: 3e013937
|
||||||
|
117_convolutional_bn: 3dafc777
|
||||||
|
117_convolutional_lrelu: 3d406a0c
|
||||||
|
118_convolutional: 3e2472be
|
||||||
|
118_convolutional_bn: 3db75685
|
||||||
|
118_convolutional_lrelu: 3d61eb07
|
||||||
|
119_upsample: 3d8b686d
|
||||||
|
121_convolutional: 3dd3583e
|
||||||
|
121_convolutional_bn: 3df79627
|
||||||
|
121_convolutional_lrelu: 3d8b686d
|
||||||
|
122_route: 3d8b686d
|
||||||
|
123_convolutional: 3e78551f
|
||||||
|
123_convolutional_bn: 3e06f23b
|
||||||
|
123_convolutional_lrelu: 3d9afbda
|
||||||
|
124_convolutional: 3ec91fd2
|
||||||
|
124_convolutional_bn: 3dddea03
|
||||||
|
124_convolutional_lrelu: 3d7a7f34
|
||||||
|
125_convolutional: 3e357062
|
||||||
|
125_convolutional_bn: 3e105b62
|
||||||
|
125_convolutional_lrelu: 3d963d9e
|
||||||
|
126_convolutional: 3e9e68d8
|
||||||
|
126_convolutional_bn: 3dec07b5
|
||||||
|
126_convolutional_lrelu: 3d6f86d8
|
||||||
|
127_convolutional: 3e4ab9ce
|
||||||
|
127_convolutional_bn: 3df50bd8
|
||||||
|
127_convolutional_lrelu: 3d5df499
|
||||||
|
128_convolutional: 3e482c42
|
||||||
|
128_convolutional_bn: 3e1f8984
|
||||||
|
128_convolutional_lrelu: 3d9f61bf
|
||||||
|
129_upsample: 3da79f33
|
||||||
|
131_convolutional: 3dfe1df4
|
||||||
|
131_convolutional_bn: 3e04dae5
|
||||||
|
131_convolutional_lrelu: 3da79f33
|
||||||
|
132_route: 3da79f33
|
||||||
|
133_convolutional: 3ed4232f
|
||||||
|
133_convolutional_bn: 3e2a99f8
|
||||||
|
133_convolutional_lrelu: 3da4d9f2
|
||||||
|
134_convolutional: 3f0cba6a
|
||||||
|
134_convolutional_bn: 3e1fb5d2
|
||||||
|
134_convolutional_lrelu: 3d824bb3
|
||||||
|
135_convolutional: 3e8553b8
|
||||||
|
135_convolutional_bn: 3e31fd22
|
||||||
|
135_convolutional_lrelu: 3dc32006
|
||||||
|
136_convolutional: 3f16c6d8
|
||||||
|
136_convolutional_bn: 3df91ca0
|
||||||
|
136_convolutional_lrelu: 3dcbe87c
|
||||||
|
137_convolutional: 3ecf149b
|
||||||
|
137_convolutional_bn: 3e940813
|
||||||
|
137_convolutional_lrelu: 3daff33e
|
||||||
|
138_convolutional: 400b24ac
|
||||||
|
138_convolutional_bn: 3ded9b06
|
||||||
|
138_convolutional_lrelu: 3d9285a1
|
||||||
|
139_convolutional: 3eb67f3d
|
||||||
|
142_convolutional: 3eec4444
|
||||||
|
142_convolutional_bn: 3e064b3d
|
||||||
|
142_convolutional_lrelu: 3d5df499
|
||||||
|
143_route: 3d5df499
|
||||||
|
144_convolutional: 3e3782d6
|
||||||
|
144_convolutional_bn: 3dff93f4
|
||||||
|
144_convolutional_lrelu: 3d73aced
|
||||||
|
145_convolutional: 3ea2181a
|
||||||
|
145_convolutional_bn: 3dcc7e51
|
||||||
|
145_convolutional_lrelu: 3d3d80cb
|
||||||
|
146_convolutional: 3e339dcd
|
||||||
|
146_convolutional_bn: 3df741c2
|
||||||
|
146_convolutional_lrelu: 3da73e4f
|
||||||
|
147_convolutional: 3ec12716
|
||||||
|
147_convolutional_bn: 3dd63716
|
||||||
|
147_convolutional_lrelu: 3d348d02
|
||||||
|
148_convolutional: 3e5ee5c5
|
||||||
|
148_convolutional_bn: 3e407ba6
|
||||||
|
148_convolutional_lrelu: 3dc105c4
|
||||||
|
149_convolutional: 3f42a297
|
||||||
|
149_convolutional_bn: 3dc6953f
|
||||||
|
149_convolutional_lrelu: 3d2a1cb0
|
||||||
|
150_convolutional: 3eab8522
|
||||||
|
153_convolutional: 3e35e087
|
||||||
|
153_convolutional_bn: 3dc8f32d
|
||||||
|
153_convolutional_lrelu: 3d406a0c
|
||||||
|
154_route: 3d406a0c
|
||||||
|
155_convolutional: 3dcc13cd
|
||||||
|
155_convolutional_bn: 3d9bbd98
|
||||||
|
155_convolutional_lrelu: 3d0ae902
|
||||||
|
156_convolutional: 3ddb1c39
|
||||||
|
156_convolutional_bn: 3d82d2fd
|
||||||
|
156_convolutional_lrelu: 3cf31a37
|
||||||
|
157_convolutional: 3d7bd773
|
||||||
|
157_convolutional_bn: 3d998229
|
||||||
|
157_convolutional_lrelu: 3d0e6b9c
|
||||||
|
158_convolutional: 3dd09e57
|
||||||
|
158_convolutional_bn: 3d95eb83
|
||||||
|
158_convolutional_lrelu: 3cd82f0a
|
||||||
|
159_convolutional: 3d97cd8f
|
||||||
|
159_convolutional_bn: 3dcdaf39
|
||||||
|
159_convolutional_lrelu: 3d173dbd
|
||||||
|
160_convolutional: 3e5f62f2
|
||||||
|
160_convolutional_bn: 3d8dedb4
|
||||||
|
160_convolutional_lrelu: 3d2ee001
|
||||||
|
161_convolutional: 3e63c8d9
|
||||||
|
(Unnamed Layer* 506) [PluginV2IOExt]_output_0: 4016060c
|
||||||
|
(Unnamed Layer* 507) [PluginV2IOExt]_output_0: 3ef64102
|
||||||
|
(Unnamed Layer* 508) [PluginV2IOExt]_output_0: 3efa5428
|
||||||
|
|
@ -0,0 +1,77 @@
|
||||||
|
TRT-7103-EntropyCalibration2
|
||||||
|
000_net: 3c010a14
|
||||||
|
001_convolutional: 3d1c8e6f
|
||||||
|
001_convolutional_bn: 3e4974f2
|
||||||
|
001_convolutional_lrelu: 3dc86a5b
|
||||||
|
002_convolutional: 3ece0986
|
||||||
|
002_convolutional_bn: 3e5586a9
|
||||||
|
002_convolutional_lrelu: 3db733ca
|
||||||
|
003_convolutional: 3f0e2de4
|
||||||
|
003_convolutional_bn: 3e60045a
|
||||||
|
003_convolutional_lrelu: 3da01dc1
|
||||||
|
004_route: 3d82b8ef
|
||||||
|
005_convolutional: 3e6609bc
|
||||||
|
005_convolutional_bn: 3e24dc23
|
||||||
|
005_convolutional_lrelu: 3dab644a
|
||||||
|
006_convolutional: 3e9b3825
|
||||||
|
006_convolutional_bn: 3e14e8af
|
||||||
|
006_convolutional_lrelu: 3dab644a
|
||||||
|
007_route: 3dab644a
|
||||||
|
008_convolutional: 3e5af597
|
||||||
|
008_convolutional_bn: 3e6056b7
|
||||||
|
008_convolutional_lrelu: 3da01dc1
|
||||||
|
009_route: 3da01dc1
|
||||||
|
010_maxpool: 3da01dc1
|
||||||
|
011_convolutional: 3f03ea95
|
||||||
|
011_convolutional_bn: 3e06fedb
|
||||||
|
011_convolutional_lrelu: 3d82f2db
|
||||||
|
012_route: 3d48c651
|
||||||
|
013_convolutional: 3e183f49
|
||||||
|
013_convolutional_bn: 3e05719a
|
||||||
|
013_convolutional_lrelu: 3d94d68b
|
||||||
|
014_convolutional: 3e4a5ee5
|
||||||
|
014_convolutional_bn: 3e031d6c
|
||||||
|
014_convolutional_lrelu: 3d94d68b
|
||||||
|
015_route: 3d94d68b
|
||||||
|
016_convolutional: 3e174a7d
|
||||||
|
016_convolutional_bn: 3e332af1
|
||||||
|
016_convolutional_lrelu: 3d82f2db
|
||||||
|
017_route: 3d82f2db
|
||||||
|
018_maxpool: 3d82f2db
|
||||||
|
019_convolutional: 3e6a4db7
|
||||||
|
019_convolutional_bn: 3dfa9047
|
||||||
|
019_convolutional_lrelu: 3d5576c5
|
||||||
|
020_route: 3d21b8b8
|
||||||
|
021_convolutional: 3dbccf7c
|
||||||
|
021_convolutional_bn: 3df2a13a
|
||||||
|
021_convolutional_lrelu: 3d8c2655
|
||||||
|
022_convolutional: 3e30f046
|
||||||
|
022_convolutional_bn: 3e06213a
|
||||||
|
022_convolutional_lrelu: 3d8c2655
|
||||||
|
023_route: 3d8c2655
|
||||||
|
024_convolutional: 3def9521
|
||||||
|
024_convolutional_bn: 3e5bb6dd
|
||||||
|
024_convolutional_lrelu: 3d5cf432
|
||||||
|
025_route: 3d5576c5
|
||||||
|
026_maxpool: 3d5576c5
|
||||||
|
027_convolutional: 3e0fb964
|
||||||
|
027_convolutional_bn: 3d904460
|
||||||
|
027_convolutional_lrelu: 3ce5e15a
|
||||||
|
028_convolutional: 3d2a22a6
|
||||||
|
028_convolutional_bn: 3daa0d77
|
||||||
|
028_convolutional_lrelu: 3cf3a519
|
||||||
|
029_convolutional: 3d8c79cd
|
||||||
|
029_convolutional_bn: 3dc4fed3
|
||||||
|
029_convolutional_lrelu: 3d538d7b
|
||||||
|
030_convolutional: 3e5a4f2e
|
||||||
|
033_convolutional: 3d2151e9
|
||||||
|
033_convolutional_bn: 3da734e6
|
||||||
|
033_convolutional_lrelu: 3d2f6b4e
|
||||||
|
034_upsample: 3d5cf432
|
||||||
|
035_route: 3d5cf432
|
||||||
|
036_convolutional: 3e08d1ff
|
||||||
|
036_convolutional_bn: 3d9e9b27
|
||||||
|
036_convolutional_lrelu: 3d31538c
|
||||||
|
037_convolutional: 3e46fd84
|
||||||
|
(Unnamed Layer* 76) [PluginV2IOExt]_output_0: 3efa468d
|
||||||
|
(Unnamed Layer* 77) [PluginV2IOExt]_output_0: 3ef222c6
|
||||||
|
|
@ -0,0 +1,153 @@
|
||||||
|
"""calibrator.py
|
||||||
|
|
||||||
|
The original code could be found in TensorRT-7.x sample code:
|
||||||
|
"samples/python/int8_caffe_mnist/calibrator.py". I made the
|
||||||
|
modification so that the Calibrator could handle MS-COCO dataset
|
||||||
|
images instead of MNIST.
|
||||||
|
"""
|
||||||
|
|
||||||
|
#
|
||||||
|
# Copyright 1993-2019 NVIDIA Corporation. All rights reserved.
|
||||||
|
#
|
||||||
|
# NOTICE TO LICENSEE:
|
||||||
|
#
|
||||||
|
# This source code and/or documentation ("Licensed Deliverables") are
|
||||||
|
# subject to NVIDIA intellectual property rights under U.S. and
|
||||||
|
# international Copyright laws.
|
||||||
|
#
|
||||||
|
# These Licensed Deliverables contained herein is PROPRIETARY and
|
||||||
|
# CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
||||||
|
# conditions of a form of NVIDIA software license agreement by and
|
||||||
|
# between NVIDIA and Licensee ("License Agreement") or electronically
|
||||||
|
# accepted by Licensee. Notwithstanding any terms or conditions to
|
||||||
|
# the contrary in the License Agreement, reproduction or disclosure
|
||||||
|
# of the Licensed Deliverables to any third party without the express
|
||||||
|
# written consent of NVIDIA is prohibited.
|
||||||
|
#
|
||||||
|
# NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
||||||
|
# LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
||||||
|
# SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
||||||
|
# PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
||||||
|
# NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
||||||
|
# DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
||||||
|
# NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
||||||
|
# NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
||||||
|
# LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
||||||
|
# SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
||||||
|
# DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
||||||
|
# WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
||||||
|
# ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
||||||
|
# OF THESE LICENSED DELIVERABLES.
|
||||||
|
#
|
||||||
|
# U.S. Government End Users. These Licensed Deliverables are a
|
||||||
|
# "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
||||||
|
# 1995), consisting of "commercial computer software" and "commercial
|
||||||
|
# computer software documentation" as such terms are used in 48
|
||||||
|
# C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
||||||
|
# only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
||||||
|
# 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
||||||
|
# U.S. Government End Users acquire the Licensed Deliverables with
|
||||||
|
# only those rights set forth herein.
|
||||||
|
#
|
||||||
|
# Any use of the Licensed Deliverables in individual and commercial
|
||||||
|
# software must include, in the user documentation and internal
|
||||||
|
# comments to the code, the above Disclaimer and U.S. Government End
|
||||||
|
# Users Notice.
|
||||||
|
|
||||||
|
|
||||||
|
import os
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
import pycuda.autoinit
|
||||||
|
import pycuda.driver as cuda
|
||||||
|
import tensorrt as trt
|
||||||
|
|
||||||
|
|
||||||
|
def _preprocess_yolo(img, input_shape):
|
||||||
|
"""Preprocess an image before TRT YOLO inferencing.
|
||||||
|
|
||||||
|
# Args
|
||||||
|
img: uint8 numpy array of shape either (img_h, img_w, 3)
|
||||||
|
or (img_h, img_w)
|
||||||
|
input_shape: a tuple of (H, W)
|
||||||
|
|
||||||
|
# Returns
|
||||||
|
preprocessed img: float32 numpy array of shape (3, H, W)
|
||||||
|
"""
|
||||||
|
if img.ndim == 2:
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
|
||||||
|
img = cv2.resize(img, (input_shape[1], input_shape[0]))
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
||||||
|
img = img.transpose((2, 0, 1)).astype(np.float32)
|
||||||
|
img /= 255.0
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
class YOLOEntropyCalibrator(trt.IInt8EntropyCalibrator2):
|
||||||
|
"""YOLOEntropyCalibrator
|
||||||
|
|
||||||
|
This class implements TensorRT's IInt8EntropyCalibtrator2 interface.
|
||||||
|
It reads all images from the specified directory and generates INT8
|
||||||
|
calibration data for YOLO models accordingly.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, img_dir, net_hw, cache_file, batch_size=1):
|
||||||
|
if not os.path.isdir(img_dir):
|
||||||
|
raise FileNotFoundError('%s does not exist' % img_dir)
|
||||||
|
if len(net_hw) != 2 or net_hw[0] % 32 or net_hw[1] % 32:
|
||||||
|
raise ValueError('bad net shape: %s' % str(net_hw))
|
||||||
|
|
||||||
|
super().__init__() # trt.IInt8EntropyCalibrator2.__init__(self)
|
||||||
|
|
||||||
|
self.img_dir = img_dir
|
||||||
|
self.net_hw = net_hw
|
||||||
|
self.cache_file = cache_file
|
||||||
|
self.batch_size = batch_size
|
||||||
|
self.blob_size = 3 * net_hw[0] * net_hw[1] * np.dtype('float32').itemsize * batch_size
|
||||||
|
|
||||||
|
self.jpgs = [f for f in os.listdir(img_dir) if f.endswith('.jpg')]
|
||||||
|
# The number "500" is NVIDIA's suggestion. See here:
|
||||||
|
# https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#optimizing_int8_c
|
||||||
|
if len(self.jpgs) < 500:
|
||||||
|
print('WARNING: found less than 500 images in %s!' % img_dir)
|
||||||
|
self.current_index = 0
|
||||||
|
|
||||||
|
# Allocate enough memory for a whole batch.
|
||||||
|
self.device_input = cuda.mem_alloc(self.blob_size)
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
del self.device_input # free CUDA memory
|
||||||
|
|
||||||
|
def get_batch_size(self):
|
||||||
|
return self.batch_size
|
||||||
|
|
||||||
|
def get_batch(self, names):
|
||||||
|
if self.current_index + self.batch_size > len(self.jpgs):
|
||||||
|
return None
|
||||||
|
current_batch = int(self.current_index / self.batch_size)
|
||||||
|
|
||||||
|
batch = []
|
||||||
|
for i in range(self.batch_size):
|
||||||
|
img_path = os.path.join(
|
||||||
|
self.img_dir, self.jpgs[self.current_index + i])
|
||||||
|
img = cv2.imread(img_path)
|
||||||
|
assert img is not None, 'failed to read %s' % img_path
|
||||||
|
batch.append(_preprocess_yolo(img, self.net_hw))
|
||||||
|
batch = np.stack(batch)
|
||||||
|
assert batch.nbytes == self.blob_size
|
||||||
|
|
||||||
|
cuda.memcpy_htod(self.device_input, np.ascontiguousarray(batch))
|
||||||
|
self.current_index += self.batch_size
|
||||||
|
return [self.device_input]
|
||||||
|
|
||||||
|
def read_calibration_cache(self):
|
||||||
|
# If there is a cache, use it instead of calibrating again.
|
||||||
|
# Otherwise, implicitly return None.
|
||||||
|
if os.path.exists(self.cache_file):
|
||||||
|
with open(self.cache_file, 'rb') as f:
|
||||||
|
return f.read()
|
||||||
|
|
||||||
|
def write_calibration_cache(self, cache):
|
||||||
|
with open(self.cache_file, 'wb') as f:
|
||||||
|
f.write(cache)
|
||||||
|
|
@ -0,0 +1,108 @@
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
set -e
|
||||||
|
|
||||||
|
# yolov3-tiny
|
||||||
|
wget https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-tiny.cfg -q --show-progress --no-clobber
|
||||||
|
wget https://pjreddie.com/media/files/yolov3-tiny.weights -q --show-progress --no-clobber
|
||||||
|
|
||||||
|
# yolov3
|
||||||
|
wget https://raw.githubusercontent.com/pjreddie/darknet/master/cfg/yolov3.cfg -q --show-progress --no-clobber
|
||||||
|
wget https://pjreddie.com/media/files/yolov3.weights -q --show-progress --no-clobber
|
||||||
|
|
||||||
|
# yolov3-spp
|
||||||
|
wget https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-spp.cfg -q --show-progress --no-clobber
|
||||||
|
wget https://pjreddie.com/media/files/yolov3-spp.weights -q --show-progress --no-clobber
|
||||||
|
|
||||||
|
# yolov4-tiny
|
||||||
|
wget https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-tiny.cfg -q --show-progress --no-clobber
|
||||||
|
wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.weights -q --show-progress --no-clobber
|
||||||
|
|
||||||
|
# yolov4
|
||||||
|
wget https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4.cfg -q --show-progress --no-clobber
|
||||||
|
wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights -q --show-progress --no-clobber
|
||||||
|
|
||||||
|
# yolov4-csp
|
||||||
|
wget https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-csp.cfg -q --show-progress --no-clobber
|
||||||
|
wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-csp.weights -q --show-progress --no-clobber
|
||||||
|
|
||||||
|
# yolov4x-mish
|
||||||
|
wget https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4x-mish.cfg -q --show-progress --no-clobber
|
||||||
|
wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4x-mish.weights -q --show-progress --no-clobber
|
||||||
|
|
||||||
|
# yolov4-p5
|
||||||
|
wget https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-p5.cfg -q --show-progress --no-clobber
|
||||||
|
wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-p5.weights -q --show-progress --no-clobber
|
||||||
|
|
||||||
|
echo
|
||||||
|
echo "Creating yolov3-tiny-288.cfg and yolov3-tiny-288.weights"
|
||||||
|
cat yolov3-tiny.cfg | sed -e '8s/width=416/width=288/' | sed -e '9s/height=416/height=288/' > yolov3-tiny-288.cfg
|
||||||
|
echo >> yolov3-tiny-288.cfg
|
||||||
|
ln -sf yolov3-tiny.weights yolov3-tiny-288.weights
|
||||||
|
echo "Creating yolov3-tiny-416.cfg and yolov3-tiny-416.weights"
|
||||||
|
cp yolov3-tiny.cfg yolov3-tiny-416.cfg
|
||||||
|
echo >> yolov3-tiny-416.cfg
|
||||||
|
ln -sf yolov3-tiny.weights yolov3-tiny-416.weights
|
||||||
|
|
||||||
|
echo "Creating yolov3-288.cfg and yolov3-288.weights"
|
||||||
|
cat yolov3.cfg | sed -e '8s/width=608/width=288/' | sed -e '9s/height=608/height=288/' > yolov3-288.cfg
|
||||||
|
ln -sf yolov3.weights yolov3-288.weights
|
||||||
|
echo "Creating yolov3-416.cfg and yolov3-416.weights"
|
||||||
|
cat yolov3.cfg | sed -e '8s/width=608/width=416/' | sed -e '9s/height=608/height=416/' > yolov3-416.cfg
|
||||||
|
ln -sf yolov3.weights yolov3-416.weights
|
||||||
|
echo "Creating yolov3-608.cfg and yolov3-608.weights"
|
||||||
|
cp yolov3.cfg yolov3-608.cfg
|
||||||
|
ln -sf yolov3.weights yolov3-608.weights
|
||||||
|
|
||||||
|
echo "Creating yolov3-spp-288.cfg and yolov3-spp-288.weights"
|
||||||
|
cat yolov3-spp.cfg | sed -e '8s/width=608/width=288/' | sed -e '9s/height=608/height=288/' > yolov3-spp-288.cfg
|
||||||
|
ln -sf yolov3-spp.weights yolov3-spp-288.weights
|
||||||
|
echo "Creating yolov3-spp-416.cfg and yolov3-spp-416.weights"
|
||||||
|
cat yolov3-spp.cfg | sed -e '8s/width=608/width=416/' | sed -e '9s/height=608/height=416/' > yolov3-spp-416.cfg
|
||||||
|
ln -sf yolov3-spp.weights yolov3-spp-416.weights
|
||||||
|
echo "Creating yolov3-spp-608.cfg and yolov3-spp-608.weights"
|
||||||
|
cp yolov3-spp.cfg yolov3-spp-608.cfg
|
||||||
|
ln -sf yolov3-spp.weights yolov3-spp-608.weights
|
||||||
|
|
||||||
|
echo "Creating yolov4-tiny-288.cfg and yolov4-tiny-288.weights"
|
||||||
|
cat yolov4-tiny.cfg | sed -e '6s/batch=64/batch=1/' | sed -e '8s/width=416/width=288/' | sed -e '9s/height=416/height=288/' > yolov4-tiny-288.cfg
|
||||||
|
echo >> yolov4-tiny-288.cfg
|
||||||
|
ln -sf yolov4-tiny.weights yolov4-tiny-288.weights
|
||||||
|
echo "Creating yolov4-tiny-416.cfg and yolov4-tiny-416.weights"
|
||||||
|
cat yolov4-tiny.cfg | sed -e '6s/batch=64/batch=1/' > yolov4-tiny-416.cfg
|
||||||
|
echo >> yolov4-tiny-416.cfg
|
||||||
|
ln -sf yolov4-tiny.weights yolov4-tiny-416.weights
|
||||||
|
|
||||||
|
echo "Creating yolov4-288.cfg and yolov4-288.weights"
|
||||||
|
cat yolov4.cfg | sed -e '2s/batch=64/batch=1/' | sed -e '7s/width=608/width=288/' | sed -e '8s/height=608/height=288/' > yolov4-288.cfg
|
||||||
|
ln -sf yolov4.weights yolov4-288.weights
|
||||||
|
echo "Creating yolov4-416.cfg and yolov4-416.weights"
|
||||||
|
cat yolov4.cfg | sed -e '2s/batch=64/batch=1/' | sed -e '7s/width=608/width=416/' | sed -e '8s/height=608/height=416/' > yolov4-416.cfg
|
||||||
|
ln -sf yolov4.weights yolov4-416.weights
|
||||||
|
echo "Creating yolov4-608.cfg and yolov4-608.weights"
|
||||||
|
cat yolov4.cfg | sed -e '2s/batch=64/batch=1/' > yolov4-608.cfg
|
||||||
|
ln -sf yolov4.weights yolov4-608.weights
|
||||||
|
|
||||||
|
echo "Creating yolov4-csp-256.cfg and yolov4-csp-256.weights"
|
||||||
|
cat yolov4-csp.cfg | sed -e '6s/batch=64/batch=1/' | sed -e '8s/width=512/width=256/' | sed -e '9s/height=512/height=256/' > yolov4-csp-256.cfg
|
||||||
|
ln -sf yolov4-csp.weights yolov4-csp-256.weights
|
||||||
|
echo "Creating yolov4-csp-512.cfg and yolov4x-csp-512.weights"
|
||||||
|
cat yolov4-csp.cfg | sed -e '6s/batch=64/batch=1/' > yolov4-csp-512.cfg
|
||||||
|
ln -sf yolov4-csp.weights yolov4-csp-512.weights
|
||||||
|
|
||||||
|
echo "Creating yolov4x-mish-320.cfg and yolov4x-mish-320.weights"
|
||||||
|
cat yolov4x-mish.cfg | sed -e '6s/batch=64/batch=1/' | sed -e '8s/width=640/width=320/' | sed -e '9s/height=640/height=320/' > yolov4x-mish-320.cfg
|
||||||
|
ln -sf yolov4x-mish.weights yolov4x-mish-320.weights
|
||||||
|
echo "Creating yolov4x-mish-640.cfg and yolov4x-mish-640.weights"
|
||||||
|
cat yolov4x-mish.cfg | sed -e '6s/batch=64/batch=1/' > yolov4x-mish-640.cfg
|
||||||
|
ln -sf yolov4x-mish.weights yolov4x-mish-640.weights
|
||||||
|
|
||||||
|
echo "Creating yolov4-p5-448.cfg and yolov4-p5-448.weights"
|
||||||
|
cat yolov4-p5.cfg | sed -e '6s/batch=64/batch=1/' | sed -e '8s/width=896/width=448/' | sed -e '9s/height=896/height=448/' > yolov4-p5-448.cfg
|
||||||
|
ln -sf yolov4-p5.weights yolov4-p5-448.weights
|
||||||
|
echo "Creating yolov4-p5-896.cfg and yolov4-p5-896.weights"
|
||||||
|
cat yolov4-p5.cfg | sed -e '6s/batch=64/batch=1/' > yolov4-p5-896.cfg
|
||||||
|
ln -sf yolov4-p5.weights yolov4-p5-896.weights
|
||||||
|
|
||||||
|
echo
|
||||||
|
echo "Done."
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue